









 本文介绍如何爬取药监局网站上的企业详情数据,包括批量获取企业ID及通过ID抓取各企业详情,同时介绍了如何实现分页爬取多页数据。
本文介绍如何爬取药监局网站上的企业详情数据,包括批量获取企业ID及通过ID抓取各企业详情,同时介绍了如何实现分页爬取多页数据。
爬取药监局的企业详情数据的第一页及分页设置
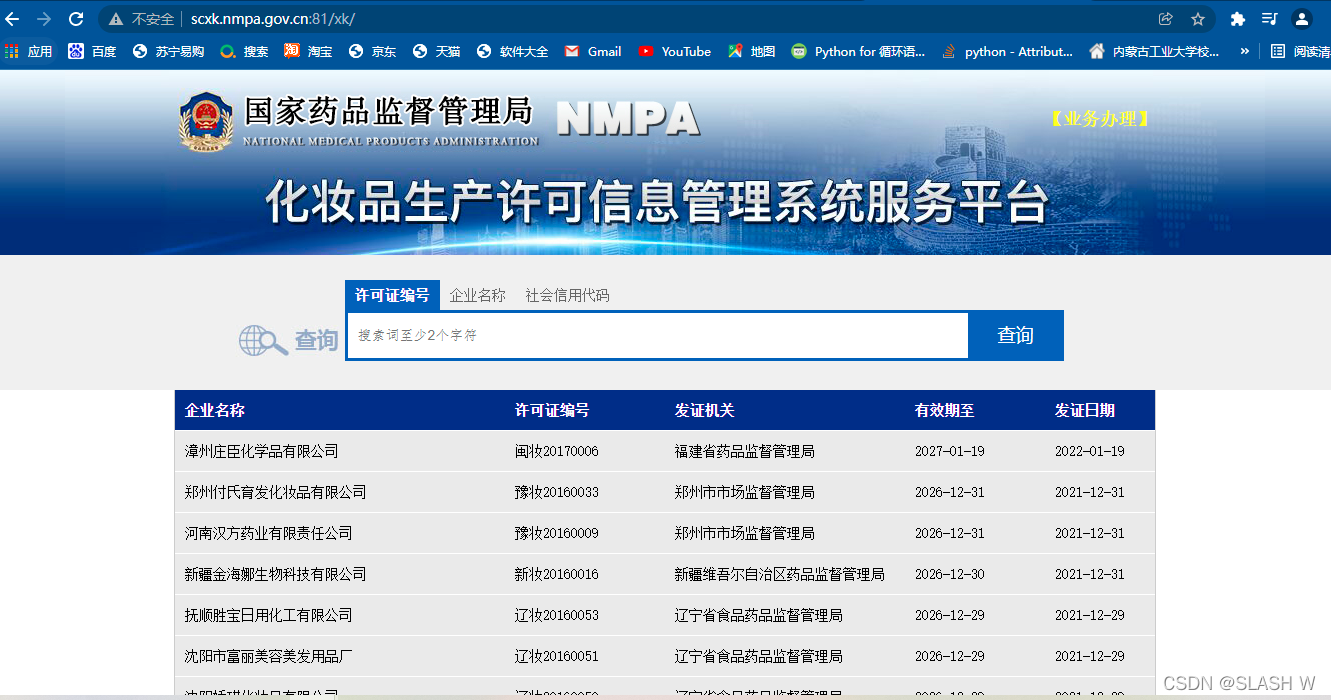
点击每一个企业都会跳转页面,进入到该企业的详细数据页,以第一个为例
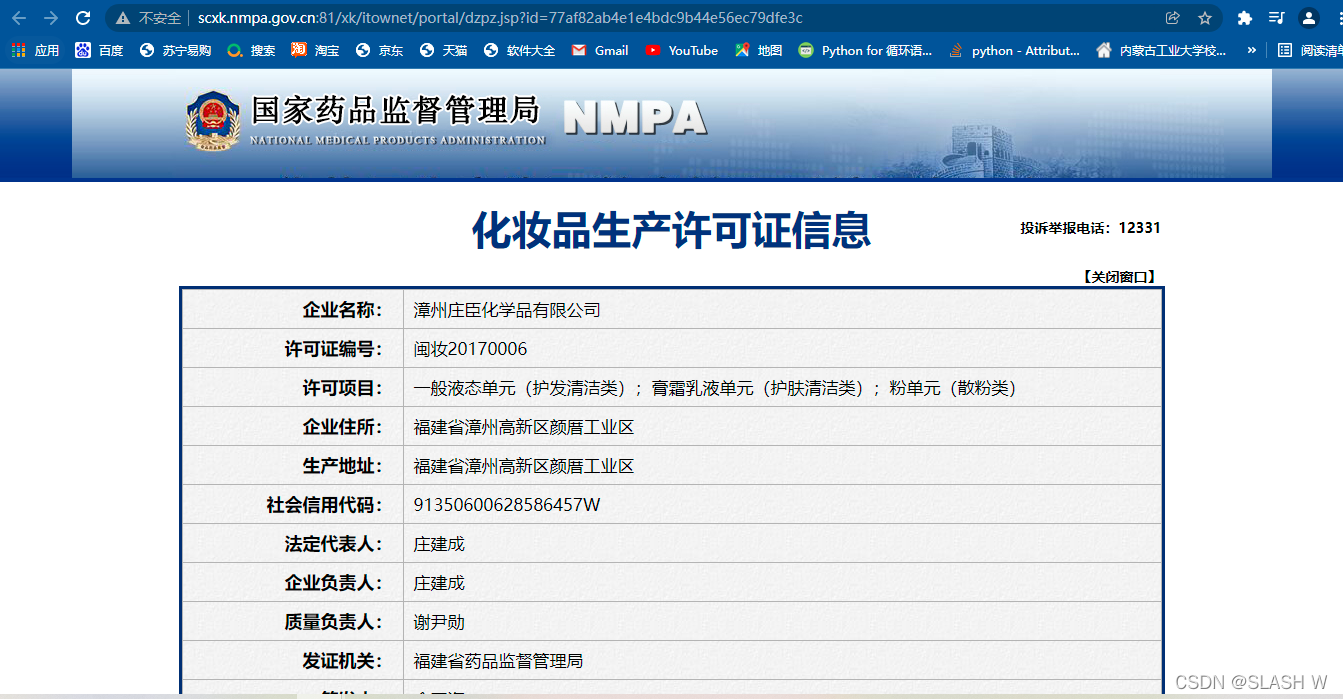
我们要爬取的就是每个企业的详细数据,就需要找到官网页面的url和每家企业的详情页url之间的关系。
打开官网页面的开发者模式,可以看到发送的是post请求,json格式数据,并且url携带多个参数,需要进行参数封装


打开响应数据response

可以看到响应数据的json格式,现在需要将这些响应数据复制到在线JSON校验格式化中进行校验,对其进行分析,发现每家企业都对应唯一的ID号,且每家企业的详情数据都被保存在一个列表中

以第一家和第二家企业为例,来看他们之间的域名只相差了一个ID号,并且打开两家企业的详情数据网页开发者模式,发现该url只携带了ID一个参数
第一家:http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=77af82ab4e1e4bdc9b44e56ec79dfe3c
第二家:http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=af4832c505b749dea76e22a193f873c6


要利用ID的引导去将他们联系起来,所以首先要批量获取不同企业的ID值
import requests
import json
# 批量获取不同企业的id值
url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
# 封装参数
data={
'on': 'true',
'page': '1',
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
}
id_list=[] # 存储企业id
json_ids=requests.post(url=url,data=data,headers=headers).json()
# 因为企业的ID都存放在一个列表中,所以需要设置循环去遍历列表来获取企业ID
for dic in json_ids['list']:
id_list.append(dic['ID'])
最后一步,获取企业详情数据
# 获取企业详情数据
post_url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
all_detail_data=[] # 存储所有企业详情数据
# 设置循环遍历,动态获取ID
for id in id_list:
data={
'id':id
}
detail_json=requests.post(url=post_url,data=data,headers=headers).json()
#print(detail_json,'-------------ending------------')
all_detail_data.append(detail_json)
fp=open('./all_detail_data.json','w',encoding='utf-8')
json.dump(all_detail_data,fp=fp,ensure_ascii=False)
print('over!')
结果展示(把结果进行了格式化校验,方便查看)
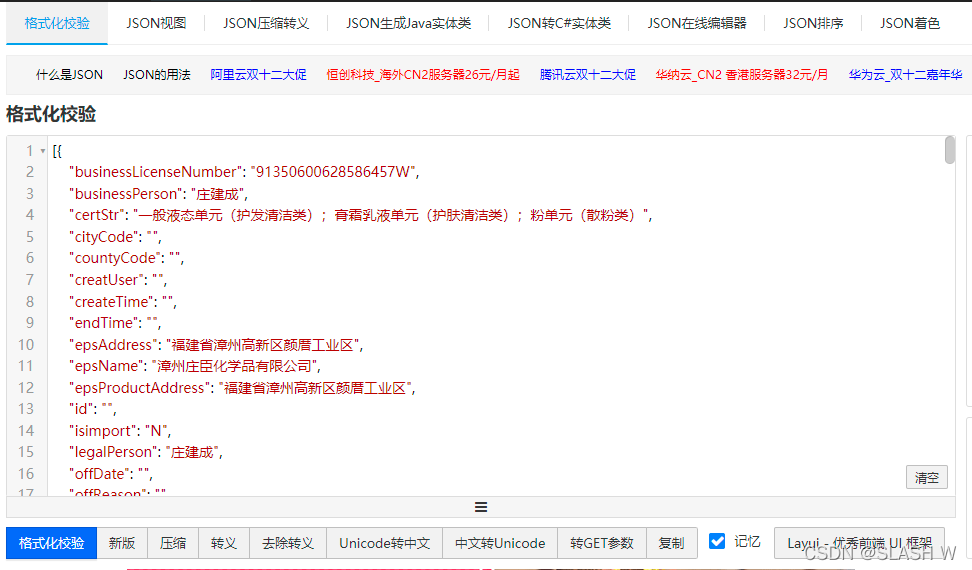
完整代码就是将两段合并即可!!!
其实可以看到官网显示的数据有很多页,但上一部分程序只爬取了第一页,下面来看分页爬取,在官网页面url所携带参数中的page的含义就是要爬取的页数,这里我们用一个循环设置爬取页数的范围,再将获取ID的代码放到该循环即可。
import requests
import json
# 批量获取不同企业的id值
url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
}
id_list=[] # 存储企业id
all_detail_data=[] # 存储所有企业详情数据
# 封装参数
# 为了爬取所有页的企业详情数据,用一个for循环遍历,这里只爬取了前5页,如果爬取全部的只需要把6改为末页
for page in range(1,6):
page=str(page)
data={
'on': 'true',
'page': page,
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
}
json_ids=requests.post(url=url,data=data,headers=headers).json()
for dic in json_ids['list']:
id_list.append(dic['ID'])
# 获取企业详情数据
post_url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data={
'id':id
}
detail_json=requests.post(url=post_url,data=data,headers=headers).json()
#print(detail_json,'-------------ending------------')
all_detail_data.append(detail_json)
fp=open('./all_detail_data_fenye.json','w',encoding='utf-8')
json.dump(all_detail_data,fp=fp,ensure_ascii=False)
print('over!')

















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









