




我记得本科科研训练的组会都是研究生学长学姐汇报工作,然后我们在那边听得懵懵懂懂哈哈哈,尽管如此还是想试着去写一些东西来记录这段有意义的经历
我的导师在一次组会上反复强调汇报的要点是:Problem、Motivation与Solution所以本文作为本小白的第一篇论文阅读感悟,就姑且仿照这个格式去写叭
特别提醒:因为我也是刚刚起步的科研小白,所以讲得不对的地方请大家指出,感谢批评指正😛
这篇文章还没有写完,因为实验还在跑,大概这周日之前可以结束
1论文前期知识储备
1.1 target与aspect的区别
eg: Staffs are not that friendly, but the taste covers all.
aspect方面词可能出现在句子里也有可能不出现在句子里,target是一定会出现在句子里的。比如上一句话中的aspect应该是service和food,但是均未显式出现,target应该就是Staff和taste
这里感觉自己理解的还是有点问题的,所以周一组会会和前辈们交流一下,或者自己找一些佐证
1.2 SemEval数据集
截取部分数据集如下所示:
<sentence id="32897564#894393#2">
<text>The bread is top notch as well.</text>
<aspectTerms>
<aspectTerm term="bread" polarity="positive" from="4" to="9"/>
</aspectTerms>
<aspectCategories>
<aspectCategory category="food" polarity="positive" />
</aspectCategories>
</sentence>
- aspect抽取aspect term
- 判断aspect上的情感倾向aspect term polarity
- 判断aspect所属于的范畴aspect category
- 判断aspect category的情感倾向
论文的阅读
Problem:问题
神经网络模型在多种NLP问题上取得先进性能,例如机器翻译、转述识别、问答机制和文本摘要,然而在处理方面级的情绪分类问题上还处于起步阶段
Motivation:动机以及挑战
1、Attention机制在图像识别、机器传输部分取得优异成绩;注意力机制可以提高阅读理解能力->尝试在ABSA领域引入Attention机制
Solution: 实验部分
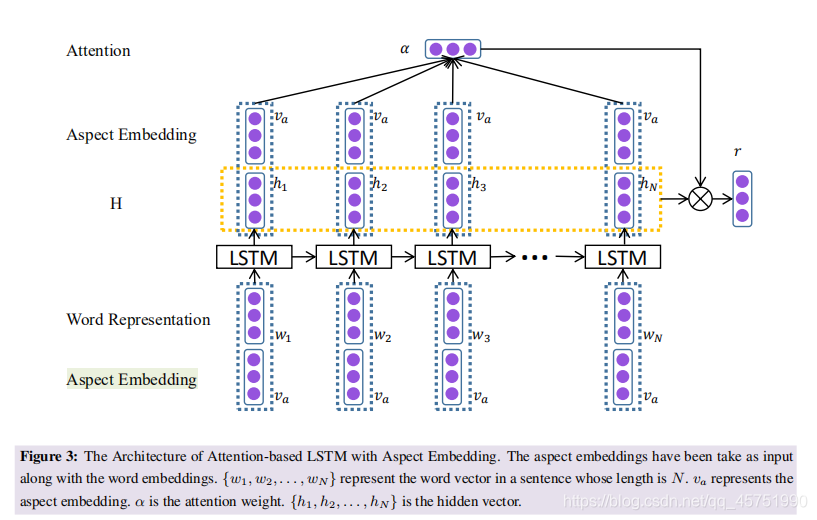
AT-LSTM
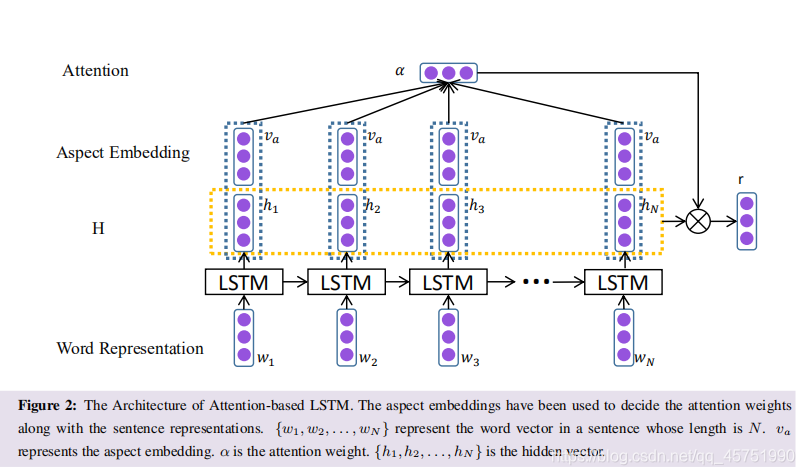
下面是公式:
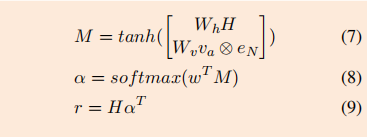
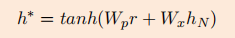
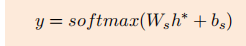
这个模型与LSTM的区别在于,对于输出的每一个隐藏状态,都加上了aspect的embedding:一个句子输入完毕后,
h
i
h_i
hi和
v
a
v_a
va一同经过softmax整合起来成为矩阵
a
a
a,利用所有隐藏层计算结果拼接起来的
H
H
H和计算得到的
a
T
a^T
aT相乘得到每一个单词的权重
r
r
r
r r r最终得到的是每个单词在预测过程中所占的权重, y y y是最后的预测结果(aspect的情感极性)
温馨提示:注意论文中给出的每个参数矩阵的形状,写代码的时候方便对照康康😀
好了,下面上代码
参考的源码链接
如果你愿意支持的话,稍后我会上传我自己的版本没错,列出来就是找打的哈哈,写得很小白
dim=-1的解释:关于维度可以用一句话总结,0表示张量的最高维度,1表示张张量的次高维度,2表示张量的次次高维度,以此类推。-1表示张量维度的最低维度,-2表示倒数第二维度,-3表示倒数第三维度。文中,张量就三个维度,所以dim=1和dim=-2的相同
class AE_LSTM(nn.Module):
'''lstm with attention embedding'''
def __init__(self,embedding_matrix,opt):
"""
:param embedding_matrix: input
:param opt: 储存参数
"""
super(AE_LSTM,self).__init__()
self.embed=nn.Embedding.from_pretrained(torch.tensor(embedding_matrix,dtype=torch.float))
# 相比于lstm增加的函数
self.squeeze_embedding=SqueezeEmbedding()
# 相较于lstm,这里opt.embed_dim多乘了2:初步理解是,加了aspect{A}后,相应的输入参数的形状扩大一倍
self.lstm=DynamicLSTM(opt.embed_dim*2,opt.hidden_dim,num_layers=1,batch_first=True)
self.dense=nn.Linear(opt.hidden_dim,opt.polarities_dim)
def forward(self,inputs):
text,aspect_text=inputs[0],inputs[1] # text=输入的文本:格式
x_len=torch.sum(text!=0,dim=-1)# x_len表示压缩成一列的和,即每个句子长度的和?
x_len_max=torch.max(x_len)# x中最长的文本长度
aspect_len=torch.sum(aspect_text!=0,dim=-1).float()# 记录每句话观点词的长度
x=self.embed(text) # x为词嵌入后的向量
x=self.squeeze_embedding(x,x_len) #按照长度进行squeezeing, lstm没有这一步
aspect=self.embed(aspect_text)# 对观点词进行词嵌入(这里为什么不用sqeeze?),lstm没有这一步
aspect_pool=torch.div(torch.sum(aspect,dim=1),aspect_len.view(aspect_len.size(0),1))
aspect=torch.unsqueeze(aspect_pool,dim=1).expand(-1,x_len_max,-1)
x=torch.torch.cat((aspect,x),dim=-1)
_,(h_n,_)=self.lstm(x,x_len)
out=self.dense(h_n[0])
return out
ATAE-LSTM
下面是pytorch的代码实现:
class ATAE_LSTM(nn.Module):
'''Attention based LSTM with Aspect Embedding'''
def __init__(self,embedding_matrix,opt):
super(ATAE_LSTM,self).__init__()
# nn.Embedding.from_pretrained:Creates Embedding instance from given 2-dimensional FloatTensor.
self.embed=nn.Embedding.from_pretrained(torch.tensor(embedding_matrix,dtype=torch.float))
self.squeeze_embedding=SqueezeEmbedding()
self.lstm=DynamicLSTM(opt.embed_dim*2,opt.hidden_dim,num_layers=1,batch_first=True)
#TODO:这边需要回头看一下attention的形状:应该是hidden_dim->H,embed_dim->a
self.attention=SoftAttention(opt.hidden_dim,opt.embed_dim)
self.dense=nn.Linear(opt.hidden_dim,opt.polarities_dim)
def forward(self,inputs):
text,aspect_text=inputs[0],inputs[1] # 输入的句子、aspect表示的incidence
x_len=torch.sum(text!=0,dim=-1) # 去除了句子长度0的句子,统计每个句子的长度,结果储存到列向量中
x_len_max=torch.max(x_len) # 找到了最长的句子不?
aspect_len=torch.sum(aspect_text!=0,dim=-1).float() # 去掉了没有aspect_term的词
x=self.embed(text)
x=self.squeeze_embedding(x,x_len)
aspect=self.embed(aspect_text)
# torch.Tensor.view():eturns a new tensor with the same data as the self tensor but of a different shape.
aspect_pool=torch.div(torch.sum(aspect,dim=1),aspect_len.view(aspect_len.size(0),1))
#TODO:这里也不太清楚为什么这个形状
aspect=torch.unsqueeze(aspect_pool,dim=1).expand(-1,x_len_max,-1)
x=torch.cat((aspect,x),dim=-1)
h,_=self.lstm(x,x_len)
hs=self.attention(h,aspect)# 模型中的a
out=self.dense(hs)
return out
数据集以及参数设置
实验用的数据集是:SemEval 2014 Task 4,的餐馆评论数据
参数设置:
- batch_size=25
- 学习率0.01
- 优化函数AdaGrad
- momentum=0.9
- 正则化0.001
后两个参数应该都是Adagrad在pytorch中的参数设置
论文的结果
| 模型名称 | 正确率 | f1 |
|---|---|---|
| AE-LSTM | ||
| ATAE-LSTM |
我的结果
其实借鉴了github上的一个PBAN的项目😅,感觉自己用pytorch写的话,大概率是没法凭空写出来的
这里解释一下f1是精确率和召回率的调和平均数,具体可以参考这篇
| 模型名称 | 正确率 | f1 |
|---|---|---|
| AE-LSTM | ||
| ATAE-LSTM |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









