



https://www.bilibili.com/video/BV1N741127FH/?

mybatis sessionsql 登录信息 spring事务管理 header 日志 ThreadLocal的应用场景
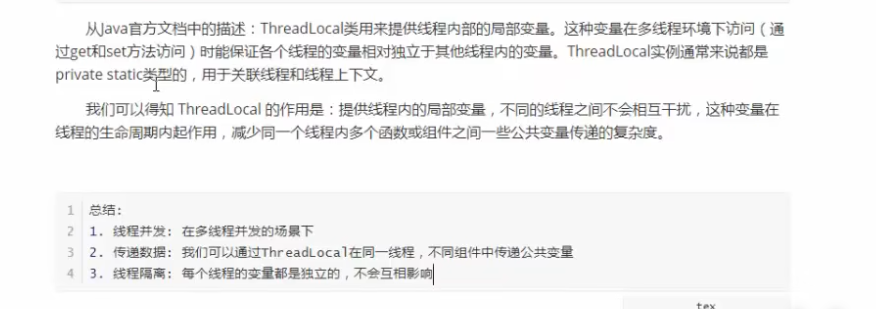
ThreadLocal 的五大经典使用场景
场景一:用户登录信息(上下文)传递
这是最经典、最广泛的应用场景。
-
问题:在 Web 应用的 Controller、Service、Dao 等各层中,都需要获取当前登录用户的信息。如果通过方法参数层层传递,会使代码变得冗余且丑陋。
-
解决方案:使用 ThreadLocal 在拦截器中存入用户信息,在任意层中直接获取。
代码实现:
-
创建用户上下文持有类
java
复制
下载
public class UserContext {
// 使用 ThreadLocal 存储登录用户信息
private static final ThreadLocal<LoginUser> USER_THREAD_LOCAL = new ThreadLocal<>();
public static void setUser(LoginUser user) {
USER_THREAD_LOCAL.set(user);
}
public static LoginUser getUser() {
return USER_THREAD_LOCAL.get();
}
// 关键:使用完后必须清除,防止内存泄漏
public static void clear() {
USER_THREAD_LOCAL.remove();
}
}
// 登录用户信息实体
@Data
public class LoginUser {
private Long userId;
private String username;
private String token;
// ... 其他字段如权限等
}
-
在拦截器中设置和清除上下文
java
复制
下载
@Component
public class AuthenticationInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
// 1. 从 Header 中获取 Token
String token = request.getHeader("Authorization");
if (StringUtils.isNotBlank(token)) {
// 2. 解析 Token,获取用户信息 (JWT 解析等)
LoginUser loginUser = JwtUtils.parseToken(token);
// 3. 将用户信息存入 ThreadLocal
UserContext.setUser(loginUser);
}
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
// 请求结束后,清理 ThreadLocal,防止内存泄漏
UserContext.clear();
}
}
-
在业务代码中任意处使用
java
复制
下载
@Service
@Transactional
public class OrderService {
public void createOrder(OrderCreateRequest request) {
// 无需从 Controller 传递用户ID,直接从这里获取
LoginUser currentUser = UserContext.getUser();
if (currentUser == null) {
throw new RuntimeException("用户未登录");
}
// 业务逻辑...
Order order = new Order();
order.setUserId(currentUser.getUserId());
orderService.save(order);
// 记录日志也可以直接拿到用户信息
log.info("用户 {} 创建了订单 {}", currentUser.getUsername(), order.getOrderId());
}
}
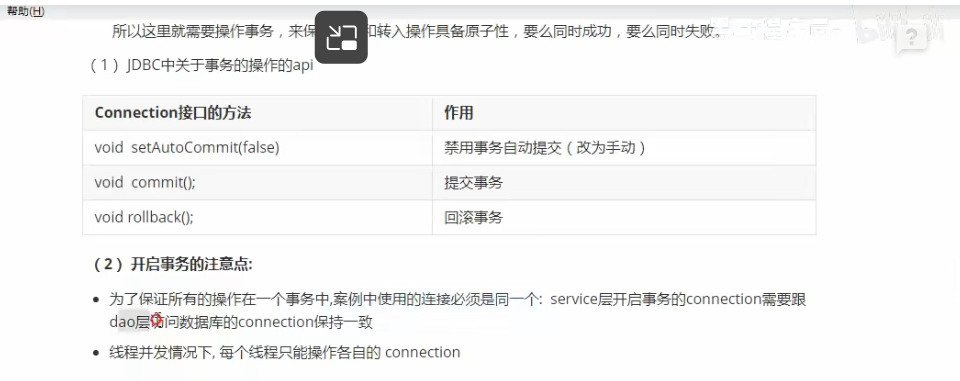
场景二:Spring 事务管理与 MyBatis SqlSession
这是 Spring 框架内部的经典应用,保证了事务的原子性。
-
问题:在
@Transactional注解标记的方法中,可能会调用多个 Mapper 方法进行数据库操作。如何确保这些操作使用的是同一个数据库连接,从而在同一个事务内? -
解决方案:Spring 使用 ThreadLocal 将数据库连接(Connection)与当前线程绑定。
工作原理:
-
事务开启:当进入
@Transactional方法时,Spring 从事务管理器获取一个数据库连接。 -
绑定到 ThreadLocal:Spring 通过
TransactionSynchronizationManager将这个连接绑定到当前线程的 ThreadLocal 中。
java
复制
下载
// Spring 框架内部的简化逻辑
public abstract class TransactionSynchronizationManager {
private static final ThreadLocal<Map<Object, Object>> resources = new NamedThreadLocal<>("Transactional resources");
public static void bindResource(Object key, Object value) {
// 将数据库连接绑定到当前线程
// ...
}
public static Object getResource(Object key) {
// 从当前线程获取绑定的数据库连接
// ...
}
}
-
MyBatis 获取 SqlSession:MyBatis 的
SqlSessionTemplate在执行 SQL 时,会先检查当前线程是否已经存在一个与事务绑定的 SqlSession。如果有,则直接使用它。 -
事务提交/回滚:事务结束时,Spring 从事务管理器的 ThreadLocal 中解绑连接,并执行提交或回滚。
这个过程确保了:
-
同一事务内的所有数据库操作使用同一连接
-
不同事务(不同线程)之间的连接互不干扰
-
事务的 ACID 特性得以保证
场景三:日志链路追踪(TraceId)
在微服务架构和分布式系统中,用于追踪一个请求的完整调用链路。
-
问题:一个请求可能会经过多个微服务,每个服务都会产生大量日志。如何从海量日志中快速筛选出同一个请求的所有日志?
-
解决方案:在请求入口生成唯一 TraceId,存入 ThreadLocal 和 MDC,在日志中统一输出。
代码实现:
-
TraceId 上下文工具类
java
复制
下载
public class TraceContext {
private static final ThreadLocal<String> TRACE_ID_THREAD_LOCAL = new ThreadLocal<>();
public static void setTraceId(String traceId) {
TRACE_ID_THREAD_LOCAL.set(traceId);
// 同时放入 MDC,供日志框架使用
MDC.put("traceId", traceId);
}
public static String getTraceId() {
return TRACE_ID_THREAD_LOCAL.get();
}
public static void clear() {
TRACE_ID_THREAD_LOCAL.remove();
MDC.clear();
}
}
-
在拦截器中设置 TraceId
java
复制
下载
@Component
public class TraceInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
// 尝试从 Header 中获取 TraceId,如果没有则生成一个新的
String traceId = request.getHeader("X-Trace-Id");
if (StringUtils.isEmpty(traceId)) {
traceId = "TRACE-" + System.currentTimeMillis() + "-" + ThreadLocalRandom.current().nextInt(1000);
}
TraceContext.setTraceId(traceId);
// 将 TraceId 设置到响应头,方便前端追踪
response.setHeader("X-Trace-Id", traceId);
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
TraceContext.clear();
}
}
-
日志配置(logback-spring.xml)
xml
复制
下载
运行
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] [%X{traceId}] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
-
日志输出效果
text
复制
下载
2024-01-20 14:30:25.123 [http-nio-8080-exec-1] [TRACE-1642660225123-456] INFO c.e.s.OrderService - 用户 admin 创建订单 2024-01-20 14:30:25.234 [http-nio-8080-exec-1] [TRACE-1642660225123-456] INFO c.e.s.PaymentService - 开始处理订单支付 2024-01-20 14:30:25.345 [http-nio-8080-exec-1] [TRACE-1642660225123-456] INFO c.e.s.InventoryService - 扣减库存成功
场景四:数据库读写分离路由
在读写分离场景中,需要根据操作类型动态选择数据源。
-
问题:如何在 Service 层的方法中标记本次操作应该使用主库还是从库,并在 Dao 层获取到这个标记?
-
解决方案:使用 ThreadLocal 存储数据源标识。
代码实现:
-
数据源上下文持有类
java
复制
下载
public class DataSourceContextHolder {
private static final ThreadLocal<String> DATASOURCE_CONTEXT = new ThreadLocal<>();
public static void setDataSource(String dataSource) {
DATASOURCE_CONTEXT.set(dataSource);
}
public static String getDataSource() {
return DATASOURCE_CONTEXT.get();
}
public static void clear() {
DATASOURCE_CONTEXT.remove();
}
}
-
自定义注解标记数据源
java
复制
下载
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface DataSource {
String value() default "master"; // master 或 slave
}
// 使用注解
@Service
public class UserService {
@DataSource("slave") // 查询使用从库
public User getUserById(Long id) {
return userMapper.selectById(id);
}
@DataSource("master") // 写操作使用主库
public void updateUser(User user) {
userMapper.updateById(user);
}
}
-
AOP 切面处理数据源切换
java
复制
下载
@Aspect
@Component
public class DataSourceAspect {
@Around("@annotation(dataSource)")
public Object around(ProceedingJoinPoint point, DataSource dataSource) throws Throwable {
try {
// 设置数据源到 ThreadLocal
DataSourceContextHolder.setDataSource(dataSource.value());
return point.proceed();
} finally {
// 清理数据源标识
DataSourceContextHolder.clear();
}
}
}
-
自定义数据源路由器
java
复制
下载
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
// 从 ThreadLocal 中获取数据源标识
return DataSourceContextHolder.getDataSource();
}
}
场景五:请求级缓存(Per-Request Cache)
在一次请求生命周期内,缓存某些计算结果或数据库查询结果。
-
问题:在一次请求中,某个昂贵的方法可能会被多次调用,希望缓存其结果避免重复计算或查询。
-
解决方案:使用 ThreadLocal 实现请求级别的缓存。
代码实现:
java
复制
下载
public class RequestCache {
private static final ThreadLocal<Map<String, Object>> CACHE = ThreadLocal.withInitial(HashMap::new);
public static void put(String key, Object value) {
CACHE.get().put(key, value);
}
public static Object get(String key) {
return CACHE.get().get(key);
}
public static void clear() {
CACHE.get().clear();
CACHE.remove();
}
}
// 使用示例
@Service
public class ProductService {
public Product getProductDetail(Long productId) {
String cacheKey = "product:" + productId;
Product product = (Product) RequestCache.get(cacheKey);
if (product == null) {
// 模拟昂贵的数据库查询
product = productMapper.selectById(productId);
// 放入请求级缓存
RequestCache.put(cacheKey, product);
}
return product;
}
}
技术架构关系图
图表
代码
下载
ThreadLocal 存储区
HTTP Request
Header: Authorization Token
拦截器
场景一: 登录信息
UserContext.setUser
场景三: 链路追踪
TraceContext.setTraceId
业务方法
场景二: 事务管理
Spring TransactionSynchronizationManager
数据源注解
场景四: 读写分离
DataSourceContextHolder.setDataSource
重复调用
场景五: 请求缓存
RequestCache.put/get
用户信息
TraceId
数据库连接
数据源标识
缓存数据
业务代码直接获取
日志自动输出
事务一致性
数据源路由
避免重复计算
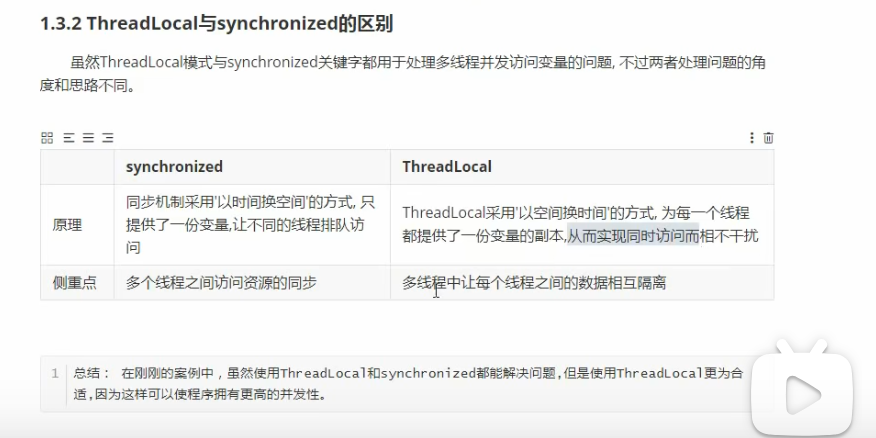
ThreadLocal 使用的重要注意事项
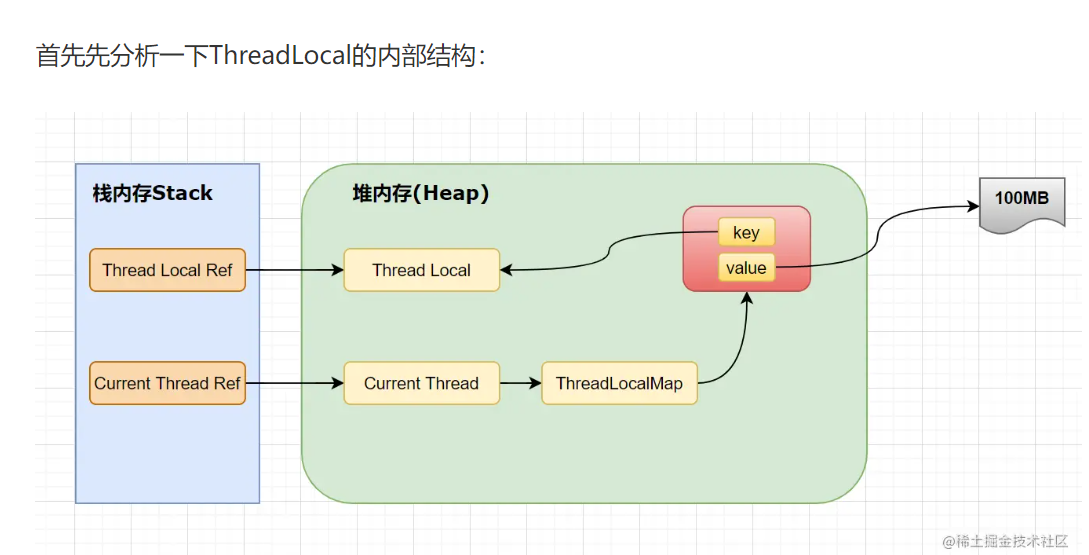
1. 内存泄漏问题
这是 ThreadLocal 最需要注意的问题。
问题根源:
-
ThreadLocal 变量存储在 Thread 的
threadLocals属性中 -
Thread 通常来自线程池,会被重复使用
-
如果使用后不清理,前一个请求的数据会泄露给下一个请求
解决方案:
java
复制
下载
// 在拦截器中清理
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
// 必须按照设置的逆序清理
UserContext.clear();
TraceContext.clear();
DataSourceContextHolder.clear();
RequestCache.clear();
}
// 或者使用 try-finally 确保清理
public void businessMethod() {
try {
// 业务逻辑
UserContext.setUser(user);
// ...
} finally {
UserContext.clear();
}
}
2. 异步场景下的问题
在线程池或 @Async 异步方法中,ThreadLocal 值不会自动传递。
解决方案:
java
复制
下载
@Async
public CompletableFuture<String> asyncProcess() {
// 手动传递 ThreadLocal 值
LoginUser user = UserContext.getUser();
String traceId = TraceContext.getTraceId();
return CompletableFuture.supplyAsync(() -> {
try {
// 在新线程中重新设置
UserContext.setUser(user);
TraceContext.setTraceId(traceId);
// 异步处理逻辑
return processResult;
} finally {
UserContext.clear();
TraceContext.clear();
}
});
}
总结
ThreadLocal 的五大经典场景体现了其核心价值:在线程生命周期内,实现跨方法、跨类的数据共享,同时保证线程安全。
-
用户上下文 - 解决身份信息传递问题
-
事务管理 - 解决数据库连接一致性问
sessionsql是什么
好的,这是一个非常关键的问题。"sessionsql" 并不是一个标准的技术术语,它很可能是一个口头的、简化的说法,通常指的是 "Session" 和 "SQL" 这两个概念在 Web 应用与数据库交互过程中的结合。
我们可以从两个层面来理解它:
-
字面组合理解:指在一个 数据库会话(Session) 中执行的所有 SQL 语句。
-
特定框架理解:特指 MyBatis 中的
SqlSession对象。
下面进行详细解析。
层面一:广义的 "Session" 与 "SQL"
在数据库和Web开发的语境中:
-
Session(会话):
-
数据库会话:指一个应用程序与数据库服务器之间建立的一个连接通道。在这个通道存活期间,客户端可以执行多条SQL语句、管理事务等。例如,在JDBC中,一个
Connection对象就代表一个数据库会话。 -
Web会话(HttpSession):指服务器为了识别特定用户,在多次HTTP请求之间维持的用户状态。用户登录后,服务器会创建一个
HttpSession并通常通过 Cookie 中的JSESSIONID来关联。
-
-
SQL:就是结构化查询语言,用于与数据库交互。
所以,"sessionsql" 可以通俗地理解为:"在一次用户会话(Web Session)中,应用程序代表该用户向数据库发起的所有的SQL操作集合"。
举个例子(用户登录场景):
-
用户输入用户名密码点击登录。
-
应用收到请求,创建或复用一个新的数据库会话。
-
在该数据库会话中执行 SQL:
SELECT * FROM users WHERE username = ? AND password = ?。 -
登录成功后,创建 Web Session 记录用户状态。
-
用户后续的请求(如查看订单、修改资料)都会在对应的 Web Session 下,执行相应的 SQL(如
SELECT * FROM orders WHERE user_id = ?)。
这一系列与某个特定用户相关的SQL,就可以被非正式地称为 "sessionsql"。
层面二:特指 MyBatis 的核心组件 —— SqlSession(最可能的解释)
在实际开发中,当人们提到 "sessionsql" 并与 MyBatis、Spring 事务放在一起讨论时,极大概率指的是 MyBatis 的核心接口 SqlSession。
什么是 SqlSession?
SqlSession 是 MyBatis 中最重要、最核心的接口,它代表了与数据库的一次交互会话。你可以把它想象成一个 JDBC Connection 的超级增强版。
它的主要职责包括:
-
获取 Mapper 接口的代理对象。
-
执行定义在映射文件中的 SQL。
-
管理数据库事务(提交、回滚)。
-
执行批量操作。
-
访问数据库的一级缓存。
SqlSession 的生命周期与线程安全
关键点:SqlSession 实例是线程不安全的。
这意味着你不能在多个线程间共享同一个 SqlSession 实例,否则会导致非常严重的数据混乱和线程安全问题。
最佳实践:SqlSession 的生命周期应该与一次 HTTP 请求保持一致。 也就是我们常说的 "一个请求,一个 SqlSession"。
SqlSession 如何与 Spring 事务管理、ThreadLocal 协同工作?
这正是您最初问题中的技术链条的核心。Spring 通过 ThreadLocal 完美地解决了 SqlSession 的线程安全和事务管理问题。
工作流程如下:
-
请求到来:当一个 HTTP 请求进入 Spring MVC 的
DispatcherServlet时,它会被分配到一个特定的线程(如 Tomcat 的http-nio-8080-exec-1)进行处理。 -
开启事务:当请求进入被
@Transactional注解标记的 Service 方法时,Spring 的事务管理器会开始一个新的事务。 -
创建并绑定
SqlSession:-
Spring 的
SqlSessionTemplate(这是 MyBatis-Spring 整合包的核心类)会创建一个新的SqlSession实例。 -
关键步骤:Spring 通过
TransactionSynchronizationManager将这个SqlSession(及其内部的数据库连接Connection)绑定到当前线程的ThreadLocal变量中。
java
复制 下载// 类似于Spring内部的简化代码 public abstract class TransactionSynchronizationManager { private static final ThreadLocal<Map<Object, Object>> resources = new NamedThreadLocal<>("Transactional resources"); // 将资源(如SqlSession/Connection)绑定到当前线程 public static void bindResource(Object key, Object value) { // ... 存入当前线程的ThreadLocal Map中 } // 从当前线程获取绑定的资源 public static Object getResource(Object key) { // ... 从当前线程的ThreadLocal Map中获取 } } -
-
执行 SQL:在同一个事务内,所有后续的 MyBatis Mapper 方法调用(比如
userMapper.selectById()),都会通过SqlSessionTemplate来执行。-
SqlSessionTemplate会首先检查当前线程的ThreadLocal中是否已经存在一个与事务绑定的SqlSession。 -
如果存在,则直接使用这个
SqlSession。这就保证了在同一个事务中,所有数据库操作使用的是同一个SqlSession和同一个数据库Connection。
-
-
事务结束:
-
当 Service 方法执行成功,没有异常时,Spring 会提交事务。
-
提交后,Spring 会从事务管理器的
ThreadLocal中解绑并关闭这个SqlSession。 -
如果出现异常,则回滚事务,同样会解绑并关闭
SqlSession。
-
-
清理
ThreadLocal:请求处理完毕,线程返回线程池,ThreadLocal被清理,确保不会泄露数据给下一个请求。
总结 SqlSession 的角色
| 组件 | 角色 | 与 ThreadLocal 的关系 |
|---|---|---|
SqlSession | MyBatis 的工作单元,代表一次数据库会话 | 它是被管理的资源对象 |
| Spring 事务管理器 | 协调者 | 使用 ThreadLocal 来绑定和管理 SqlSession/Connection |
ThreadLocal | 粘合剂和存储器 | 提供线程级别的存储,将 SqlSession "粘" 到当前处理线程上 |
结论
"sessionsql" 这个说法,最合理的解释是:
-
泛指:一个用户会话(Session)期间执行的所有 SQL。
-
特指(更常见):MyBatis 的
SqlSession,它是 MyBatis 框架执行 SQL 的核心组件。
在您最初的问题语境中,它完美地融入了这个技术链:
Header(携带Token) → 拦截器(解析Token,将用户信息存入ThreadLocal) → Spring事务(通过ThreadLocal管理SqlSession) → MyBatis SqlSession(执行SQL) → 日志(从ThreadLocal获取TraceId和用户信息进行记录)
整个链条的核心协调机制就是 ThreadLocal,它确保了在同一个线程(同一个请求)内,所有组件都能安全、高效地获取到它们需要的上下文信息。
核心问题:为什么需要 ThreadLocal 来传递 Header?
在一个典型的 Web 应用中,一个 HTTP 请求到达服务器后,通常由一个线程来负责处理整个请求生命周期。在这个过程中,请求可能会穿过多个方法调用、多个服务类、多个工具类。我们经常需要在这些“下游”方法中获取一些来自“上游”Header 的信息,例如:
-
用户身份信息:如
Authorization: Bearer <token>解析后的用户ID。 -
链路追踪信息:如
Trace-Id,用于在分布式系统中追踪一个请求的完整路径。 -
语言偏好:如
Accept-Language。 -
其他业务上下文:如调用来源、设备信息等。
如果通过方法参数一层层地传递这些信息,会使方法签名变得非常臃肿,污染所有中间层的代码,代码耦合度也会变高。
ThreadLocal 提供了一个完美的解决方案:它能够将一个变量(如用户信息)与当前执行线程绑定起来。在这个请求线程的整个生命周期内,任何地方都可以存取这个变量,而无需显式地传递它。
典型应用场景
场景一:用户身份上下文(最经典)
这是 ThreadLocal 最广泛的应用场景。在拦截器或过滤器中解析 JWT Token 或 Session,然后将用户信息存入 ThreadLocal,后续的业务代码可以直接获取。
步骤:
-
定义 ThreadLocal 上下文持有器
java
复制 下载public class UserContext { // 使用 ThreadLocal 来存储用户信息 private static final ThreadLocal<CurrentUser> CURRENT_USER = new ThreadLocal<>(); public static void setCurrentUser(CurrentUser user) { CURRENT_USER.set(user); } public static CurrentUser getCurrentUser() { return CURRENT_USER.get(); } // !!!关键:使用完后必须清除,防止内存泄漏和后续请求数据错乱 public static void clear() { CURRENT_USER.remove(); } } -
在拦截器/过滤器中设置值
java
复制 下载@Component public class AuthenticationInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 1. 从 Header 中获取 Token String token = request.getHeader("Authorization"); if (StringUtils.hasText(token)) { // 2. 解析 Token,获取用户信息 CurrentUser user = parseJwtToken(token); // 3. 将用户信息存入 ThreadLocal UserContext.setCurrentUser(user); } return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) { // 请求处理完毕后,清除 ThreadLocal UserContext.clear(); } } -
在业务Service中直接使用
java
复制 下载@Service public class OrderService { public void createOrder(CreateOrderRequest request) { // 无需从参数中传递,直接获取当前用户 CurrentUser currentUser = UserContext.getCurrentUser(); Long userId = currentUser.getId(); // ... 后续创建订单的业务逻辑,直接使用 userId System.out.println("为用户 " + userId + " 创建订单"); } }
场景二:链路追踪(TraceId)
在微服务架构中,需要一个唯一的 TraceId 来串联一次请求在所有服务中的日志。
步骤:
-
定义 TraceId 上下文
java
复制 下载public class TraceContext { private static final ThreadLocal<String> TRACE_ID = new ThreadLocal<>(); public static void setTraceId(String traceId) { TRACE_ID.set(traceId); } public static String getTraceId() { return TRACE_ID.get(); } public static void clear() { TRACE_ID.remove(); } } -
在过滤器/拦截器中生成并设置 TraceId
java
复制 下载public class TraceFilter implements Filter { @Override public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) { HttpServletRequest httpRequest = (HttpServletRequest) request; // 尝试从 Header 中获取 TraceId,如果没有则生成一个 String traceId = httpRequest.getHeader("X-Trace-Id"); if (traceId == null) { traceId = generateTraceId(); } // 设置到 ThreadLocal TraceContext.setTraceId(traceId); try { chain.doFilter(request, response); } finally { // 请求结束后清除 TraceContext.clear(); } } } -
在日志配置中使用
可以通过 MDC(Mapped Diagnostic Context)与 ThreadLocal 结合,自动将 TraceId 打印到每一条日志中。java
复制 下载// 在设置 TraceId 的同时,也放入 MDC public static void setTraceId(String traceId) { TRACE_ID.set(traceId); MDC.put("traceId", traceId); // SLF4J 的 MDC 底层也是 ThreadLocal }然后在
logback-spring.xml配置中,日志模式可以包含%X{traceId}。
场景三:多语言国际化(i18n)
根据请求头的 Accept-Language 来动态决定返回的消息语言。
-
在拦截器中解析语言头,并将 Locale 存入 ThreadLocal。
-
在消息工具类中,从 ThreadLocal 获取 Locale,并返回对应的国际化消息。
使用 ThreadLocal 的注意事项
-
内存泄漏(最重要!)
-
原因:Web 服务器(如 Tomcat)使用线程池。处理完一个请求后,线程不会销毁,而是被回收到线程池供下一个请求使用。如果处理完请求后没有调用
ThreadLocal.remove()清理,那么该线程之前持有的对象(如 User 对象)将无法被 GC 回收,因为线程还在活跃状态,从而造成内存泄漏。 -
解决:务必在请求结束时清理。通常使用
try...finally块或在拦截器的afterCompletion方法中调用remove()。
-
-
异步处理问题
-
原因:如果业务代码开启了新线程进行异步处理,由于 ThreadLocal 是与当前线程绑定的,新线程无法自动继承父线程的 ThreadLocal 数据。
-
解决:需要使用
InheritableThreadLocal或在提交异步任务时,手动将父线程的上下文传递过去并在新线程中设置。
-
-
与框架的兼容性
-
在某些框架(如 Spring)的管理下,如果方法调用跨越了 AOP 代理边界,需要确保 ThreadLocal 的设置和清理时机是正确的。通常使用拦截器(Interceptor)是标准且安全的方式。
-
现代替代方案
在响应式编程(如 WebFlux)或更复杂的异步场景中,ThreadLocal 不再适用,因为它的设计基于同步阻塞的“一个请求一个线程”模型。此时,可以考虑:
-
Spring Security 的
SecurityContextHolder:它内部就使用了 ThreadLocal 或类似的策略来存储安全上下文,是处理身份认证的“官方”方式。 -
Project Reactor 的
Context:在响应式编程中,使用 Reactor 的 Context 来传递上下文人信息。 -
Micrometer 的
Observation:用于链路追踪和观测性。
总结
| 场景 | 核心作用 | 关键 Header 示例 |
|---|---|---|
| 用户身份上下文 | 在业务层便捷获取当前用户,避免参数传递 | Authorization |
| 链路追踪 | 串联分布式系统日志,便于问题排查 | X-Trace-Id, X-Span-Id |
| 国际化 | 根据用户语言偏好返回对应文案 | Accept-Language |
总而言之,ThreadLocal 在处理 HTTP Header 时的核心价值在于:它提供了一种优雅的、线程安全的方式,将请求级别的数据(来源于 Header)存储在“线程上下文”中,使得在整个请求调用链的任何地方都能轻松访问,极大地简化了代码结构,降低了耦合度。 但在使用时,必须牢记清理工作,以防内存泄漏。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









