




 本文详细介绍了ApacheFlink中的流处理操作,包括map、flatMap、filter、keyBy、reduce、shuffle、rebalance、rescale、connect、union以及process等算子的使用方法和示例代码,展示了如何在数据流处理中进行转换和聚合操作。
本文详细介绍了ApacheFlink中的流处理操作,包括map、flatMap、filter、keyBy、reduce、shuffle、rebalance、rescale、connect、union以及process等算子的使用方法和示例代码,展示了如何在数据流处理中进行转换和聚合操作。
水善利万物而不争,处众人之所恶,故几于道💦
目录
1. map
2. flatMap
3. filter
4. keyBy
5. min - minBy
6. max- maxBy
7. reduce
8. shuffle
9. rebalance
10. rescale
11. connect
12. union
13. process
14. 富函数 - Rich

1. map
map(new MapFunction<WaterSensor, String>(){}
一进一出。new一个MapFunction,第一个泛型是输入的数据类型,第二个泛型是输出的数据类型
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
DataStreamSource<WaterSensor> waterSensorDataStreamSource = env.addSource(new RandomWatersensor());
waterSensorDataStreamSource
.map(new MapFunction<WaterSensor, String>() {
@Override
public String map(WaterSensor ws) throws Exception {
return ws+" 我唱歌真好听!!!";
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

2. flatMap
flatMap(new FlatMapFunction<Integer, Integer>() {}
一进n出。第一个泛型是输入元素的类型,第二个泛型是输出元素的类型
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
env.fromElements(1,2,3,4)
/* .flatMap(new FlatMapFunction<Integer, Integer>() {
@Override
public void flatMap(Integer value, Collector<Integer> out) throws Exception {
out.collect(value);
out.collect(value*value);
out.collect(value*value*value);
}
})*/
// 改写为lambda表达式,有泛型擦除,因为collector里面有泛型,所以最后用returns指明返回值类型
.flatMap((FlatMapFunction<Integer, Integer>) (value, out) -> {
out.collect(value);
out.collect(value*value);
out.collect(value*value*value);
})
.returns(Types.INT)
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:
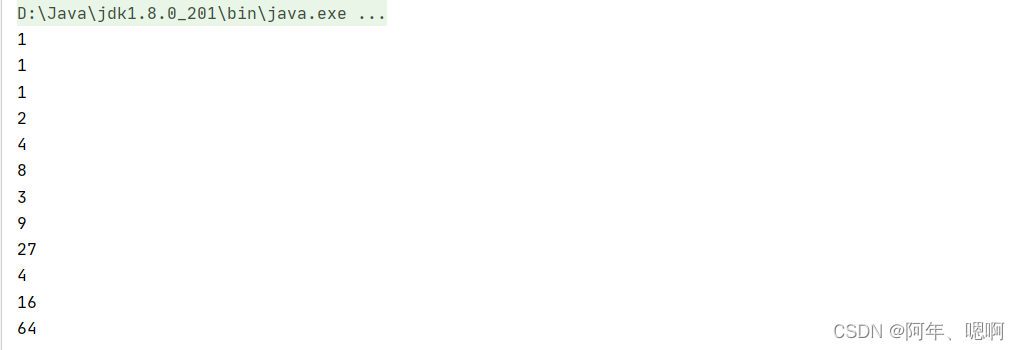
3. filter
filter(new FilterFunction< Integer>() {}
过滤。泛型是输入元素的类型
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
// todo 取出集合中的奇数
env.fromElements(1,2,3,4,5)
// .filter(new FilterFunction<Integer>() {
// @Override
// public boolean filter(Integer ele) throws Exception {
// if (ele%2 !=0){
// return true;
// }else {
// return false;
// }
// }
// })
.filter(ele-> ele%2!=0)
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

4. keyBy
keyBy(new KeySelector<Integer, String>() {}
分组。第一个泛型是输入元素的类型,第二个泛型是key的类型。
他的底层是将key进行了两次哈希,得到的值再和最大并行度128求余,得到keyGroupId,然后再用这个值乘当前并行度除最大并行度(keyGroupId * parallelism / maxParallelism)得到去哪个通道
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(2);
env.fromElements(1,2,3,4,5,6)
.keyBy(new KeySelector<Integer, String>() {
@Override
public String getKey(Integer ele) throws Exception {
if (ele%2==0){
return "偶数";
}else {
return "奇数";
}
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

5. min - minBy
min():只会返回指定字段的最小值,其他字段用第一个读到的,不会变。
它必须在keyBy之后才能用。参数可以是列名,也可以是第几列
minBy():这个会返回整条数据,也就是更新整条数据。
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1",1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1",1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1",1607527996000L, 10));
waterSensors.add(new WaterSensor("sensor_2",1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2",1607527995000L, 30));
DataStreamSource<WaterSensor> waterSensorDataStreamSource = env.fromCollection(waterSensors);
waterSensorDataStreamSource
.keyBy(new KeySelector<WaterSensor, String>() {
@Override
public String getKey(WaterSensor value) throws Exception {
return value.getId();
}
})
// .min("vc") // 只计算指定字段的最小值,其他字段的数据会保留最初第一个数据的值
.minBy("vc") // 会返回包含字段最小值的整条数据
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

6. max- maxBy
和min()的用法基本相同。7. reduce
reduce(new ReduceFunction< WaterSensor>() {} 这个泛型是聚合类型,reduce方法的第一个参数是历史聚合数据,第二个参数是新进来的数据
第一条数据不会进入reduce,因为reduce是两条数据进行操作,第一条数据只会作为历史数据。
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
ArrayList<WaterSensor> waterSensors = new ArrayList<>();
waterSensors.add(new WaterSensor("sensor_1",1607527992000L, 20));
waterSensors.add(new WaterSensor("sensor_1",1607527994000L, 50));
waterSensors.add(new WaterSensor("sensor_1",1607527996000L, 10));
waterSensors.add(new WaterSensor("sensor_2",1607527993000L, 10));
waterSensors.add(new WaterSensor("sensor_2",1607527995000L, 30));
DataStreamSource<WaterSensor> waterSensorDataStreamSource = env.fromCollection(waterSensors);
//方法引用,当返回结果是一个类的方法,可以直接用 类名::方法名 的形式进行调用
waterSensorDataStreamSource.keyBy(WaterSensor::getId)
// 要聚合的数据类型
.reduce(new ReduceFunction<WaterSensor>() {
@Override
// value1 是历史聚合的数据 value2 是新进来的那条数据
public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {
return new WaterSensor(value1.getId(),value2.getTs()/10000,value1.getVc()+value2.getVc());
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

8. shuffle
对流重新分区 - ShufflePartitioner,用随机数实现的,每次执行结果不一样
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Integer> sour = env.fromElements(4, 7, 2, 99, 57, 34, 67);
// 将数据随机打乱
DataStream<Integer> res = sour.shuffle(); // ShufflePartitioner 用随机数生成的
// DataStream<Integer> res = sour.rebalance(); // RebalancePartitioner 类似轮询,一个一个分配 可能存在跨taskmanager,所以效率不高
// DataStream<Integer> res = sour.rescale(); // RescalePartitioner 效率比较高
res.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

9. rebalance
对流重新分区 -
RebalancePartitioner,用类似轮询的方式,一个一个分配。假设map有两个并行度,当一个元素来的时候,可能会跨taskManager,所以效率比较低
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Integer> sour = env.fromElements(4, 7, 2, 99, 57, 34, 67);
// 将数据随机打乱
// DataStream<Integer> res = sour.shuffle(); // ShufflePartitioner 用随机数生成的
DataStream<Integer> res = sour.rebalance(); // RebalancePartitioner 类似轮询,一个一个分配 可能存在跨taskmanager,所以效率不高
// DataStream<Integer> res = sour.rescale(); // RescalePartitioner 效率比较高
res.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

10. rescale
对流重新分区 -
RescalePartitioner, 同 rebalance一样, 也是平均循环的分布数据. 但是要比rebalance更高效, 因为rescale不需要通过网络, 完全走的"管道"
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Integer> sour = env.fromElements(4, 7, 2, 99, 57, 34, 67);
// 将数据随机打乱
// DataStream<Integer> res = sour.shuffle(); // ShufflePartitioner 用随机数生成的
// DataStream<Integer> res = sour.rebalance(); // RebalancePartitioner 类似轮询,一个一个分配 可能存在跨taskmanager,所以效率不高
DataStream<Integer> res = sour.rescale(); // RescalePartitioner 效率比较高
res.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

11. connect
s1.connect(s2)
一次只能连接两个流,两个流的数据类型可以不一样,连接后的这个流在处理的时候还是各是分开的
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
DataStreamSource<Integer> s1 = env.fromElements(1, 2, 3, 4, 5);
DataStreamSource<String> s2 = env.fromElements("b","a","e");
ConnectedStreams<Integer, String> s12 = s1.connect(s2);
s12
.map(new CoMapFunction<Integer, String, String>() {
@Override
public String map1(Integer value) throws Exception {
return value +"<";
}
@Override
public String map2(String value) throws Exception {
return value+">";
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

12. union
s1.union(s2, s3)
它的参数是可变长参数,也就意味着一次可以连接多个流,连接的这几个流数据类型必须一致,连接后返回一个普通的流
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
DataStreamSource<Integer> s1 = env.fromElements(1, 2, 3);
DataStreamSource<Integer> s2 = env.fromElements(11, 22, 33);
DataStreamSource<Integer> s3 = env.fromElements(111, 222, 333);
DataStream<Integer> unionSource = s1.union(s2, s3);
unionSource
.map(new MapFunction<Integer, String>() {
@Override
public String map(Integer value) throws Exception {
return value + " -_-!";
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

13. process
process(new ProcessFunction< WaterSensor, String>() {},第一个泛型是输入的数据类型,第二个泛型是输出的数据类型
process算子在Flink算是一个比较底层的算子, 很多类型的流上都可以调用, 可以从流中获取更多的信息(不仅仅数据本身)
求所有的水位和:
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(2);
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1L, 10),
new WaterSensor("sensor_1", 1L, 20),
new WaterSensor("sensor_2", 1L, 30),
new WaterSensor("sensor_1", 1L, 40),
new WaterSensor("sensor_2", 1L, 50)
);
//当并行度为2的时候,他会分到两个分区里面,每个分区里面new了一个对象,所以就有两个sum,所以结果不对
stream
.process(new ProcessFunction<WaterSensor, String>() {
int sum = 0;
@Override
public void processElement(
WaterSensor value, // 进来的每个数据
Context ctx, // 上下文
Collector<String> out) throws Exception {
sum += value.getVc();
out.collect("总的水位和是:"+sum);
}
})
.print();
/* stream.keyBy(new KeySelector<WaterSensor, Integer>() {
@Override
public Integer getKey(WaterSensor value) throws Exception {
return 1;
}
})
.sum("vc").print();*/
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

keyBy后使用process
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(9);
// KeyBy之后用
// 计算每个传感器的水位和
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1L, 10),
new WaterSensor("sensor_2", 1L, 20),
new WaterSensor("sensor_1", 1L, 30),
new WaterSensor("sensor_1", 1L, 40),
new WaterSensor("sensor_2", 1L, 50)
);
stream
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
Map<String,Integer> map = new HashMap();
@Override
public void processElement(
WaterSensor value,
Context ctx,
Collector<String> out) throws Exception {
Integer sum = map.getOrDefault(ctx.getCurrentKey(), 0);
sum += value.getVc();
map.put(ctx.getCurrentKey(),sum);
out.collect(ctx.getCurrentKey()+"的水位和:"+sum);
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:

14. 富函数 - Rich
map(new RichMapFunction< WaterSensor, String>() {},每一个算子都有一个Rich版本。
Rich提供了两个生命周期方法open()和close(),它们只会在程序启动/关闭的时候每个并行度执行一次。
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port",1000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(2);
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1L, 10),
new WaterSensor("sensor_2", 1L, 20),
new WaterSensor("sensor_1", 1L, 30),
new WaterSensor("sensor_1", 1L, 40),
new WaterSensor("sensor_2", 1L, 50)
);
// 假设每来一个数据。我要从数据库里面查一次,然后根据查询的结果来决定做什么操作
stream
// 所有的算子都有rich版本,process没有,因为它本身就有这两个方法了
.map(new RichMapFunction<WaterSensor, String>() {
// open close执行几次是和并行度有关的
// open 在所有的初始化已经完成,环境已经可用的情况下,当程序启动的时候,每个并行度执行一次
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("open方法被执行了");
}
// 当程序关闭的时候,每个并行度执行一次
@Override
public void close() throws Exception {
System.out.println("close方法被执行了");
}
@Override
public String map(WaterSensor value) throws Exception {
System.out.println("map方法执行了");
return value+"";
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
运行结果:



















 5713
5713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











