




Kafka
1、Kafka简介
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。既然是消息队列,那么Kafka也就拥有消息队列的相应的特性了。
1.1 消息队列的好处
我们可以简单理解消息队列就是将需要传输的数据存放在队列中
-
解耦合
- 耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能
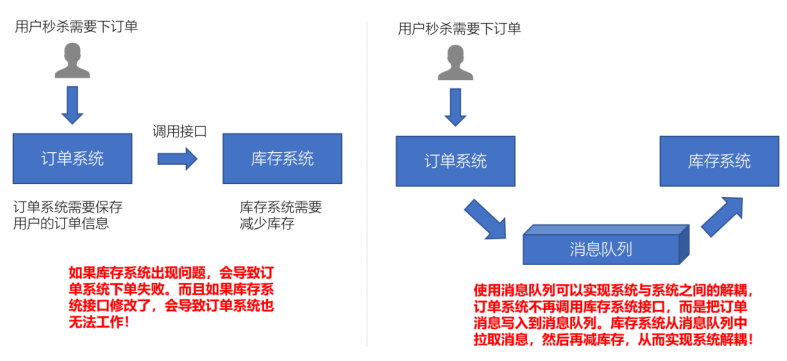
- 耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能
-
异步处理
- 异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可
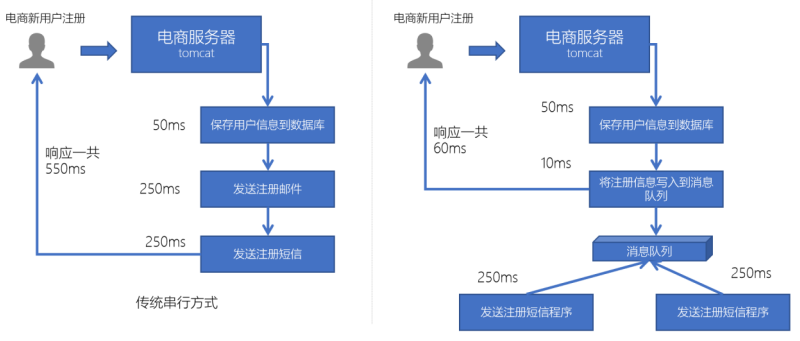
- 异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可
-
流量削峰
- 高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力
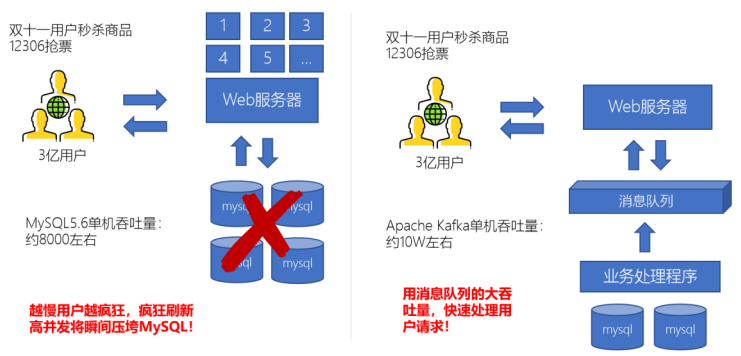
- 高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力
-
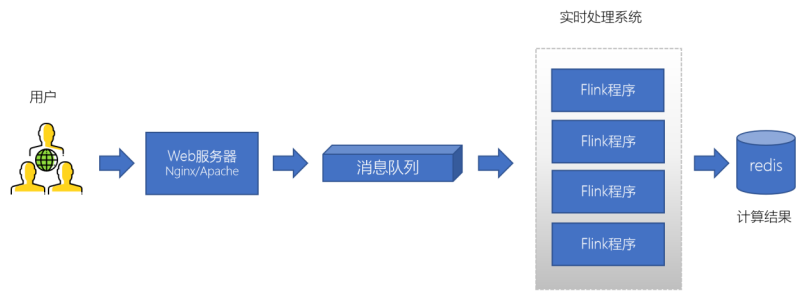
日志处理(大数据领域常见)
1.2 Kafka消费模式
Kafka的消费模式主要有两种:一种是一对一的消费,也即点对点的通信,即一个发送一个接收。第二种为一对多的消费,即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费。
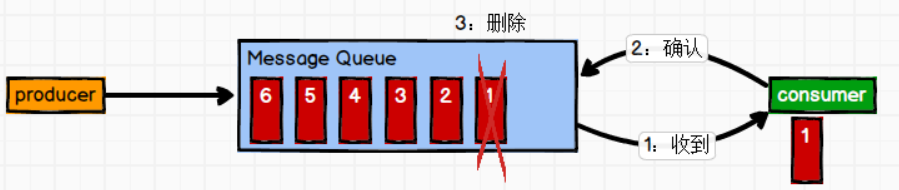
点对点(一对一)
点对点模式特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
消息生产者发布消息到Queue队列中,通知消费者从队列中拉取消息进行消费。消息被消费之后则删除,Queue支持多个消费者,但对于一条消息而言,只有一个消费者可以消费,即一条消息只能被一个消费者消费。
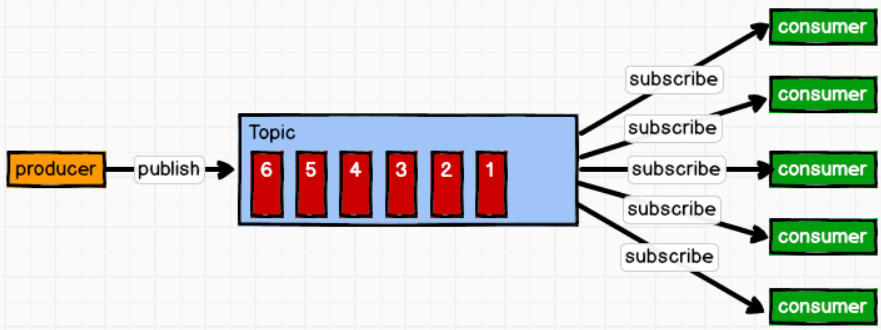
发布/订阅模式(一对多)
发布/订阅模式特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
这种模式也称为发布/订阅模式,即利用Topic存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清除,Kafka会默认保留一段时间,然后再删除。
1.3 Kafka的基础概念
Kafka像其他Mq一样,也有自己的基础架构,主要存在生产者Producer、Kafka集群Broker、消费者Consumer、注册消息Zookeeper
- Producer:消息生产者,向Kafka中发布消息的角色
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端
- Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
一个消费者组中,一个分区只能由一个消费者消费,一个消费者可以消费多个分区
当多个消费者中的 Group Id 的值一致时,这些消费者就组成消费者组 - Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(在一个分区内是有序,不能保证全局有序)
- Replication:副本,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader
- offset:偏移量。相对消费者、partition来说,可以通过offset来拉取数据
上述一个Topic会产生多个分区Partition,分区中分为Leader和Follower,消息一般发送到Leader,Follower通过数据的同步与Leader保持同步,消费的话也是在Leader中发生消费,如果多个消费者,则分别消费Leader和各个Follower中的消息,当Leader发生故障的时候,某个Follower会成为主节点,此时会对齐消息的偏移量
1.4 应用场景及对比
我们通常将Apache Kafka用在两类程序:
- 建立实时数据管道,以可靠地在系统或应用程序之间获取数据
- 构建实时流应用程序,以转换或响应数据流
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅 | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 首次部署难度 | - | 低 | 中 | 高 |
2、Linux搭建集群、Kafka Tools
2.1 启动
-
将Kafka的安装包上传到虚拟机,并解压
tar -zxvf kafka_2.12-3.0.0.tgz -C/opt/module/ # 修改解压后的文件名称 mv kafka_2.12-3.0.0/ kafka -
进入到/opt/module/kafka 目录,修改配置文件
cd config/ vim server.properties # 指定broker的id # 指定Kafka数据的位置 # 配置zk的三个节点 -
输入以下内容
#broker 的全局唯一编号,不能重复,只能是数字。 broker.id=0 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理) zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/ka fka -
将安装好的 kafka 复制到另外两台服务器
cd /opt/module scp -r kafka_2.12-2.4.1/ node2.itcast.cn:$PWD scp -r kafka_2.12-2.4.1/ node3.itcast.cn:$PWD 修改另外两个节点的broker.id分别为1和2 ---------node2.itcast.cn-------------- cd /export/server/kafka_2.12-2.4.1/config vim erver.properties broker.id=1 --------node3.itcast.cn-------------- cd /export/server/kafka_2.12-2.4.1/config vim server.properties broker.id=2 -
配置KAFKA_HOME环境变量
# vim /etc/profile sudo vim /etc/profile.d/my_env.sh # 增加如下内容: #KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin # 刷新一下环境变量 source /etc/profile # 分发到各个节点 scp /etc/profile node2.itcast.cn:$PWD scp /etc/profile node3.itcast.cn:$PWD # 每个节点加载环境变量 source /etc/profile -
启动服务器
# 先启动 Zookeeper 集群,然后启动 Kafka nohup bin/zookeeper-server-start.sh config/zookeeper.properties & # 启动Kafka cd /opt/module/kafka # nohup bin/kafka-server-start.sh config/server.properties & bin/kafka-server-start.sh -daemon config/server.properties # 测试Kafka集群是否启动成功 bin/kafka-topics.sh --bootstrap-server node1.itcast.cn:9092 --list -
关闭服务器
bin/kafka-server-stop.sh
Kafka集群是必须要有ZooKeeper的
注意:
- 每一个Kafka的节点都需要修改broker.id(每个节点的标识,不能重复)
- log.dir数据存储目录需要配置
2.2 Kafka一键启动 / 关闭脚本
为了方便将来进行一键启动、关闭Kafka,我们可以编写一个shell脚本来操作
- 在节点1中创建 /export/onekey 目录
cd /export/onekey - 准备slave配置文件,用于保存要启动哪几个节点上的kafka
node1.itcast.cn node2.itcast.cn node3.itcast.cn - 编写start-kafka.sh脚本
vim start-kafka.sh cat /export/onekey/slave | while read line do { echo $line ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & " }& wait done - 编写stop-kafka.sh脚本
vim stop-kafka.sh cat /export/onekey/slave | while read line do { echo $line ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9" }& wait done - 给start-kafka.sh、stop-kafka.sh配置执行权限
chmod u+x start-kafka.sh chmod u+x stop-kafka.sh - 执行一键启动、一键关闭
./start-kafka.sh ./stop-kafka.sh
2.3 基础操作
# 创建topic名称为first,3个分区,1个副本
./kafka-topics.sh --zookeeper 192.168.233.129:12181 --create --topic first --replication-factor 1 --partitions 3
# 查看first此topic信息
./kafka-topics.sh --zookeeper 192.168.233.129:12181 --describe --topic first
Topic: first PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: first Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: first Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: first Partition: 2 Leader: 1 Replicas: 1 Isr: 1
# 调用生产者生产消息
./kafka-console-producer.sh --broker-list 192.168.233.129:19092,192.168.233.129:19093,192.168.233.129:19094 --topic first
# 调用消费者消费消息,from-beginning表示读取全部的消息
./kafka-console-consumer.sh --bootstrap-server 192.168.233.129:19092,192.168.233.129:19093,192.168.233.129:19094 --topic first --from-beginning
主题命令topic
查看操作主题命令参数
bin/kafka-topics.sh

# 创建名为test的主题
bin/kafka-topics.sh --create --bootstrap-server node1.itcast.cn:9092 --create --partitions 1 --replication-factor 3 --topic test
说明:
--topic :定义 topic 名
--replication-factor :定义副本数
--partitions :定义分区数
修改分区数(注意:分区数只能增加,不能减少)
# 修改分区数
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic test --partitions 3
# 查看目前Kafka中的主题
bin/kafka-topics.sh --list --bootstrap-server node1.itcast.cn:9092 --list
# 查看 test 主题详情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic test
生产者命令行操作
查看操作生产者命令参数
bin/kafka-console-producer.sh

发送信息
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic test
使用Kafka内置的测试程序,生产一些消息到Kafka的test主题中
bin/kafka-console-producer.sh --broker-list node1.itcast.cn:9092 --topic test
消费者命令行操作
查看操作消费者命令参数
bin/kafka-console-consumer.sh
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| –topic <String: topic> | 操作的 topic 名称。 |
| –from-beginning | 从头开始消费。 |
| –group <String: consumer group id> | 指定消费者组名称。 |
消费指定主题中的数据
把主题中所有的数据都读取出来(包括历史数据)
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic test --from-beginning
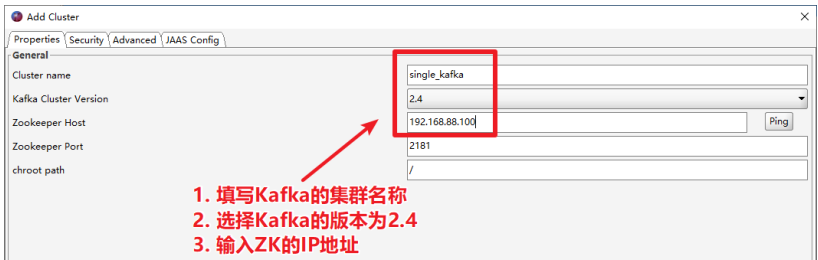
2.4 使用Kafka Tools操作Kafka
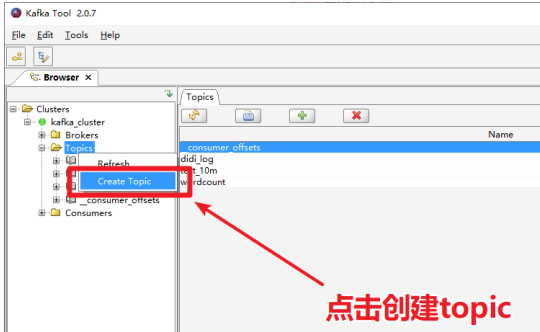
3、Kafka生产者幂等性与事务
Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败
Kafka生产者幂等性
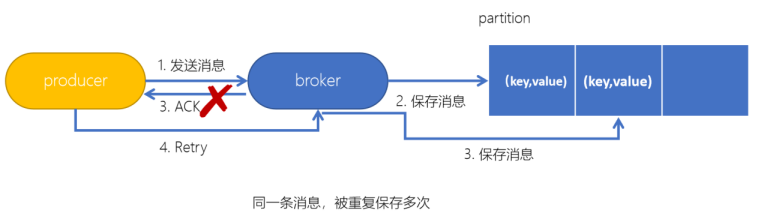 在生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果Kafka不具备幂等性的,就有可能会在partition中保存多条一模一样的消息
在生产者生产消息时,如果出现retry时,有可能会一条消息被发送了多次,如果Kafka不具备幂等性的,就有可能会在partition中保存多条一模一样的消息
原理
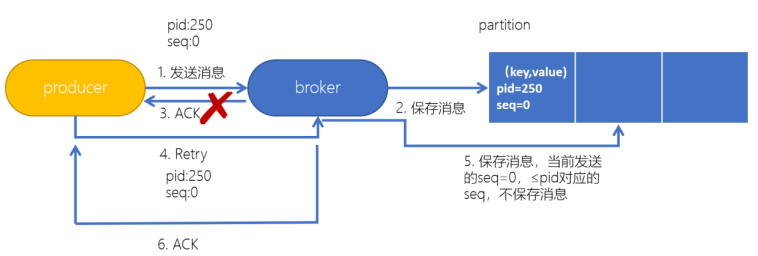
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID( Producer ID):每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number
-
生产者消息重复问题
- Kafka生产者生产消息到 partition,如果直接发送消息,kafka 会将消息保存到分区中,但 Kafka会返回一个ack给生产者,表示当前操作是否成功,是否已经保存了这条消息。如果ack响应的过程失败了,此时生产者会重试,继续发送没有发送成功的消息,Kafka又会保存一条一模一样的消息
-
在 Kafka 中可以开启幂等性
- 当Kafka的生产者生产消息时,会增加一个pid(生产者的唯一编号)和sequence number(针对消息的一个递增序列)
- 发送消息,会连着pid和sequence number一块发送
- kafka接收到消息,会将消息和pid、sequence number一并保存下来
- 如果ack响应失败,生产者重试,再次发送消息时,Kafka会根据pid、sequence number是否需要再保存一条消息
- 判断条件:生产者发送过来的sequence number 是否小于等于 partition中消息对应的sequence
4、分区和 ACK 副本机制
分区的原因
- 方便在集群中扩展:每个partition通过调整以适应它所在的机器,而一个Topic又可以有多个partition组成,因此整个集群可以适应适合的数据
- 可以提高并发:以Partition为单位进行读写。类似于多路。
4.1 生产者分区写入策略
生产者写入消息到 topic,Kafka将依据不同的策略将数据分配到不同的分区中
- 轮询分区策略
- 随机分区策略
- 按key分区分配策略
- 自定义分区策略
轮询分区(默认):
- 默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区
- 如果在生产消息时,key为null,则使用轮询算法均衡地分配分区
随机分区(不用):
随机策略,每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区。但后续轮询策略表现更佳,所以基本上很少会使用随机策略
按key分区分配:
按key分配策略,有可能会出现「数据倾斜」,例如:某个key包含了大量的数据,因为key值一样,所有所有的数据将都分配到一个分区中,造成该分区的消息数量远大于其他的分区
乱序问题:
- 在Kafka中生产者是有写入策略,如果topic有多个分区,就会将数据分散在不同的partition中存储
- 当partition数量大于1的时候,数据(消息)会打散分布在不同的partition中
轮询策略、随机策略都会导致一个问题,生产到 Kafka 中的数据是乱序存储的- 按 key 分区可以一定程度上实现数据有序存储——也就是局部有序,但这又可能会导致数据倾斜
- 如果只有一个分区,消息是有序的
自定义分区代码实现
实现步骤:
(1)定义类实现 Partitioner 接口
(2)重写 partition() 方法
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* 1. 实现接口 Partitioner
* 2. 实现 3 个方法:partition,close,configure
* 3. 编写 partition 方法,返回分区号
*/
public class MyPartitioner implements Partitioner {
/**
* 返回信息对应的分区
* @param topic 主题
* @param key 消息的 key
* @param keyBytes 消息的 key 序列化后的字节数组
* @param value 消息的 value
* @param valueBytes 消息的 value 序列化后的字节数组
* @param cluster 集群元数据可以查看分区信息
* @return
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取消息
String msgValue = value.toString();
// 创建 partition
int partition;
// 判断消息是否包含 atguigu
if (msgValue.contains("atguigu")){
partition = 0;
}else {
partition = 1;
}
// 返回分区号
return partition;
}
// 关闭资源
@Override
public void close() {
}
// 配置方法
@Override
public void configure(Map<String, ?> configs) {
}
}
(3)使用分区器的方法,在生产者的配置中添加分区器参数
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallbackPartitions {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 添加自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atguigu.kafka.producer.MyPartitioner");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e == null){
System.out.println(" 主题: " + metadata.topic() + "->" + "分区:" + metadata.partition());
}else {
e.printStackTrace();
}
}
});
}
kafkaProducer.close();
}
}
4.2 消费者分区分配策略
消费者组Rebalance机制
Kafka中的Rebalance称之为再均衡
在某些情况下,消费者组中的消费者消费的分区会产生变化,会导致消费者分配不均匀(例如:有两个消费者消费3个,因为某个partition崩溃了,还有一个消费者当前没有分区要削峰),Kafka Consumer Group就会启用 Rebalance 机制,重新平衡这个Consumer Group内的消费者消费的分区分配
触发的时机:
- 消费者组中消费者数量发生变化
- 某个消费者crash
- 新增消费者
- 订阅的 topic 的数量发生变化
- 某个topic被删除
- 订阅的topic分区 partition 的数量发生变化
- 删除partition
- 新增partition
不良影响:
发生 rebalance,所有的 consumer 将不再工作,共同来参与再均衡,直到每个消费者都已经被成功分配所需要消费的分区为止(rebalance结束)
消费者分区分配
分区分配策略:保障每个消费者尽量能够均衡地消费分区的数据,不能出现某个消费者消费分区的数量特别多,某个消费者消费的分区特别少
-
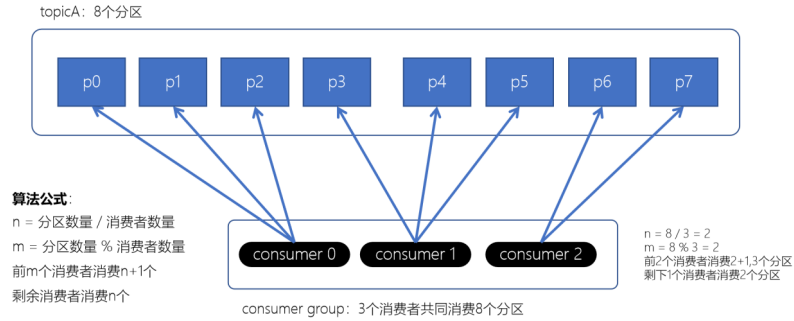
**Range分配策略(范围分配策略):**Kafka默认的分配策略
- n:分区的数量 / 消费者数量
- m:分区的数量 % 消费者数量
- 前m个消费者消费n+1个分区
- 剩余的消费者消费n个分区
-
RoundRobin分配策略(轮询分配策略)
- 消费者挨个分配消费的分区
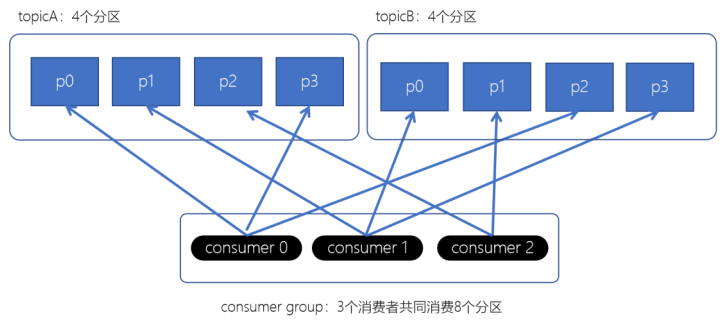
- 消费者挨个分配消费的分区
-
Striky粘性分配策略
- 在没有发生rebalance跟轮询分配策略是一致的
- 发生了rebalance,轮询分配策略,重新走一遍轮询分配的过程。而粘性会保证跟上一次的尽量一致,只是将新的需要分配的分区,均匀的分配到现有可用的消费者中即可
- 减少上下文的切换
4.3 副本机制(生产者ACK机制)
producer是不断地往Kafka中写入数据,写入数据会有一个返回结果,表示是否写入成功。这里对应有一个ACKs的配置
producer返ack,0无落盘直接返,1只leader落盘然后返,-1全部落盘然后返
-
acks = 0:生产者只管写入,不管是否写入成功,可能会数据丢失。性能是最好的
broker接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据 -
acks = 1:生产者会等到 leader分区写入成功后,返回成功,接着发送下一条
如果在follower同步成功之前leader故障,那么将丢失数据 (只是leader落盘) -
acks = -1/all:确保消息写入到 leader分区、还确保消息写入到对应副本都成功后,接着发送下一条,性能是最差的
但是如果在 follower 同步完成后,broker 发送ack之前,如果leader发生故障,会造成数据重复。(这里的数据重复是因为没有收到,所以继续重发导致的数据重复)
根据业务情况来选择ack机制,是要求性能最高,一部分数据丢失影响不大,可以选择0/1。如果要求数据一定不能丢失,就得配置为-1/all。
分区中是有leader和follower的概念,为了确保消费者消费的数据是一致的,只能从分区leader去读写消息,follower做的事情就是同步数据,Backup。
5、监控工具Kafka-eagle
Kafka-Eagle 的安装依赖于 MySQL,MySQL 主要用来存储可视化展示的数据
MySQL 环境准备
Kafka 环境准备
关闭 Kafka 集群
修改 /opt/module/kafka/bin/kafka-server-start.sh 命令中
vim bin/kafka-server-start.sh
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -
XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -
XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -
XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
注意:修改之后在启动 Kafka 之前要分发之其他节点
Kafka-Eagle 安装
官网
官网:https://www.kafka-eagle.org/
1)上传压缩包 kafka-eagle-bin-2.0.8.tar.gz 到集群 /opt/software 目录
2) 解压到本地
tar -zxvf kafka-eagle-bin-2.0.8.tar.gz
3)进入刚才解压的目录
ll
4)将 efak-web-2.0.8-bin.tar.gz 解压至 /opt/module
tar -zxvf efak-web-2.0.8-bin.tar.gz -C /opt/module/
5)修改名称
mv efak-web-2.0.8/ efak
6)修改配置文件 /opt/module/efak/conf/system-config.properties
vim system-config.properties
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.'
instead
######################################
efak.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
######################################
# zookeeper enable acl
######################################
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
cluster1.zk.acl.username=test
cluster1.zk.acl.password=test123
######################################
# broker size online list
######################################
cluster1.efak.broker.size=20
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=32
######################################
# EFAK webui port
######################################
efak.webui.port=8048
######################################
# kafka jmx acl and ssl authenticate
######################################
cluster1.efak.jmx.acl=false
cluster1.efak.jmx.user=keadmin
cluster1.efak.jmx.password=keadmin123
cluster1.efak.jmx.ssl=false
cluster1.efak.jmx.truststore.location=/data/ssl/certificates/kafka.truststor
e
cluster1.efak.jmx.truststore.password=ke123456
######################################
# kafka offset storage
######################################
# offset 保存在 kafka
cluster1.efak.offset.storage=kafka
######################################
# kafka jmx uri
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
######################################
# kafka metrics, 15 days by default
######################################
efak.metrics.charts=true
efak.metrics.retain=15
######################################
# kafka sql topic records max
######################################
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
######################################
# delete kafka topic token
######################################
efak.topic.token=keadmin
######################################
# kafka sasl authenticate
######################################
cluster1.efak.sasl.enable=false
cluster1.efak.sasl.protocol=SASL_PLAINTEXT
cluster1.efak.sasl.mechanism=SCRAM-SHA-256
cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramL
oginModule required username="kafka" password="kafka-eagle";
cluster1.efak.sasl.client.id=
cluster1.efak.blacklist.topics=
cluster1.efak.sasl.cgroup.enable=false
cluster1.efak.sasl.cgroup.topics=
cluster2.efak.sasl.enable=false
cluster2.efak.sasl.protocol=SASL_PLAINTEXT
cluster2.efak.sasl.mechanism=PLAIN
cluster2.efak.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainL
oginModule required username="kafka" password="kafka-eagle";
cluster2.efak.sasl.client.id=
cluster2.efak.blacklist.topics=
cluster2.efak.sasl.cgroup.enable=false
cluster2.efak.sasl.cgroup.topics=
######################################
# kafka ssl authenticate
######################################
cluster3.efak.ssl.enable=false
cluster3.efak.ssl.protocol=SSL
cluster3.efak.ssl.truststore.location=
cluster3.efak.ssl.truststore.password=
cluster3.efak.ssl.keystore.location=
cluster3.efak.ssl.keystore.password=
cluster3.efak.ssl.key.password=
cluster3.efak.ssl.endpoint.identification.algorithm=https
cluster3.efak.blacklist.topics=
cluster3.efak.ssl.cgroup.enable=false
cluster3.efak.ssl.cgroup.topics=
######################################
# kafka sqlite jdbc driver address
######################################
# 配置 mysql 连接
efak.driver=com.mysql.jdbc.Driver
efak.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UT
F-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=000000
######################################
# kafka mysql jdbc driver address
######################################
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=U
TF-8&zeroDateTimeBehavior=convertToNull
#efak.username=root
#efak.password=123456
7)添加环境变量
vim /etc/profile.d/my_env.sh
# kafkaEFAK
export KE_HOME=/opt/module/efak
export PATH=$PATH:$KE_HOME/bin
注意刷新
source /etc/profile
8)启动
注意:启动之前需要先启动 ZK 以及 KAFKA
启动 efak
bin/ke.sh start
停止 efak
bin/ke.sh stop
另一个安装步骤
开启 Kafka JMX 端口
在启动Kafka的脚本前,添加:
cd ${KAFKA_HOME}
export JMX_PORT=9988
nohup bin/kafka-server-start.sh config/server.properties &
安装Kafka-Eagle
-
安装JDK,并配置好JAVA_HOME
-
将kafka_eagle上传,并解压到 /export/server 目录中
cd cd /export/software/ tar -xvzf kafka-eagle-bin-1.4.6.tar.gz -C ../server/ cd /export/server/kafka-eagle-bin-1.4.6/ tar -xvzf kafka-eagle-web-1.4.6-bin.tar.gz cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6 -
配置 kafka_eagle 环境变量
vim /etc/profile export KE_HOME=/export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6 export PATH=$PATH:$KE_HOME/bin source /etc/profile -
配置 kafka_eagle
使用vi打开conf目录下的 system-config.propertiesvim conf/system-config.properties # 修改第4行,配置kafka集群别名 kafka.eagle.zk.cluster.alias=cluster1 # 修改第5行,配置ZK集群地址 cluster1.zk.list=node1.itcast.cn:2181,node2.itcast.cn:2181,node3.itcast.cn:2181 # 注释第6行 #cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181 # 修改第32行,打开图标统计 kafka.eagle.metrics.charts=true kafka.eagle.metrics.retain=30 # 注释第69行,取消sqlite数据库连接配置 #kafka.eagle.driver=org.sqlite.JDBC #kafka.eagle.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db #kafka.eagle.username=root #kafka.eagle.password=www.kafka-eagle.org # 修改第77行,开启mys kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://node1.itcast.cn:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull kafka.eagle.username=root kafka.eagle.password=123456 -
配置 JAVA_HOME
cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6/bin vim ke.sh # 在第24行添加JAVA_HOME环境配置 export JAVA_HOME=/export/server/jdk1.8.0_241 -
修改 Kafka eagle 可执行权限
cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6/bin chmod +x ke.sh -
启动 kafka_eagle
./ke.sh start -
访问 Kafka eagle,默认用户为 admin,密码为:123456
http://node1.itcast.cn:8048/ke
Kafka度量指标
点击Topic下的List菜单,就可以展示当前Kafka集群中的所有topic
6、Kafka原理
6.1 leader和follower
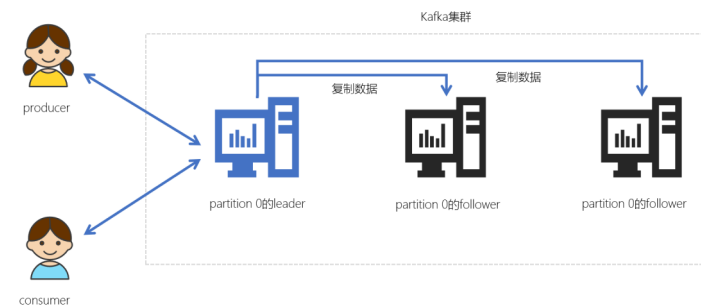
- Kafka中的 Leader 和 Follower 是相对分区有意义,不是相对broker
- Kafka在创建topic的时候,会尽量分配分区的leader在不同的broker中,其实就是负载均衡
- Leader职责:读写数据
- Follower职责:同步数据、参与选举
(leader crash之后,会选举一个follower重新成为分区的leader)
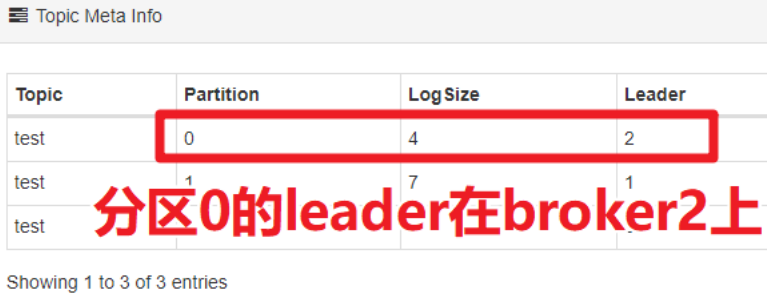
在 Kafka-eagle 中任意点击选择一个Topic
注意和 ZooKeeper 区分
- ZK的 Leader负责读、写,Follower可以读取
- Kafka的leader负责读写、follower不能读写数据(确保每个消费者消费的数据是一致的),Kafka一个topic有多个分区leader,一样可以实现数据操作的负载均衡
6.2 AR\ISR\OSR
- AR表示一个 topic 下的所有副本
- ISR:In Sync Replicas,正在同步的副本(可以理解为当前有几个follower是存活的)
由所有与leader副本保持一定程度同步的副本(包括 leader 副本在内)组成 - OSR:Out of Sync Replicas,不再同步的副本
由与follower副本同步滞后过多的副本(不包括 leader 副本)组成 - AR = ISR + OSR
- 正常情况下,所有的follower副本都应该与leader副本保持同步,即AR = ISR,OSR集合为空
查看分区的 ISR
使用 Kafka Eagle 查看某个Topic 的 partition 的 ISR 有哪几个节点
6.3 leader选举
-
Controller:
- Kafka启动时,会在所有的broker中选择一个controller
- controller是kafka集群的老大,是针对Broker的一个角色
- 负责 创建topic、或者添加分区、修改副本数量、Kafka分区leader的选举 等等
- Controller是高可用的,是通过 ZK 来进行选举
-
Leader:
- 是针对 partition 的一个角色
- Leader是通过 ISR 来进行快速选举
- 所有Partition的leader选举都由controller决定
如果该partition的所有Replica都已经宕机,则新的leader为-1
为什么不能通过ZK的方式来选举partition的leader?
- 如果Kafka是基于ZK来进行选举,ZK的压力可能会比较大
例如:某个节点崩溃,这个节点上不仅仅只有一个leader,是有不少的leader需要选举。通过ISR快速进行选举。
Leader的负载均衡
在ISR列表中,第一个replica就是preferred-replica
- 如果某个broker crash之后,就可能会导致partition的leader分布不均匀,就是一个broker上存在一个topic下不同partition的leader
- 通过以下指令,可以将leader分配到优先的leader对应的broker,确保leader是均匀分配的
bin/kafka-leader-election.sh --bootstrap-server node1.itcast.cn:9092 --topic test --partition=2 --election-type preferred--partition:指定需要重新分配leader的partition编号
6.4 Kafka读写流程
-
写流程
- 通过ZooKeeper找partition对应的leader,leader是负责写的
从 zookeeper 的 "/brokers/topics/主题名/partitions/分区名/state"节点找到该 partition 的leader - producer 在ZK中找到该ID找到对应的broker,开始写入数据
- broker进程上的leader将消息写入到本地log中
- ISR里面的follower开始同步数据,并向 leader 发送ACK
- leader 接收到所有的ISR中的Replica的ACK后,并向 生产者 返回ACK
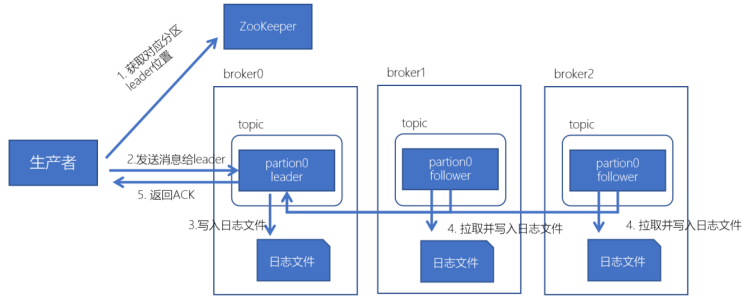
- 通过ZooKeeper找partition对应的leader,leader是负责写的
-
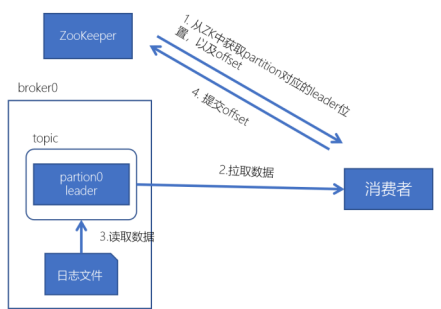
读流程
kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息- 通过ZooKeeper找partition对应的leader,leader是负责读的
- 通过ZooKeeper找到消费者对应的offset
- 然后开始从offset往后顺序拉取数据
- 提交offset(自动提交——每隔多少秒提交一次offset、手动提交——放入到事务中提交)
6.5 Kafka的物理存储
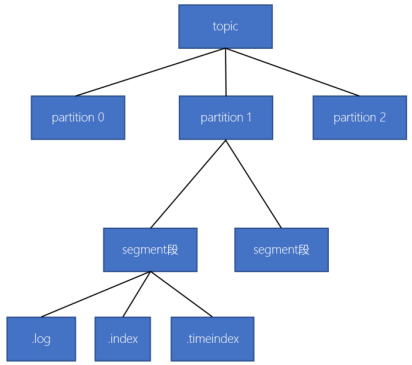
- Kafka的数据组织结构
- topic
- partition
- segment
- .log数据文件
- .index(稀疏索引)
- .timeindex(根据时间做的索引)
- 深入了解读数据的流程
- 消费者的offset是一个针对partition全局offset
- 可以根据这个offset找到segment段
- 接着需要将全局的offset转换成segment的局部offset
- 根据局部的offset,就可以从(.index稀疏索引)找到对应的数据位置
- 开始顺序读取
6.6 消息传递的语义性 ExactlyOnce
Flink里面有对应的每种不同机制的保证,提供Exactly-Once保障(二阶段事务提交方式)
- At-most once:最多一次(只管把数据消费到,不管有没有成功,保证数据不重复,但是不能保证数据不丢失)
将服务器ACK级别设置为0,可以保证生产者每条消息只会被发送一次 - At-least once:最少一次(保证数据不丢失,但是不能保证数据不重复)
将服务器的ACK级别设置为-1(all),可以保证producer到Server之间不会丢失数据 - Exactly-Once:仅有一次(事务性性的保障,保证消息有且仅被处理一次,要求数据不重复也不丢失)
6.7 Kafka的消息不丢失
- broker消息不丢失:因为有副本relicas的存在,会不断地从leader中同步副本,所以,一个broker crash,不会导致数据丢失,除非是只有一个副本。
- 生产者消息不丢失:ACK机制(配置成ALL/-1)、配置0或者1有可能会存在丢失
- 消费者消费不丢失:重点控制offset
- 在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失
- At-least once:一种数据可能会重复消费
- Exactly-Once:仅被一次消费
6.8 数据积压
使用 Kafka-Eagle 可以查看数据积压情况:
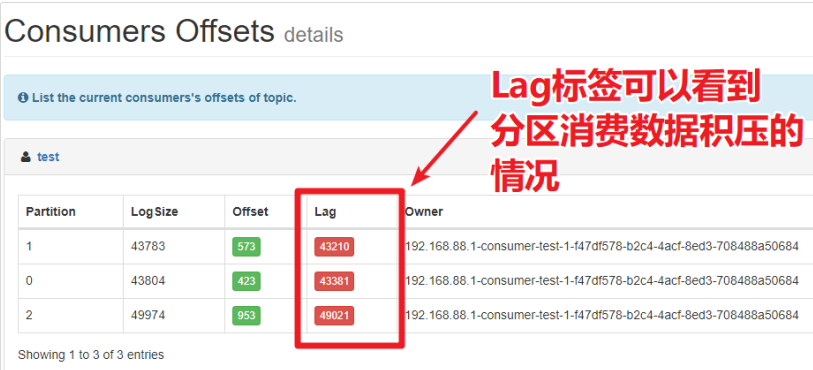
一般原因:
数据写入MySQL失败
网络延迟消费失败
- 数据积压指的是消费者因为有一些外部的IO、一些比较耗时的操作(Full GC——Stop the world),就会造成消息在partition中一直存在得不到消费,就会产生数据积压
- 在企业中,我们要有监控系统,如果出现这种情况,需要尽快处理。虽然后续的Spark Streaming/Flink可以实现背压机制,但是数据累积太多一定对实时系统它的实时性是有说影响的
数据清理&配额限速
- 数据清理
- Log Deletion(日志删除):如果消息达到一定的条件(时间、日志大小、offset大小),Kafka就会自动将日志设置为待删除(segment端的后缀名会以 .delete结尾),日志管理程序会定期清理这些日志
- 默认是7天过期
- Log Compaction(日志合并)
- 如果在一些key-value数据中,一个key可以对应多个不同版本的value
- 经过日志合并,就会只保留最新的一个版本
- Log Deletion(日志删除):如果消息达到一定的条件(时间、日志大小、offset大小),Kafka就会自动将日志设置为待删除(segment端的后缀名会以 .delete结尾),日志管理程序会定期清理这些日志
- 配额限速
- 可以限制Producer、Consumer的速率
- 防止Kafka的速度过快,占用整个服务器(broker)的所有IO资源
7、集成 SpringBoot
创建项目
pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.atguigu</groupId>
<artifactId>springboot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
SpringBoot 生产者
配置文件
# 应用名称
spring.application.name=atguigu_springboot_kafka
# 指定 kafka 的地址
spring.kafka.bootstrapservers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#指定 key 和 value 的序列化器
spring.kafka.producer.keyserializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.valueserializer=org.apache.kafka.common.serialization.StringSerializer
创建 controller 从浏览器接收数据, 并写入指定的 topic
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ProducerController {
// Kafka 模板用来向 kafka 发送数据
@Autowired
KafkaTemplate<String, String> kafka;
@RequestMapping("/atguigu")
public String data(String msg) {
kafka.send("first", msg);
return "ok";
}
}
在浏览器中给/atguigu 接口发送数据
http://localhost:8080/atguigu?msg=hello
SpringBoot 消费者
配置文件
# 指定 kafka 的地址
spring.kafka.bootstrapservers=hadoop102:9092,hadoop103:9092,hadoop104:9092
# 指定 key 和 value 的反序列化器
spring.kafka.consumer.keydeserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.valuedeserializer=org.apache.kafka.common.serialization.StringDeserializer
#指定消费者组的 group_id
spring.kafka.consumer.group-id=atguigu
创建类消费 Kafka 中指定 topic 的数据
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;
@Configuration
public class KafkaConsumer {
// 指定要监听的 topic
@KafkaListener(topics = "first")
public void consumeTopic(String msg) { // 参数: 收到的 value
System.out.println("收到的信息: " + msg);
}
}
向 first 主题发送数据
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first

















 2058
2058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









