






 字符串哈希算法将字符串转换为整数,便于判断字符串重复或进行其他操作。通过将字符串视为特定进制数并模运算,减少冲突。利用公式计算子串哈希值,实现O(1)时间内获取。相同哈希值暗示字符串可能相同。
字符串哈希算法将字符串转换为整数,便于判断字符串重复或进行其他操作。通过将字符串视为特定进制数并模运算,减少冲突。利用公式计算子串哈希值,实现O(1)时间内获取。相同哈希值暗示字符串可能相同。
字符串哈希
字符串哈希,用通俗点的说法就是将一个字符串转换成一个整数,而且用哈希转换出来的整数,不同的字符串,不出意外整数也不一样(存在极少的情况一样),从而更方便地确定某个字符串是否重复出现过或者对字符串进行其他的判断。
基本思想:
假设一个字符串:abcdabcd;
将整个字符串看成一个p(p一般取131或者13331比较好,可以减少冲突的概率,某个大神总结的经验)进制数,将a->z看成1->26;然后abcdabcd就变成了:12341234;
将这个(12341234)转化为十进制数就是:
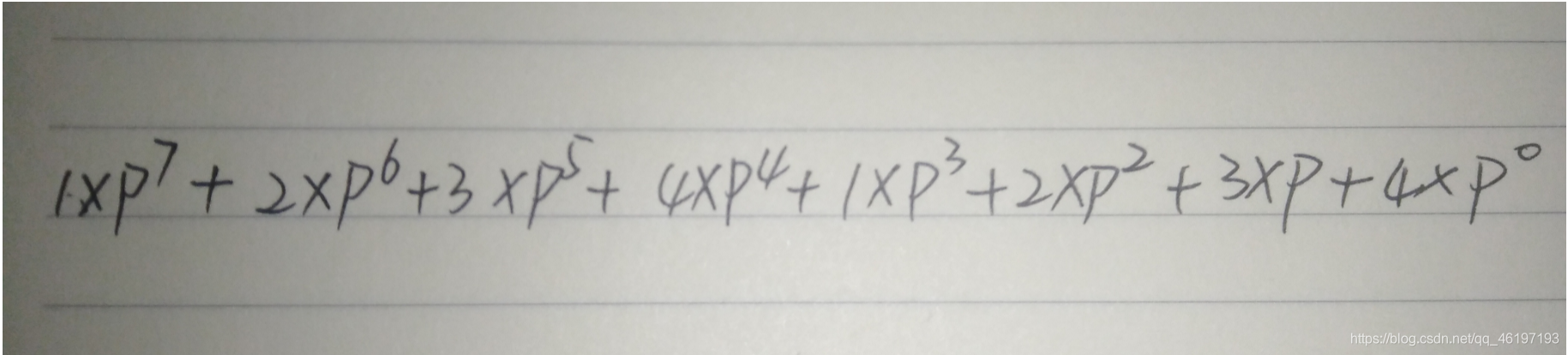
然后再用这个十进制的结果模上一个q(q一般取2^64,依旧是某位大神的建议),所得到的一个范围在1->q-1的整数就是该字符串哈希的值。
另外,q取2^64,整个过程用unsigned long long int 去存取它(溢出的话不用管,因为溢出就想当于自动模一个二的六十四次方),可以省去取模运算;
公式
一个字符串str,已知前i 个字符的hash值,求hash(i+1);
hish(i+1)=hash(i)x131+str[i+1]-‘a’+1;
例如:
字符串:abcd
hash(‘a’)=1;
hash(‘ab’)=hash(‘a’) x131+2;
hash(‘abc’)=hash(‘ab’)x131^2+3;
hash(‘abcd’)=hash(‘abc’)x131^3+4;
以上就是,该字符串里某段子串的hash值;
代码:
hash[0]=0;
for(int i=1;i<=n;i++)
{
hash[i]=hash[i-1]*131+str[i]-'a'+1;
}这种算法的优势就是:我们可以用O(1)的时间来算出某个字符串中的任何子串的hash值
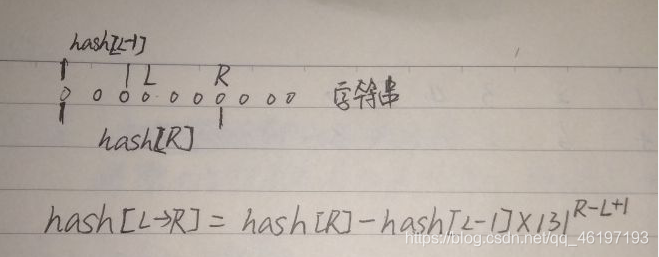
代码:
unsigned long long int fun_hash(int l,int r)
{
return hash[r]-hash[l-1]*p[r-l+1];//这个返回值就是hash[L-R],既L->R这段字符串的hash值,p数组存的是131的n次方
}当两个字符串的hash值相等,就可以知道这两个字符串是相同的。


















 1781
1781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









