




下面我用最清楚、最直观、又带技术细节的方式告诉你 HDBSCAN 和 DBSCAN 到底有什么区别。
一句话:HDBSCAN = 改良版的 DBSCAN,更稳、更聪明、自动化更强。
🧩 一、最简洁总结(小白友好)
| 特点 | DBSCAN | HDBSCAN |
|---|---|---|
| 是否需要 eps 参数 | 要(非常难调) | 不需要! |
| 是否能处理不同密度的簇 | 不能 | 能(主要优势) |
| 是否能自动找簇数量 | 半自动(取决于 eps) | 完全自动 |
| 是否识别噪声 | 能 | 能(更准确) |
| 是否有层次结构(hierarchy) | 没有 | **有 |
| 稳定性 | 易碎、结果敏感 | 非常稳 |
| 高维数据表现 | 一般 | 稍好(仍受限) |
一句话记住:
HDBSCAN = 不用 eps、能处理不同密度、更准确、更稳的 DBSCAN。
🧠 二、概念级区别(非常重要)
1. DBSCAN 需要 eps(ε)
eps 是“半径”,决定一个点附近多少距离算是邻居。
缺点:
-
太小 → 分成碎片
-
太大 → 全部合成一个大簇
-
不同密度 → 不可能同时适配
DBSCAN 最大问题就在这里。
2. HDBSCAN 完全移除了 eps
HDBSCAN 不需要 eps,它通过构建 密度树(cluster hierarchy) 自动选择合适的簇。
你只需要一个更好理解的参数:
-
min_cluster_size(最小簇大小)
简单、好调、稳定。
3. DBSCAN 的思想:密度阈值固定
DBSCAN 用固定密度阈值:

只在一个密度水平上看世界。
就像你一直用一个固定大小的望远镜看人群。
4. HDBSCAN 的思想:密度多级(层次化看世界)
HDBSCAN 构造 不同 eps 的聚类结果(多层密度),然后从中自动选“稳定”的簇。
就像你从高处看人群 → 再降一点高度 → 再降一点,形成连续视角。
最后自动选出“最稳定的群体结构”。
🔬 三、技术级区别(进阶,概念也很直观)
1) 使用的距离:
DBSCAN:直接用点之间距离
HDBSCAN:使用 互可达距离 Mutual Reachability Distance
![]()
这使得算法能处理不同密度区域。
2) 数据结构
DBSCAN:简单区域扩展
从一个核心点开始扩张形成簇。
HDBSCAN:构建 最小生成树 MST → 聚类树(condensed tree)
该树记录不同密度下的所有聚类结构。
然后从树中基于“稳定性”选最好的簇。
3) 聚类选择方法
DBSCAN:硬阈值判断
大于某阈值 = 一个簇。
HDBSCAN:簇稳定性(重要!)
簇的“生命时间”越长,越稳定。
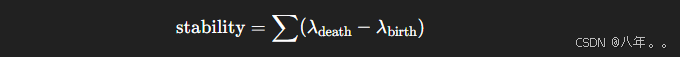
高稳定簇就被选中。
🎯 四、实际效果差别
1) 不同密度的簇
举例:
-
左边密密麻麻
-
右边稀稀疏疏
DBSCAN:
❌ 要么把稀疏的那群拆散
❌ 要么把两群合在一起
(因为一个 eps 根本不够用)
HDBSCAN:
✔ 自动处理不同密度
✔ 自动判断簇是否稳定
✔ 效果几乎总是优于 DBSCAN
2) 噪声识别
HDBSCAN 通常能更准确地把离群点标成噪声(-1),因为它利用了“稳定性”判断。
DBSCAN 在边界区域经常误判。
🧪 五、代码使用差别
DBSCAN
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=0.5, min_samples=5)
labels = db.fit_predict(data)
HDBSCAN
import hdbscan
clusterer = hdbscan.HDBSCAN(min_cluster_size=5)
labels = clusterer.fit_predict(data)
HDBSCAN 少一个 eps 参数,调参简单很多。
🏆 六、什么时候应该用 HDBSCAN?
如果你的数据:
-
不知道簇数量
-
密度不均匀
-
形状奇怪(弯曲、环状)
-
有噪声
-
用 DBSCAN 一直调不出合适的 eps
那么:
99% 情况下选 HDBSCAN 更好。DBSCAN 只有在简单数据上才表现正常。
⭐ 最终一句话总结
DBSCAN = 固定密度、只能处理均匀密度
HDBSCAN = 多密度层次、自动化、稳定、效果好

















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









