




 本文详细解析了Java中对象地址、属性与hashcode的关系,讨论了根据地址和属性生成hashcode对HashSet添加元素的影响,并提供了针对自定义类和包装类的建议。通过实例测试,强调了如何确保唯一性和重复元素的避免。
本文详细解析了Java中对象地址、属性与hashcode的关系,讨论了根据地址和属性生成hashcode对HashSet添加元素的影响,并提供了针对自定义类和包装类的建议。通过实例测试,强调了如何确保唯一性和重复元素的避免。
先说一下结论:包装类直接添进去,能保证不会重复添加。如果是自定义类,重写以属性内容生成hashcode的方法,别重复添加修改属性后的同地址对象。
下面是对源码分析和证明部分,有误望指出!
一、什么是hashcode?
百度解释

1.可以简单理解为将任意长数据经哈希算法变为固定长度的一串数字。
2.不同数据生成的hashcode有可能相同,我们称之为哈希碰撞。
二、对象地址,属性,hashcode之间的关系梳理
1.先上一张总关系图,可以边打开图放一边,一边看我文字描述。
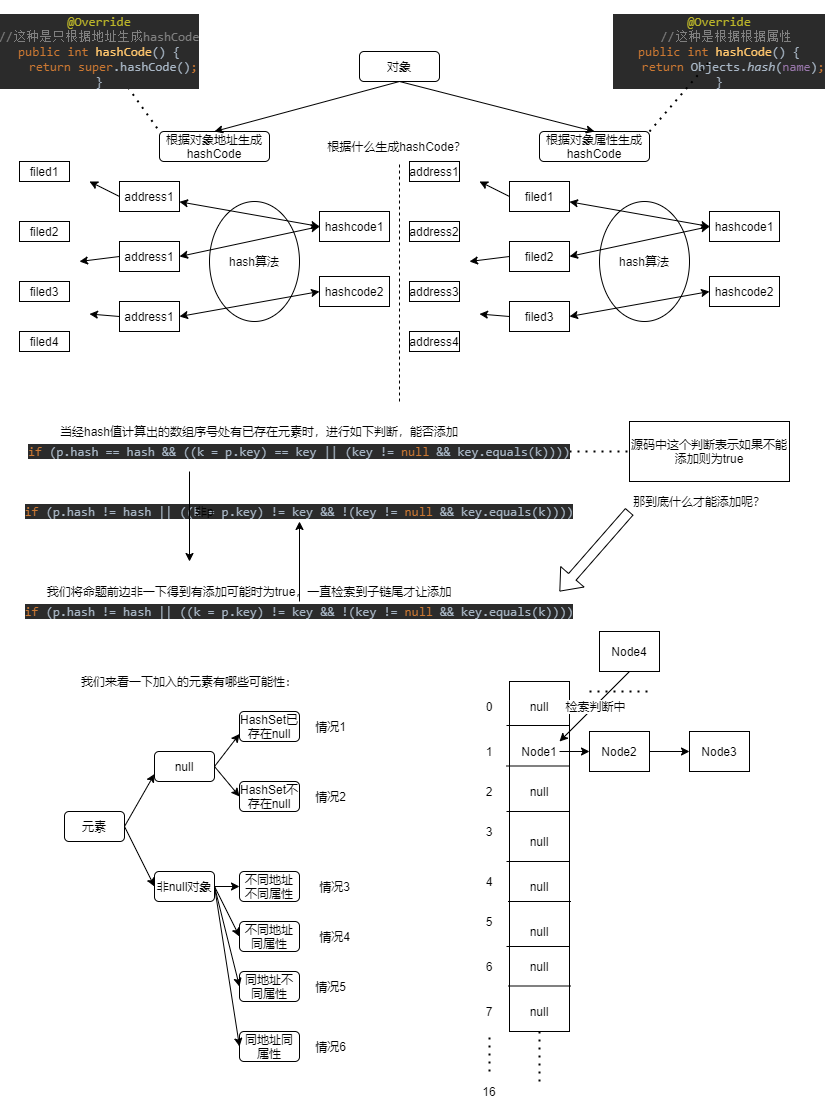
2.在java中生成对象的hashcode有两种方式
1、只根据地址生成hashcode
Cat类中重写该方法
@Override
public int hashCode() {
return super.hashCode();
}
测试同属性不同地址下hashcode的生成情况:
@Test
/**
* 测试只根据地址生成hashcode是否成立
*
*/
public void test1(){
Cat mm = new Cat("喵喵");
System.out.println(mm.hashCode());
Cat mm1=new Cat("喵喵");
System.out.println(mm1.hashCode());
}
结果为:
1859039536
278934944
结论:说明这种方法生成的hashcode只与地址有关与属性无关。同一地址的对象的属性值可以随便更换(看总关系图)。
【注意】这里hashcode定长是指二进制定长32,即4字节,可用整型来存储
2.只根据属性生成hashcode
Cat类重写该方法
@Override
public int hashCode() {
return Objects.hash(getName());//只根据属性
}
测试同地址不同属性情况下的hashcode:
@Test
/**
* 测试只根据属性生成hashcode是否成立
*
*/
public void test2(){
Cat m1 = new Cat("喵喵");
System.out.println(m1.hashCode());
m1.setName("喵呜");
System.out.println(m1.hashCode());
}
结果:
702143
701798
结论:说明只根据属性生成hashcode的方法也成立。同一个属性可以被多个不同地址的对象引用(看总关系图)。
三、向HashSet添加元素时的关键源码分析
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//表示如果是第一次添加,那就先扩容,这里默认初始化为16个Node长度的 数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据hash值运算得到待添加key值该放到数组哪里去,如果运算得到待添入位置出没有已存在的Node,那就新建个Node,Node里存好key,把Node存进该Node数组的该位置处
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//如果计算出的数组待添入位置处有Node了,则进一步比较判断是否加入
Node<K,V> e; K k;
//这里是数组处与数组处重复了该执行的操作(核心)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果数组位置处挂着一颗红黑树,则用这个判断是否添入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//遍历数组该位置处连着的子链
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//重复了就执行这个
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
四、添加不同元素可能出现的情况
回到总关系图
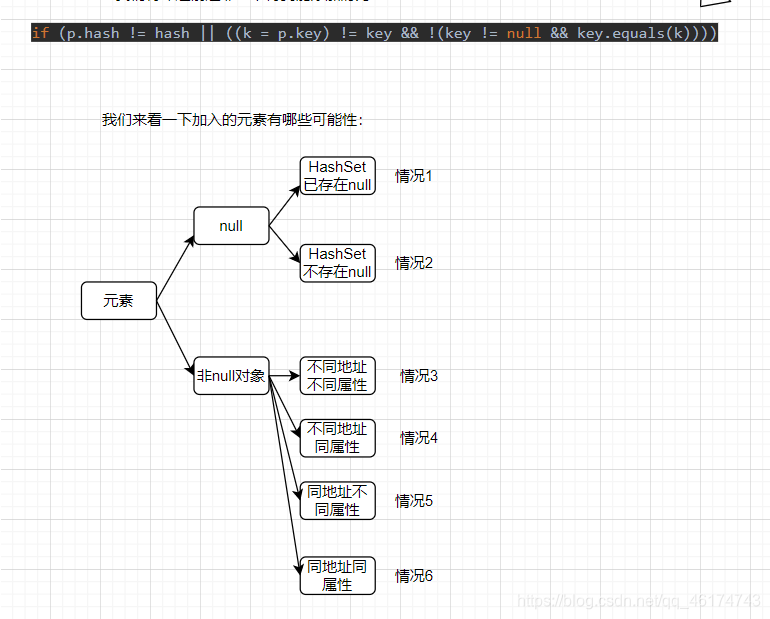
情况1:如果已存在null值那么经计算得到的hashcode肯定一样,再计算出来的在数组中的位置肯定也一样,那么必然要经过这道考验if (p.hash != hash || ((k = p.key) != key && !(key != null && key.equals(k))));数组该位置处子链上可能除了null还有其他元素,跟其它元素比较时如果p.hash!=hash为true则比较子链下一个,如果运算出来是false,则发生了hash碰撞,那么看后边p.key!=key也为true,!(key != null && key.equals(k)))也为true,那么得出结论,hash值不同就继续检索,发生hash碰撞就加上后边判断条件,按这种判断条件,如果内容不是null,即使hash碰撞也要继续往下检测,直到发生hash碰撞并后边判断null==null才不让加。
代码验证:
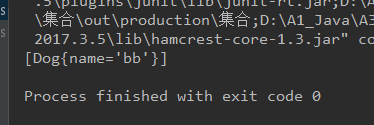
@Test
/**
* 在地址生成hashcode情况下
* 地址同,内容改,看是否会重复添加?
* [Dog{name='bb'}]不会重复,只会改,即保证不会重复添加同地址对象
*/
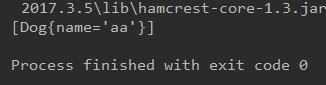
public void test2(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
hashSet.add(aa);
aa.setName("bb");
hashSet.add(aa);
System.out.println(hashSet);
}
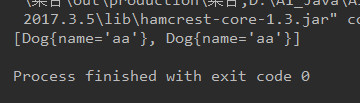
@Test
/**
* 在地址生成的hashcode情况下
* 测试地址不同,内容相同是否可添加
*[Dog{name='aa'}, Dog{name='aa'}]可添加
*/
public void test3(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
Dog a2= new Dog("aa");
hashSet.add(aa);
hashSet.add(a2);
System.out.println(hashSet);
}```
情况2:如果计算出的位置处啥也没有,那肯定直接添,如果有但又不是已存在其它元素则类似情况1,因为没有null,所以一直往下成功检索,检索到子链尾并添加。
【注意】java1.8之后null的hashcode固定为0,之前null都没有hashcode不允许加入到hashSet或hashMap。总节之,null就是单纯的不可重复添加。
情况3、4、5、6:这又得看是重写了以地址生成hashcode方法还是以属性生成hashcode方法。
1:如果以地址生成hashcode,如果里边已经存着一个同地址的,当没检索到存着同地址的那个Node头上时,一般来说没有hash碰撞,p.hash!=hash为true这样就直接获得继续检索的资格,如果发生hash碰撞,p.hash!=hash为false那么继续进行判断,p.key!=key为true,继续判断!(key != null && key.equals(k)),这里如果属性相同则为false,那么整个判断为false,那么就失去检索资格,被判定为重复。刚好检索到存着同地址的那个Node时,那么hash值 肯定一样,p.hash!=hash为false,p.key!=key为false这时就不用看了,肯定在这就停了,它失去了添加的资格。
【总结】这种以地址生成hashcode,在添加时,能保证同地址的绝对不添加,但修改地址上的内容可以时hashSet里的内容同步修改。不同地址的放进去如果一直没有hash碰撞,则直接放进去,会导致属性重复的放进去。如果hash碰撞还能够检测到属性内容重复,直接劝退。所以用地址生成hashcode只能保证存放的对象地址肯定不一样,其它就不能保证了。
2.如果以属性内容生成hashcode,如果里边已经存着一个同属性内容的,当没检索到存着同属性的那个Node头上时,一般来说没有hash碰撞,p.hash!=hash为true这样就直接获得继续检索的资格,如果发生hash碰撞,p.hash!=hash为false,继续判断p.key!=key为true,在属性地址存在于同一对象地址时,为false,那么停止检索,失去添加资格,如果属性存在于其它地址对象,为true,那么继续进行判断,!(key != null && key.equals(k))为true,继续检索。刚好检索到存着同属性的那个Node时,那么hash值 肯定一样,p.hash!=hash为false,p.key!=key为false这时就不用看了,肯定在这就停了,它失去了添加的资格,如果为ture,!(key != null && key.equals(k))为false,当场拒绝添加。
【总结】这种以属性内容生成hashcode,在添加时仅保证同属性内容的绝对不会添加,但不同属性同地址在没有hash碰撞时仍能添加,这就导致hashSet内会存在两个重复对象重复属性,不同属性同地址在发生hash碰撞就可以阻止同地址的重复添加。
代码验证:
```java
@Test
/**
* 在属性生成hashcode情况下
* 地址同,内容改,看是否会重复添加?
* [Dog{name='bb'}, Dog{name='bb'}]会重复
*/
public void test4(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
hashSet.add(aa);
aa.setName("bb");
hashSet.add(aa);
System.out.println(hashSet);
}
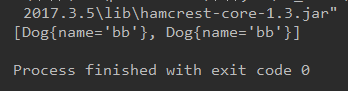
@Test
/**
* 在属性生成的hashcode情况下
* 测试地址不同,内容相同是否可添加
*可添加
*/
public void test5(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
Dog a2= new Dog("aa");
hashSet.add(aa);
hashSet.add(a2);
System.out.println(hashSet);
}```
【大总结】一般我们往hashSet里添对象都不会添重复地址的对象,这就减少了重复添地址的概率,这在以地址生成hashcode情况下,还有添加重复属性不同对象的可能。但如果以属性生成hashcode情况下,地址重复概率低,接着保证属性不会重复添加,就基本保证了地址不同且属性不同的最终要求。之所以造成这些可能的不符合HashSet不添加重复元素要求的情况,就是因为属性不是final修饰,可以任意更换。而一般我们存包装类啥的数据,人家里边属性本身就是final修饰,平时也就用基本数据类型自动转包装类型而规避了这些特殊情况。如果要自定义类,然后存里头,就可能遇到这些奇奇怪怪的事情。经这次测试研究,得出结论:基本数据类型的包装类百分百保证重复的添不进。如果想添自定义类,属性给设成final,奇葩操作造成的混乱可避免掉。如果不能设成final,自个儿注意别重复添同一地址对象,想修改对象内容,迭代遍历找出来,再修改。直接改完再添会出乱子。

















 2850
2850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









