







 本文详细介绍了如何在Linux环境下搭建Hadoop集群,包括JDK的安装、环境变量配置、Hadoop的解压与配置、集群分发、Namenode格式化以及启动Hadoop服务。此外,还展示了使用HDFS进行文件操作的基本步骤。
本文详细介绍了如何在Linux环境下搭建Hadoop集群,包括JDK的安装、环境变量配置、Hadoop的解压与配置、集群分发、Namenode格式化以及启动Hadoop服务。此外,还展示了使用HDFS进行文件操作的基本步骤。
大数据学习(二) 搭建hadoop集群
JDK安装
先创建两个目录
mkdir -p /opt/module
mkdir -p /opt/software
我们把jdk和hadoop安装包上传到software目录里
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module/
# x : 从 tar 包中把文件提取出来
# z : 表示 tar 包是被 gzip 压缩过的,所以解压时需要用 gunzip 解压
# v : 显示详细信息
# f xxx.tar.gz : 指定被处理的文件是 xxx.tar.gz
cd /opt/module
mv jdk1.8.0_161 jdk # 重命名
配置环境变量
vi /etc/profile
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile使环境变量生效
java -version测试
hadoop安装
解压
tar -zxvf hadoop-2.6.0.tar.gz -C /opt/module/
cd /opt/module
mv hadoop-2.6.0 hadoop
配置环境变量
vi /etc/profile
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
hadoop version测试
修改配置文件
配置文件在hadoop安装目录下的etc/hadoop
hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/opt/module/jdk
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
slaves
master
slave1
slave2
分发目录
将jdk和hadoop安装目录以及环境配置脚本发送到两外两台节点
scp -r /opt/module slave1:/opt
scp -r /opt/module slave2:/opt
scp /etc/profile slave1:/etc
scp /etc/profile slave2:/etc
分别在另外两个节点source /etc/profile
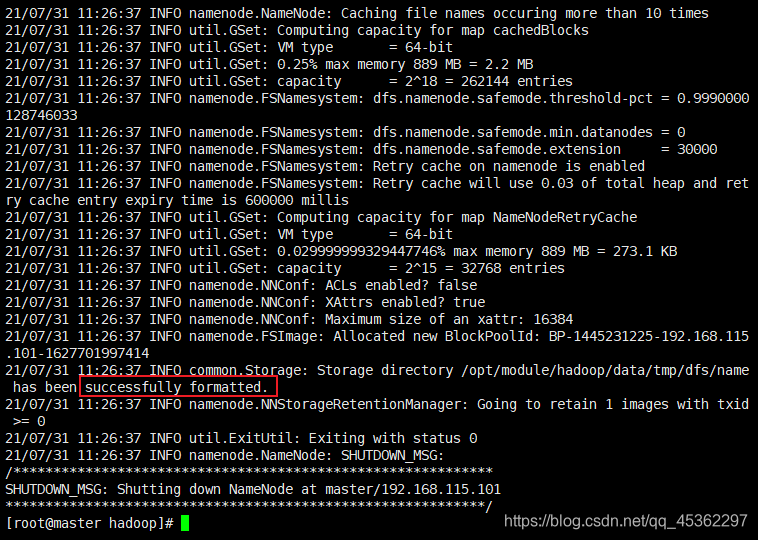
格式化namenode
hadoop namenode -format
# 或
hdfs namenode -format
启动hadoop集群
start-dfs.sh
start-yarn.sh
启动之后jps查看进程
master
9604 DataNode
9860 ResourceManager
10230 Jps
9517 NameNode
9949 NodeManager
slave1
9010 Jps
8759 DataNode
8905 NodeManager
8843 SecondaryNameNode
slave2
8769 NodeManager
8680 DataNode
8873 Jps
体验hdfs
cd /home
vi test.txt # 随便写点东西
hdfs dfs -mkdir /aaa # 创建目录
hdfs dfs -put test.txt /aaa # 把文件上传到hdfs
hdfs dfs -ls /aaa
hdfs dfs -cat /aaa/test.txt



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











