




文章目录
MySQL 索引全面解析:类型、作用、失效场景与最佳实践
索引是 MySQL 数据库优化的核心工具,其本质是“有序的数据结构”,通过提前构建数据的查询路径,减少磁盘 IO 开销,从而提升查询效率。但索引并非“越多越好”,而是需要根据实际情况进行设置索引,索引过多有时反而还会降低查询效率。本文将从索引的核心价值、类型定义、使用陷阱等维度,系统梳理 MySQL 索引的关键知识。
一、为什么需要索引?
使用索引的主要目的是、提高数据库查询性能和加快数据检索。具体优势如下:
-
加速数据检索
索引通过排序和指针映射,避免扫描全表。例如,一张 100 万行的用户表,查询“id=10086”的用户,无索引需扫描所有行 直到扫描到为止,有主键索引仅需 3-4 次磁盘 IO(B+ 树结构特性)。 -
减少数据读取量
索引仅存储“索引列+指针”(或主键),体积远小于全表数据。查询时若只需索引列数据(如select name from user where id=1),可直接从索引获取,无需读取完整数据行。 -
优化排序与分组
索引本身是有序的(如 B+ 树索引按列值升序/降序排列)。若查询包含order by或group by,且排序/分组列与索引前缀一致,MySQL 可直接利用索引的有序性,避免额外的filesort操作(磁盘排序)。 -
强制数据完整性
唯一索引(含主键索引)可约束列值唯一性,避免重复数据插入。例如,用户表的“身份证号”列创建唯一索引后,无法插入相同身份证号的记录,保障数据一致性。 -
提升并发性能
高效的索引减少了查询对数据行的锁定时间(查询更快完成,锁释放更早),降低多线程并发访问时的锁竞争,间接提升系统吞吐量。
二、索引的缺点:并非“越多越好”
索引的优势需以“额外成本”为代价来提高速度,滥用索引会导致数据库性能下降,核心缺点如下:
-
占用额外存储空间
索引需独立存储(如 InnoDB 的索引文件.ibd),一张表的多个索引会累积占用大量空间。例如,一张 1GB 的用户表,若创建 3 个组合索引,索引文件可能达到 500MB 以上。 -
增加写操作开销
插入、更新、删除数据时,需同步维护所有相关索引(如插入一行数据,需在 3 个索引中分别新增索引项)。例如,一张有 5 个索引的表,插入操作的耗时可能是无索引表的 3-5 倍。 -
维护成本随数据增长上升
当表数据量增大(如超 1000 万行),索引的“页分裂”“碎片整理”等维护操作会更频繁,导致 CPU 和磁盘 IO 开销增加,甚至需要定期执行OPTIMIZE TABLE优化索引。 -
不适用于高频变更的列
若某列(如“实时在线状态”)每秒更新数十次,对应的索引会频繁重建,不仅消耗资源,还可能因“索引失效”导致查询性能波动。 -
增加查询优化器负担
当表存在多个索引时,MySQL 优化器需计算“使用哪个索引的成本更低”(如全表扫描 vs 索引查找),复杂查询可能因优化器判断失误,选择低效索引。
三、MySQL 核心索引类型详解
MySQL 支持多种索引类型,不同类型适用于不同业务场景,需根据查询需求选择。
1. 全文索引(Fulltext Index)
定义:针对文本内容的特殊索引,支持“分词搜索”“模糊匹配”“相关性排序”,而非普通索引的“精确匹配”。适用于文章、评论、商品描述等长文本场景。
核心特性
- 仅支持
CHAR/VARCHAR/TEXT类型列; - 支持自然语言搜索(如“搜索包含‘MySQL 优化’的文章”),而非简单的字符串匹配;
- InnoDB(MySQL 5.6+)和 MyISAM 支持,但 MyISAM 已过时,优先使用 InnoDB。
操作语法
- 创建索引(建表时):
CREATE TABLE articles ( id INT PRIMARY KEY AUTO_INCREMENT, title VARCHAR(200), content TEXT, -- 全文索引:支持多列组合 FULLTEXT INDEX idx_title_content (title, content) ) ENGINE=InnoDB; - 创建索引(已存在表):
ALTER TABLE articles ADD FULLTEXT INDEX idx_content (content); - 使用索引查询(需用
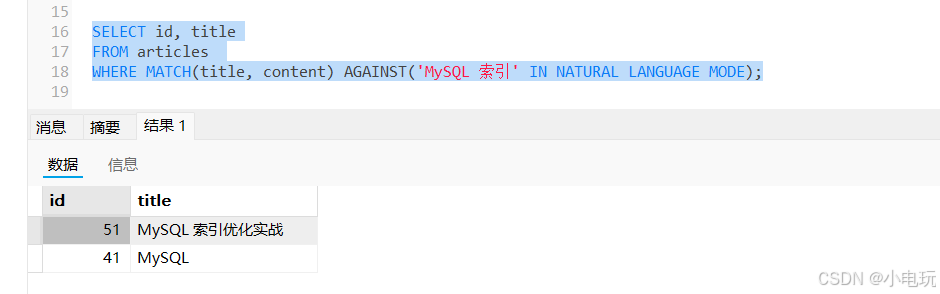
MATCH AGAINST):-- 自然语言搜索:返回含“MySQL 索引”的文章,并按相关性排序 SELECT id, title FROM articles WHERE MATCH(title, content) AGAINST('MySQL 索引' IN NATURAL LANGUAGE MODE);
多个关键词之间用空格分隔,默认表示 “逻辑或”(匹配包含任意一个关键词的记录)如 MySQL ,索引
2. 主键索引(Primary Key Index)
定义:表的“唯一标识”索引,强制列值“非空且唯一”, 一张表只能有一个主键(Primary Key),但主键可以由多个列共同组成(即 “联合主键”)。InnoDB 中,主键索引是“聚集索引”。
核心特性
- 列值不可为 NULL,且不可重复;
- InnoDB 中,主键索引的叶子节点直接存储完整数据行(无需回表);
操作语法
- 建表时创建:
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, -- 主键索引 name VARCHAR(50) NOT NULL, age INT );
注意事项
- 不推荐“复合主键”(多列组合主键),如
(user_id, order_id),会导致关联查询复杂,建议用“单列自增主键+唯一索引”替代; - 若表未显式指定主键,InnoDB 会默认选择“非空唯一索引”作为主键,若无则隐式创建一个隐藏主键(6 字节 RowID)。
3. 唯一索引(Unique Index)
定义:约束列值“唯一”的索引,与主键索引的区别是“允许 NULL 值”(且允许多个 NULL,因 NULL≠NULL)。适用于需唯一约束但允许空值的场景,如“邮箱”“身份证号”。
核心特性
- 列值不可重复,但可含多个 NULL;
- 索引结构与普通索引一致(B+ 树),仅多了唯一性校验;
- 一张表可创建多个唯一索引(如用户表的“身份证号”各建一个唯一索引)。
操作语法
- 建表时创建:
CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, email VARCHAR(100) UNIQUE, -- 唯一索引 phone VARCHAR(20) UNIQUE -- 另一唯一索引 ); - 已存在表添加:
ALTER TABLE users ADD UNIQUE INDEX idx_phone (phone);

4. 覆盖索引(Covering Index)
定义:并非独立索引类型,而是“索引的使用效果”——当索引包含“查询所需的所有列”(where 条件列 + select 返回列)时,无需访问数据行,直接从索引获取结果,避免“回表查询”。
核心优势
- 彻底避免回表,减少磁盘 IO;
- 无需解析完整数据行,降低 CPU 开销。
示例(如何利用覆盖索引)
假设用户表有索引 idx_name_age (name, age),查询如下:
-- 覆盖索引生效:select 列(name, age)+ where 列(name)均在索引中
SELECT name, age FROM users WHERE name = '张三';
-- 覆盖索引失效:select 列(address)不在索引中,需回表
SELECT name, address FROM users WHERE name = '张三';
5. 组合索引(Composite Index)
定义:包含多个列的索引(如 idx_a_b_c (a, b, c)),适用于“多列联合查询”的场景(如 where a=1 and b=2)。核心遵循“最左前缀原则”。
核心特性
- 索引列顺序决定查询能否利用索引:仅“从左到右匹配前缀”的查询能利用索引;
- 组合索引的选择性(区分度)更高,比单列索引更易定位少量数据(如
where a=1 and b=2比where a=1筛选结果更少)。
操作语法
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键(唯一标识订单)
a INT, -- 前缀列,用于最左前缀匹配
b INT, -- 组合索引的第二列
c INT, -- 组合索引的第三列
product_name VARCHAR(100), -- 商品名称(非索引列,用于区分数据)
-- 创建组合索引:a 为前缀,b、c 为后续列
INDEX idx_a_b_c (a, b, c)
) ENGINE=InnoDB;
INSERT INTO orders (a, b, c, product_name) VALUES
-- a=1 的系列数据(用于测试 a=1 的查询)
(1, 2, 3, '商品A1'),
(1, 2, 4, '商品A2'),
(1, 3, 5, '商品A3'),
(1, 3, 6, '商品A4'),
(1, 4, 7, '商品A5'),
-- a=2 的系列数据(用于测试 a=2 的查询)
(2, 1, 2, '商品B1'),
(2, 1, 3, '商品B2'),
(2, 2, 4, '商品B3'),
(2, 3, 5, '商品B4'),
-- a=3 的系列数据(用于测试范围查询 a>2)
(3, 2, 1, '商品C1'),
(3, 3, 2, '商品C2'),
(4, 1, 3, '商品C3');
-- 1. 匹配前缀 a(仅 a 生效)
EXPLAIN SELECT * FROM orders WHERE a = 1;
-- 2. 匹配前缀 a+b(a 和 b 生效)
EXPLAIN SELECT * FROM orders WHERE a = 1 AND b = 2;
-- 3. 匹配完整前缀 a+b+c(全部生效)
EXPLAIN SELECT * FROM orders WHERE a = 1 AND b = 2 AND c = 3;
-- 4. a 等值 + b 范围(a 和 b 生效,c 失效)
EXPLAIN SELECT * FROM orders WHERE a = 1 AND b > 2 AND c = 5;
-- 1. 未匹配最左前缀 a(仅 b 查询)
EXPLAIN SELECT * FROM orders WHERE b = 2;
-- 2. a 范围查询,后续 c 失效
EXPLAIN SELECT * FROM orders WHERE a > 1 AND c = 3;
-- 3. 未匹配前缀 a(仅 b 和 c 查询)
EXPLAIN SELECT * FROM orders WHERE b = 2 AND c = 3;
最左前缀原则示例(关键!)
索引 idx_a_b_c 仅对以下查询生效(部分或全部):
where a=1(匹配前缀 a);where a=1 and b=2(匹配前缀 a+b);where a=1 and b=2 and c=3(匹配完整前缀 a+b+c);where a=1 and b>2 and c=3(a、b 列生效,c 列因 b 是范围条件失效)。
以下查询无法利用该索引:
where b=2(未匹配最左前缀 a);where a>1 and c=3(a 是范围条件,c 列失效);where b=2 and c=3(未匹配前缀 a)。
6. 普通索引(Normal Index)
定义:最基础的索引类型,仅加速查询,不约束数据(允许重复、允许 NULL)。适用于“高频查询但无需唯一约束”的列。
核心特性
- 无唯一性和非空约束;
- 索引结构为 B+ 树,查询时需“回表”(除非是覆盖索引);
- 一张表可创建多个普通索引,但需控制数量(避免写操作开销过大)。
操作语法
- 建表时创建:
CREATE TABLE goods ( id INT AUTO_INCREMENT PRIMARY KEY, category_id INT, name VARCHAR(100), -- 普通索引 INDEX idx_category (category_id) ); - 已存在表添加:
ALTER TABLE goods ADD INDEX idx_name (name);
四、什么是回表查询?(InnoDB 重点)
回表查询是 InnoDB 中因“索引结构差异”导致的特殊操作,核心与“聚集索引”和“非聚集索引”的区别有关:
- 聚集索引:仅主键索引是聚集索引,叶子节点存储完整数据行;
- 非聚集索引:普通索引、唯一索引、组合索引均为非聚集索引,叶子节点存储“主键和值”(而非完整数据行)。
回表触发场景
当使用非聚集索引查询,且 select 列包含“非索引列+非主键列”时,需分两步查询:
- 从非聚集索引找到“主键值”;
- 用主键值查询“聚集索引”,获取完整数据行(即“回表”)。
示例
用户表 users(id主键, name, age, address),有普通索引 idx_name(name):
-- 触发回表:select 列(address)不在 idx_name 中,且非主键
SELECT id, name, address FROM users WHERE name = '张三';
-- 不触发回表:select 列(id, name)均在 idx_name 中(id 是主键,非聚集索引默认包含)
SELECT id, name FROM users WHERE name = '张三';
如何避免回表?
- 利用覆盖索引:将查询所需的非主键列加入索引(如将
idx_name改为组合索引idx_name_address(name, address)); - 仅查询“索引列+主键列”:避免
select *,明确指定需要的列。
五、索引失效场景:9 个高频陷阱(附案例)
索引失效是 MySQL 性能优化的常见坑,本质是“查询条件不符合索引结构逻辑,导致优化器放弃使用索引”。以下是 9 个高频场景:
1. 组合索引不满足“最左前缀”
案例:组合索引 idx_a_b_c(a, b, c),查询 where b=2 and c=3。
原因:未匹配最左前缀 a,索引无法定位数据范围。
解决:若高频查询 b 和 c,需单独创建索引 idx_b_c。
2. 索引列参与函数/算术计算
案例:索引列 id,查询 where id+1=10087 或 where SUBSTR(name, 1, 1)='张'。
原因:函数/计算会改变索引列的原始值,导致优化器无法匹配索引。
解决:将计算逻辑转移到“值”上(如 where id=10087-1),或用“函数索引”(MySQL 8.0+ 支持,如 INDEX idx_substr_name (SUBSTR(name, 1, 1)))。
3. 索引列与查询值类型不匹配(隐式转换)
案例:索引列 phone 是 VARCHAR 类型,查询 where phone=13800138000(值是整数)。
原因:MySQL 会隐式转换类型(phone=CAST(13800138000 AS CHAR)),破坏索引结构。
解决:查询值加引号,保持类型一致(where phone='13800138000')。
4. LIKE 模糊查询以“%”开头
案例:索引列 name,查询 where name like '%三'。
原因:% 开头的模糊查询无法利用索引的有序性(无法确定查询范围),只能全表扫描。
解决:若需前缀模糊,用 like '张%'(可利用索引);若需后缀/全模糊,用全文索引。
5. OR 连接的条件包含“非索引列”
案例:索引列 id 和 name,查询 where id=1 or address='北京'(address 无索引)。
原因:OR 逻辑要求“所有条件都能通过索引定位”,若有一个条件无索引,需全表扫描所有行判断是否满足任一条件。
解决:要么给 address 建索引,要么拆分为两个查询(where id=1 和 where address='北京')再用 `UN
6. 用 NOT IN/!=/<> 导致索引失效(视情况而定)
案例:索引列 status(存储订单状态,可选值为1-5),查询 where status NOT IN (1, 2) 或 where status != 1。
原因:NOT IN/!= 本质是“排除特定值”,优化器会判断符合条件的记录占比——若不满足条件的记录占比极高(如 status 中90%是1,查询 status != 1 仅返回10%数据),可能用索引;若占比低(如 status 分布均匀,NOT IN (1,2) 返回60%数据),索引定位+回表的成本高于全表扫描,会放弃索引。
解决:优先用 IN 替代 NOT IN(如用 where status IN (3,4,5) 替代 NOT IN (1,2));若必须用排除逻辑,可通过业务限制缩小结果范围,或给索引列加“非排除值”的过滤条件。
7. 联合索引中,前面列用范围查询(>, <, between),后面列失效
案例:组合索引 idx_user_age_city(age, city, register_time),查询 where age > 25 and city = '上海' and register_time > '2024-01-01'。
原因:联合索引的有序性基于“前缀列优先”——age 用范围查询(age > 25)时,age 的值是无序的区间,后续 city 和 register_time 无法依托 age 的有序性定位,仅 age 列的索引生效,city 和 register_time 的索引部分完全失效。
解决:根据查询频率调整索引顺序,若 city 是等值查询、age 是范围查询,可重构索引为 idx_user_city_age_register(city, age, register_time),让等值查询的列优先匹配,最大化利用索引;或拆分查询,先通过 age 范围过滤数据,再在结果中匹配 city。
8. IS NULL/IS NOT NULL 可能导致索引失效
案例:索引列 email(部分用户未填写,存储为 NULL),查询 where email IS NULL 或 where email IS NOT NULL。
原因:MySQL 索引默认不主动存储 NULL 值的位置(或对 NULL 的索引逻辑特殊),优化器会根据 NULL 值占比判断成本——若 email IS NULL 的记录占比极高(如80%用户未填),全表扫描更高效;若占比极低(如仅5%),则会使用索引定位 NULL 记录。
解决:避免用 NULL 存储“无值”场景(如用空字符串 '' 替代 NULL,空字符串可正常被索引匹配);若必须用 NULL,可通过业务逻辑提前过滤(如仅查询“已验证邮箱用户”,规避 IS NOT NULL),或在索引中包含关联列(如 idx_email_status(email, status)),缩小查询范围。
9. 优化器认为“全表扫描比索引更快”
案例:索引列 age,表中仅500行数据(存储测试用户信息),查询 where age = 20。
原因:索引的使用需要额外开销——遍历索引树找到对应主键,再回表(非聚集索引)获取完整数据;当表数据量极小时(通常几千行以内),全表扫描可直接一次性读取所有数据,无需额外的索引遍历和回表步骤,优化器会主动放弃索引,选择成本更低的全表扫描。
解决:此场景无需干预,属于优化器的“智能选择”——当表数据量增长(如超过1万行),优化器会自动切换为索引查询;若需强制使用索引(仅测试场景),可加 FORCE INDEX(如 SELECT * FROM users FORCE INDEX (idx_age) WHERE age = 20),但生产环境不推荐强制干预优化器。
六、MySQL优化
我理解的 SQL 优化,核心是让 SQL 用最少的资源(CPU、I/O)最快返回结果,避免慢查询拖垮数据库性能,影响业务响应。优化的前提是先找到问题,再针对性解决,不能盲目加索引或改语句。
一、第一步:如何发现慢SQL?
“首先得定位问题,我通常会用这两种方式:
-
慢查询日志:开启数据库的慢查询日志(比如MySQL的
slow_query_log),设置阈值(比如1秒),把执行超时的SQL记录下来,这样就能知道哪些SQL拖慢了性能。

-
执行计划分析:对可疑的SQL用
EXPLAIN分析,重点看type(是否全表扫描)、key(是否用了索引)、rows(扫描行数)和Extra(有没有文件排序、临时表这些低效操作)。比如type=ALL就说明全表扫描,肯定要优化。”



















 2133
2133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











