






1.city.xml
<ruzhi>
<time year="2018">
<user username="楠楠" jobname="硬件" cityname="成都">
<hobbit>极限运动</hobbit>
</user>
<user username="谢科" jobname="芯片" cityname="江西"/>
<user username="岳云" jobname="it软件" cityname="北京"/>
<user username="婕婕" jobname="ui设计" cityname="上海">
<hobbit>篮球</hobbit>
</user>
<user username="吴宇" jobname="ui设计" cityname="内蒙"/>
<user username="乾泰" jobname="硬件" cityname="西昌">
<hobbit>篮球</hobbit>
</user>
<user username="漱玉" jobname="it软件" cityname="南京"/>
<user username="川川" jobname="it软件" cityname="南京"/>
</time>
<time year="2019">
<user username="南杰" jobname="it软件" cityname="成都"/>
<user username="智宇" jobname="ui设计" cityname="江西"/>
<user username="清韵" jobname="it软件" cityname="成都">
<hobbit>绘画</hobbit>
</user>
<user username="吴柳晨" jobname="芯片" cityname="上海"/>
<user username="康宇" jobname="ui设计" cityname="成都"/>
<user username="乾泰" jobname="硬件" cityname="西昌">
<hobbit>拍视频、唱歌</hobbit>
</user>
<user username="佘琳" jobname="芯片" cityname="南京"/>
</time>
<time year="2020">
<user username="谢玉玉" jobname="ui设计" cityname="成都"/>
<user username="谢科" jobname="ui设计" cityname="江西"/>
<user username="泽康" jobname="it软件" cityname="西昌">
<hobbit>设计页面</hobbit>
</user>
<user username="闫旭" jobname="it软件" cityname="西昌"/>
<user username="吴宇" jobname="ui设计" cityname="南京"/>
<user username="尔林" jobname="it软件" cityname="西昌"/>
<user username="杰夫与" jobname="硬件" cityname="南京">
<hobbit>旅游</hobbit>
</user>
</time>
</ruzhi>
2.python脚本
#-*-coding:UTF-8-*-
import os,sys
import xml.etree.ElementTree as ET
import xlsxwriter
year_info={}
years={}
def open_xml(xml):
#with open(xml) as xmls:#讲xml文件读取后转换为目标格式:只能针对英文xml
# xml_root=ET.fromstring(xmls.read()) #直接从字符串中解析
# year=xml_root.findAll('time')
# for time in year:
# print("year is :"+time.get('year'))
#
#
#
#
tree=ET.parse(xml)
xml_root=tree.getroot() #是所有节点的一个tree结构
i=0
for time in xml_root:
print("节点tag是:"+time.tag+'\n' +"具体年份为 :"+time.get('year'))
print("该年份内入职人个数为:",len(time))
lenths=len(time)
year=time.get('year') #获取time节点中属性year的具体值
years[i]=year #年份放入数组
i+=1
user_info={} #存放入职年份和入职人员信息
for user in time:
#user_info.clear() 不能这样清空 这个影响year_info数据
print('员工的tag为'+user.tag+'\n'+'员工名字is :'+user.get('username')+'\n'+'员工工作类型 :'+user.get('jobname')+'\n'+'员工所在城市 :'+user.get('cityname')+'\n')
#print(user.attrib['username']) 也是获取属性值的意思
child=user.find('hobbit')
if child is None:
print("元素没有找到")
user_info[user.get('username')]={'len':lenths,'job':user.get('jobname'),'city':user.get('cityname')}
else:
print("爱好是"+child.text)
user_info[user.get('username')]={'len':lenths,'job':user.get('jobname'),'city':user.get('cityname'),'hobbit':child.text}
#print('user job is :'+user_info['job']+'\n'+'user.city is :'+user_info['city']+'\n')
year_info[year]=user_info
user_info={} #清空 这样清空不影响year_info字典数据
print('最终的所有数据存放在字典中,如下:',year_info)
#对excel进行写入 xlsxwriter 只能处理新的excel文档 不能处理已经存在的文档
def get_all_user(xml):
xml_root=ET.parse(xml).getroot()
#user_node=xml_root.find('user')#find 找出来没有
#user_node=xml_root.findall('user') #由元素但为空
user_node=xml_root.find('time') #user_node=xml_root.findall('time')找出来是list,在后面执行links时会报错
if user_node is None:
print("元素没有找到")
else:
print("存在user节点")
print(user_node)
links=list(user_node.iter('user'))
print(links)
def input_data(excel,table):
num=2
num_year=2
print('字典数据如下:',year_info)
lenth=0
for ids in years:
print("当前所在年份为:",years[ids])
a=True
for user,userInfo in year_info[years[ids]].items():
print('user is :',user)
print('userInfo is :',userInfo)
lenth=userInfo['len'] #年份合并单元格使用
while a :
num_years=num_year+lenth-1
a=False
table.merge_range('A'+str(num_year)+':'+'A'+str(num_years),str(years[ids]))
table.write('B'+str(num)+':'+'B'+str(num+1),user)
table.write('C'+str(num)+':'+'C'+str(num+1),userInfo['job'])
table.write('D'+str(num)+':'+'D'+str(num+1),userInfo['city'])
#dict内置的get(key[,default])方法,如果key存在,则返回其value,否则返回default,使用这个方法永远不会触发KeyError:
#dict内置的setdefault(key[,default])方法,如果key存在,则返回其value;否则插入此key,其value为,并返回default;使用这个方法也永远不会触发KeyError
if userInfo.get('hobbit'): #判断是否有hobbit的key键 有的话返回其值
table.write('E'+str(num)+':'+'E'+str(num+1),userInfo['hobbit'])
num+=1
print("num_year =",num_years)
num_year=num_years+1
def make_xlsx(xlsx):
# excel_file=xw.Workbook(xlsx,{'constant_memory':True})
print(os.getcwd())
if os.path.exists(xlsx+'.xlsx'):
os.remove(xlsx+'.xlsx')
excel_file=xlsxwriter.Workbook(xlsx+'.xlsx')
print("excel file 创建成功!",excel_file)
table=excel_file.add_worksheet('入职名单')
title_format=excel_file.add_format({'border':2,'valign':'vcenter','bg_color':'blue','font_size':13})
#table.merge_range('A1:B1',str('入职年份'),title_format) 合并单元格
table.write('A1',str('入职年份'),title_format)
table.write('B1',str('姓名'),title_format)
table.write('C1',str('职位'),title_format)
table.write('D1',str('城市'),title_format)
table.write('E1',str('爱好'),title_format)
#table.merge_range('E1',unicode('爱好'),title_format)
input_data(excel_file,table) #存放数据
excel_file.close()
if __name__=="__main__":
#处理xml文件
if len(sys.argv)<2:
print("请传入你需要解析的xml!!")
elif len(sys.argv)>2:
print("传入参数过多!"+str(sys.argv))
else:
xml_file=sys.argv[1]
open_xml(xml_file)
#open(xml_file,'r')
#open_xml(xml_file,'r') as xml: 普通方式打卡文件
get_all_user(xml_file)
#将解析的xml文件内容存放到xlsx文件内
make_xlsx(xml_file.split('.')[0]) #创建文件
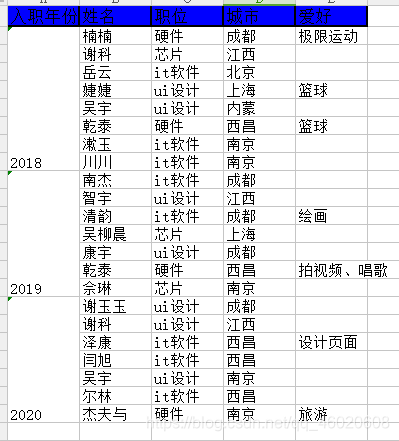
执行结果:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









