







 本文全面解析Java线程与线程池的核心概念,包括线程状态、线程池优势及工作原理,详细对比wait()、sleep()、join()、yield()等方法,探讨线程池参数设置原则,以及ScheduledThreadPoolExecutor与Timer的区别。
本文全面解析Java线程与线程池的核心概念,包括线程状态、线程池优势及工作原理,详细对比wait()、sleep()、join()、yield()等方法,探讨线程池参数设置原则,以及ScheduledThreadPoolExecutor与Timer的区别。
文章目录
1. 线程面试题
①:线程有哪几种状态
线程是调度CPU资源的最小单位,线程模型分为KLT模型与ULT模型,JVM使用的KLT模型,一个java线程对应一个OS线程,线程有多个生命状态
- 新建:NEW
- 就绪:READY
- 运行:RUNNABLE
- 阻塞:BLOCKED
- 等待:WAITING
- 超时等待: TIMED_WAITING
- 终结:TERMINATED

问题:线程的阻塞和等待状态有什么区别?
- 阻塞: 当前线程试图获取锁,而锁被其他线程持有着,则当前线程进入阻塞状态。也就是线程和其他线程抢锁没抢到,就处于阻塞状态了;(此时线程还没进同步代码块)
- 等待: 线程抢到了锁进了同步代码块,(由于某种业务需求)某些条件下Object.wait()或join了,就处于了等待状态。(此时线程已经进入了同步代码块)。是一种主动行为,你不知道它什么时候被阻塞,也不清楚它什么时候会恢复阻塞。
②:wait()、sleep()、join()、yield()方法的区别
问题一: 线程的wait()和sleep()方法有什么区别?
| 区别 | wait() | sleep() |
|---|---|---|
| 归属类 | Object类实例方法 | Thread类静态方法 |
| 是否释放锁 | 释放锁 | 不会释放锁 |
| 线程状态 | 等待 | 睡眠 |
| 使用时机 | 只能在同步块(Synchronized)中使用 | 在任何时候使用 |
| 唤醒条件 | 其他线程调用notify()或notifyAll()方法 | 超时或调用Interrupt()方法 |
| cpu占用 | 不占用cpu,程序等待n秒 | 占用cpu,程序等待n秒 |
问题二: Thread.join方法的作用
主要作用是线程调度,等待该线程完成后,才能继续用下运行。一般用于等待异步线程执行完结果之后才能继续运行的场景。例如:主线程创建并启动了子线程,如果子线程中药进行大量耗时运算计算某个数据值,而主线程要取得这个数据值才能运行,这时就要用到 join 方法了
public static void main(String[] args) throws InterruptedException{
System.out.println("main start");
Thread t1 = new Thread(new Worker("thread-1"));
t1.start();
t1.join();
System.out.println("main end");
}
在上面的例子中,main线程要等到t1线程运行结束后,才会输出“main end”。如果不加t1.join(),main线程和t1线程是并行的。而加上t1.join(),程序就变成是顺序执行了。
问题三:Thread.yield方法的作用
和 sleep 一样都是 Thread 类的方法,都是暂停当前正在执行的线程对象,不会释放资源锁,和 sleep 不同的是 yield方法并不会让线程进入阻塞状态,而是让线程重回就绪状态,它只需要等待重新获取CPU执行时间,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。还有一点和 sleep 不同的是 yield 方法只能使同优先级或更高优先级的线程有执行的机会
2. 线程池面试题
①:什么是线程池,有哪些优势?常用API有哪些?
“线程池”,顾名思义就是一个线程缓存,线程是稀缺资源,如果被无限制的创建,不 仅会消耗系统资源,还会降低系统的稳定性,因此Java中提供线程池对线程进行统一分配、 调优和监控
1. 线程池的优势
- 线程复用,减少线程创建、销毁的开销,提高性能
- 提高响应速度,当任务到达时,无需等待线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资 源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
2. 什么时候用线程池?
- 多个任务操作之间互不影响,或者多个操作需要汇总之类的场景。
- 需要处理的任务数量很大
3. 线程池常用API
ThreadPoolExecutor:普通线程池
ScheduledThreadPoolExecutor:定时线程池

从上图可以看出 ,我们使用的线程池都实现了ExecutorService和Executor两个接口,他们定义了线程池的各种行为! 如下:
- ①:execute(Runnable command):执行行Ruannable类型的任务
- ②:submit(task):可用来提交Callable或Runnable任务,并返回代表此任务的Future对象
- ③:shutdown():温柔的关闭线程池,停止接受新任务,并执行完未完成的任务。
- ④:shutdownNow():强制关闭线程池,未完成的任务会以列表形式返回!
- ⑤:isTerminated():返回所有任务是否执行完毕。当调用shutdown()方法后,并且所有提交的任务完成后返回为true;当调用shutdownNow()方法后,成功停止后返回为true;
- ⑥:isShutdown():返回线程池是否关闭,当调用shutdown()或shutdownNow()方法后返回为true。
②:线程池有哪五种状态
进入线程池的源码:可以看到有以下五种状态
//ctl是线程池的重要属性,这个AtomicInteger通过高三位和低29位非常巧妙的记录了线程的状态和线程数量!
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
// Integer的低29位存储线程池的线程容量大小
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// Integer的高三位存储线程池的状态
private static final int RUNNING = -1 << COUNT_BITS; //高3位为111
private static final int SHUTDOWN = 0 << COUNT_BITS; //高3位为000
private static final int STOP = 1 << COUNT_BITS; //高3位为001
private static final int TIDYING = 2 << COUNT_BITS; //高3位为010
private static final int TERMINATED = 3 << COUNT_BITS; //高3位为011
| 状态 | 状态说明 | 切换条件 |
|---|---|---|
| RUNNING | 运行状态,可以接收任务、处理任务 | 线程池被一旦被创建,就处于RUNNING状态 |
| SHUTDOWN | SHUTDOWN状态,不接收新任务,但能处理已添加的任务 | 调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN |
| STOP | STOP状态,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务 | 调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP |
| TIDYING | 当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING 状态,此时会执行钩子函数terminated(),用户可自定义其实现。 | 1.当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也 为空时,就会由 SHUTDOWN -> TIDYING。 2.当线程池在STOP状态下,线程池中执行的 任务为空时,就会由STOP -> TIDYING。 |
| TERMINATED | 线程池彻底终止,就变成TERMINATED状态。 | 线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING - > TERMINATED。 |
进入TERMINATED状态的条件如下:
- 线程池不是RUNNING状态;
- 线程池状态不是TIDYING状态或TERMINATED状态;
- 如果线程池状态是SHUTDOWN并且workerQueue为空;
- workerCount为0;
- 设置TIDYING状态成功。

③: 如何实现等到线程池中的线程执行完毕后,再执行主线程?
①:使用CountDownLatch
CountDownLatch countDownLatch = new CountDownLatch(7); //7个线程
for (int i = 1; i <= 7; i++) {
new Thread(() -> {
//业务逻辑
HashMap jiaoQiang = shxReportService.getJiaoQiang("805012016440398024554");
//每执行一个线程,计数器减一
countDownLatch.countDown();
}).start();
}
//7个线程未执行完毕,都卡在这里等待!
countDownLatch.await();
。。。。。//主线程操作省略
②:使用线程池的submit提交方式,将返回结果Future<?>保存在集合list中,最后遍历集合list,逐一调用get方法,因为get方法会等待线程执行完毕获取结果!在get()后边写主线程逻辑。以多线程批量上传图片为例,需要在主方法中等待所有线程上传完毕,然后才能返回
// 1..多线程上传
// 定义Future集合
ArrayList<Future> futures = new ArrayList<>();
for (MultipartFile file : files) {
//submit返回的是Future
Future<?> submit = threadPool.submit(() -> {
//上传逻辑,返回的图片url
return TecentCloud.uploadfile(file);
});
//把返回结果futures加入Future集合中
futures.add(submit);
}
// 定义返回的url集合
ArrayList<String> list = new ArrayList<>();
//遍历集合获取返回结果!
futures.forEach(x -> {
try {
// 遍历集合获取返回结果url,30秒还未成功出异常
StringBuffer url = (StringBuffer) x.get(30, TimeUnit.SECONDS);
// 把url添加到新的集合中,返回给前端
list.add(String.valueOf(url));
} catch (InterruptedException e) {
log.info("中断异常 ******");
e.printStackTrace();
} catch (ExecutionException e) {
log.info("文件上传内部错误 ******");
e.printStackTrace();
} catch (TimeoutException e) {
log.info("文件上传超时 *******");
e.printStackTrace();
}
});
//如果url个数 != 文件个数,说明有上传失败的!
if (files.length != list.size()){
return R.error("文件未全部上传成功").put("data",list);
}
log.info("上传返回结果--------------"+list);
return R.ok().put("data", list);
④: 线程池中线程抛了异常如何处理?
3. ThreadPoolExecutor默认线程池
ThreadPoolExecutor是Executor底下的实现类,开发中常用的线程池就是它!
代码模板
public static void main(String[] args) {
//定义线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,
6,
5,
TimeUnit.SECONDS,
new ArrayBlockingQueue(5),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
//10个线程分别执行Task任务
for (int i = 0; i <10 ; i++) {
poolExecutor.execute(new Task());
}
}
//Task任务类
class Task implements Runnable{
@Override
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"执行任务!");
}
}
①: 线程池七大参数
- 1.corePoolSize核心线程数。当提交一个任务时,线程池会创建一个新线程执行任务,此时线程不会复用。如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行。此时如果核心线程有空闲,回去阻塞队列中领取任务,此时核心线程复用。
- 2.maximumPoolSize最大线程数。线程池中允许的最大线程数。如果当前阻塞队列满了,且继续提交任务,则创建新的线 程执行任务,前提是当前线程数小于maximumPoolSize;
- 3.keepAliveTime超时时间。当线程池中的线程数量大于corePoolSize的时 候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被销毁,最终会收缩到corePoolSize的大小。
- 4.unit超时时间单位。 keepAliveTime的时间单位
- 5.workQueue阻塞队列。用来保存等待被执行的任务的阻塞队列,且任务必须实现Runable接口,在JDK中提供了如下阻塞队列:
- ①:
ArrayBlockingQueue:基于数组结构的有界阻塞队列,按FIFO排序任务; - ②:
LinkedBlockingQuene:基于链表结构的阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQuene; - ③:
SynchronousQuene:一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于 LinkedBlockingQuene; - ④:
priorityBlockingQuene:具有优先级的无界阻塞队列;
- ①:
- 6.threadFactory线程工厂。它是ThreadFactory类型的变量,用来创建新线程。默认使用 Executors.defaultThreadFactory() 来创建线程。
- 7.handler拒绝策略。线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
- ①:
AbortPolicy:直接抛出异常,默认策略; - ②:
CallerRunsPolicy:用调用者所在的线程来执行任务; - ③:
DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务; - ④:
DiscardPolicy:直接丢弃任务;
- ①:
线程池监控API
getActiveCount():获取线程池中正在执行任务的线程数量getCompletedTaskCount():获取已执行完毕的任务数getTaskCount():获取线程池已执行与未执行的任务总数getPoolSize():获取线程池当前的线程数getQueue().size():获取队列中的任务数
public class ThreadMonitor {
public static void main(String[] args) {
//自定义线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,
10,
5,
TimeUnit.SECONDS,
new ArrayBlockingQueue(5),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
//execute
for (int i = 0; i < 10; i++) {
poolExecutor.execute(new ThreadMonitor.Task1());
System.out.println("获取线程池中正在执行任务的线程数量 " + poolExecutor.getActiveCount());
System.out.println("获取已执行完毕的任务数 " + poolExecutor.getCompletedTaskCount());
System.out.println("获取线程池已执行与未执行的任务总数 " + poolExecutor.getTaskCount());
System.out.println("获取线程池当前的线程数 " + poolExecutor.getPoolSize());
System.out.println("获取队列中的任务数 " + poolExecutor.getQueue().size());
System.out.println();
}
// 错误关闭线程池:shutdownNow 会有线程未执行完成而报错
// poolExecutor.shutdownNow();
// 正确关闭线程池:shutdown,等所有线程执行完毕才关闭
poolExecutor.shutdown();
}
static class Task1 implements Runnable {
@Override
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "执行任务!");
}
}
}
运行结果如下(部分截图):

②: 线程池工作原理
-
在创建了线程池后,开始等待请求。
-
当调用execute()方法添加一个请求任务时,线程池会做出如下判断:
- 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列;
- 如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
-
如果队列满了且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
-
当一个线程完成任务时,它会从队列中取下一个任务来执行。
-
当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
- 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
- 所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。
③: execute 源码分析
public void execute(Runnable command) {
//如果任务为空,抛异常
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//workerCountOf方法取出低29位的值,表示当前活动的线程数
//如果工作线程数小于核心线程数,则继续创建核心线程
if (workerCountOf(c) < corePoolSize) {
//true和false代表是否核心线程
if (addWorker(command, true))
return;
//如果添加失败,则重新获取ctl值
c = ctl.get();
}
//如果此时线程池未关闭,就把新的任务扔到队里中去
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//如果线程池不是运行状态,删掉任务,并执行拒绝策略
if (! isRunning(recheck) && remove(command))
reject(command);
//获取线程池中的有效线程数,如果数量是0,则执行addWorker方法
else if (workerCountOf(recheck) == 0)
//在线程池中创建一个线程,但不去启动
addWorker(null, false);
}
//如果队列满了,创建非核心线程
else if (!addWorker(command, false))
//如果非核心线程也满了,使用拒绝策略,默认是直接抛异常的方式
reject(command);
}
上边的代码,并没有看到线程执行任务过程,其实都封装在addWorker()方法中了!源码如下
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
// 获取运行状态
int rs = runStateOf(c);
// 判断线程池和队列 状态是否正常
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
//如果不正常,返回false
return false;
//对线程池线程数量的判断
for (;;) {
//获取线程数
int wc = workerCountOf(c);
//如果超过线程池最大容量,返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//尝试增加workerCount,如果成功,则跳出第一个for循环
if (compareAndIncrementWorkerCount(c))
break retry;
//如果失败,重新获取ctl的值
c = ctl.get(); // Re-read ctl
//如果当前状态不等于上边的rs,重新循环!
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//根据任务创建一个Worker对象,Worker详解见下文①
w = new Worker(firstTask);
//获取worker的thread属性,也即线程工厂为当前worker对象创建的线程
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
//加锁
mainLock.lock();
try {
int rs = runStateOf(ctl.get()); //获取线程池运行状态
//如果状态是RUNNING状态或者是SHUTDOWN状态并且firstTask为null,向Worker线程集合中保存线程。
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//向hashSet集合中保存Worker线程,为了shutdown时,还会执行未完成的任务!
workers.add(w);
int s = workers.size();
//hashSet集合长度和最大线程池比较
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//启动线程 见下文②讲解!
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
上面的方法比较长,总体上分为四步
- ①:先判断线程池的运行状态,如果不是running,或者已经为shutdown但是工作队列已经为空,那么这个时候直接返回添加工作失败。
- ②:判断线程池的线程数量。
- ③:确认了线程池状态以及线程池中工作线程数量之后,才真正开始添加工作线程到存放工作线程的容器Workers中。Workers是一个hashSet集合,后续继续执行的时候从这里边取线程即可!
- ④:调用start() 方法执行线程,就完成了工作线程的建立与启动!
addWorker()方法创建了一个Worker对象,每一个工作线程都与一个worker对象绑定,那么Worker是什么呢?
Worker的作用
Worker是ThreadPoolExecute的一个内部类,继承了AQS,可以通过加锁保证线程安全Worker实现了Runnable接口,可以当做一个线程去使用
Worker中有两个线程变量:
firstTask:代表任务线程。通过start方法执行任务thread:代表Worker本身,由ThreadFactory创建,参数为this,所以创建的线程其实指向的是Worker本身!
======================== ① Worker是什么?===========================
//worker是ThreadPoolExecute的一个内部类,继承了AQS,并实现了Runnable接口,
//包含属性firstTask、thread等
new Worker代码如下:
Worker(Runnable firstTask) {
setState(-1);
//给worker的firstTask属性赋值,绑定工作线程
this.firstTask = firstTask;
//使用线程工厂为当前任务创建一个线程
//注意:new Thread() 传入的不是任务,而是携带任务的Worker,因为Worker实现了Runnable
this.thread = getThreadFactory().newThread(this);
}
addWorker()方法最后调用t.start()方法启动了线程,t就是Worker内部的成员属性Thread,也就是Worker本身,其实就是调用了Worker内部的run方法,
======================== ② t.start()是怎么执行的?======================
t.start()方法代表Worker线程启动,自然调的是Worker内部类中的run方法!
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//这里就是线程可以重用的原因,循环+条件判断,不断从队列中取任务
//还有一个问题就是非核心线程的超时删除是怎么解决的
//主要就是getTask方法()见下文③
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行线程
task.run();
//异常处理
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
//出现异常时completedAbruptly不会被修改为false
completedAbruptly = false;
} finally {
//如果如果completedAbruptly值为true,则出现异常,则添加新的Worker处理后边的线程
processWorkerExit(w, completedAbruptly);
}
}
非核心线程超时剔除是如何实现的?
runworker()方法通过while循环不断从队列中获取任务,达到线程复用的目的。从队列中获取任务是通过 getTask()方法实现的,getTask()方法内部通过判断工作线程是否大于核心线程数,再结合keepAliveTime 实现了非核心线程超时自动剔除和核心线程无任务时阻塞获取!
======================== ③ getTask()是怎么执行的?====================
//getTask方法用来从阻塞队列中取任务:
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
//死循环不断从阻塞队列中取任务
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
//获取线程数量
int wc = workerCountOf(c);
// 如果线程数量是否大于核心线程 ,timeed为true
// 或者allowCoreThreadTimeOut 为true,timeed也为true
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 根据timed来判断,如果为true,则通过阻塞队列的poll方法进行超时控制,
// 如果在keepAliveTime时间内没有获取到任务,则返回null,从而跳出runWorker()方法的while循环,非核心线程超时剔除!
//核心线程不会剔除的原因是: 通过take方法,如果队列为空,则take方法会阻塞直到队列不为空,核心线程一直会阻塞等待
//如果想要使用核心线程也超时,只需要设置allowCoreThreadTimeOut = true 即可!
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
///如果 r == null,说明已经超时,timedOut设置为true
return r;
timedOut = true;
} catch (InterruptedException retry) {
// 如果获取任务时当前线程发生了中断,则设置timedOut为false并返回循环重试
timedOut = false;
}
}
}
总结一下runWorker方法的执行过程:
- ①:while循环不断地通过getTask()方法获取任务;
- ②:getTask()方法从阻塞队列中取任务;
- ③:如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态;
- ④:调用task.run()执行任务;
- ⑤:如果task为null则跳出循环,执行processWorkerExit()方法;
- ⑥:runWorker方法执行完毕,也代表着Worker中的run方法执行完毕,销毁线程。

4. ScheduledThreadPoolExecutor定时线程池
用于处理延时执行任务,或间隔时间循环执行任务的场景,定时线程池ScheduledThreadPoolExecutor没有非核心线程的概念,都是核心线程,这是他与默认线程池的一点区别。
①:定时线程池的三种任务提交方式,以及区别
- ①:schedule
- ②:scheduledAtFixedRate ------- 可能会堆积任务以至于OOM。
- ③:scheduledWithFixedDelay
三种提交方式的使用和区别如下代码所示:
//定义一个延时线程池
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
//延时线程池
ScheduledFuture<?> schedule = scheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
System.out.println("延时线程池,延迟三秒执行!");
}
}, 3, TimeUnit.SECONDS);
//延时线程池
ScheduledFuture<?> schedule2 = scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("延时线程池,延迟1秒执行,不等待上一个任务结束,每三秒执行一次!");
}
},1, 3, TimeUnit.SECONDS);
//延时定时线程池
ScheduledFuture<?> schedule1 = scheduledThreadPool.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
System.out.println("延时线程池,延迟1秒执行,然后等待上一个任务结束,再每三秒执行一次!");
}
}, 1,3, TimeUnit.SECONDS);
4.2 定时线程池抛异常会怎么样?
在定时线程池中,定时循环执行一个任务时,如果任务出现异常,会和默认线程池一样,创建一个Worker,但是此时的任务已经没有了,所以在使用定时线程池时要注意异常的捕获,否则任务就会丢失!
②:定时线程池工作原理
首先在new 一个newScheduledThreadPool时,源码是这样的:
注意这个线程池用的队列是延时队列!
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue()); //使用了延时队列!
}
然后看一下执行任务的方法scheduleWithFixedDelay源码:
注意:任务先提交后执行
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
//把任务包装成ScheduledFutureTask,对任务的执行时间进行了排序,这样就知道那个任务先执行
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(-delay));
//进一步装饰任务,源码无实现,留给开发者扩展用
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
//提交任务,下边讲解!!
delayedExecute(t);
return t;
}
看一下ScheduledFutureTask的结构,正是他实现了Comparable接口,并重写了CompareTo方法,才实现的排序。同时也实现了Runnable接口,说明任务的执行是在ScheduledFutureTask重写的run方法中!!
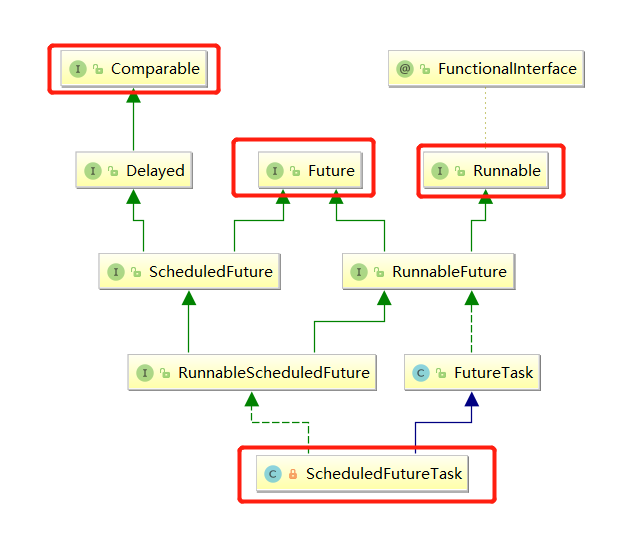
为什么说定时线程池没有和非核心线程的概念呢?其实在提交任务 delayedExecute(t)方法中可以看到:
private void delayedExecute(RunnableScheduledFuture<?> task) {
//判断线程池状态
if (isShutdown())
reject(task);
else {
//发现这里直接把任务放进延时队列中去!!
//并没有先让核心线程去执行,也没有非核心线程池的概念!!
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
//如果线程池状态不对,删除任务
remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
任务已经提交至延时队列,接下来线程怎么执行任务呢?上边说到任务的执行是在ScheduledFutureTask重写的run方法中,进去看一下:
可以发现run方法中根据任务是否周期执行,分别对应不同的逻辑
区别是如果周期性的执行任务,会设置下一次任务执行的时间。如果只延时执行一次(schedule),则只执行一次就结束了
public void run() {
//判断任务是否周期性执行
boolean periodic = isPeriodic();
//判断任务状态
if (!canRunInCurrentRunState(periodic))
cancel(false);
//如果是非周期性执行,也就是schedule方法,只延时执行一次任务
//直接执行run方法然后结束
else if (!periodic)
ScheduledFutureTask.super.run();
//如果是周期性执行,也就是剩下的两个方法
//则在runAndReset执行完任务以后,设置下一次执行时间
else if (ScheduledFutureTask.super.runAndReset()) {
//设置下一次任务的执行时间!下文①讲解
setNextRunTime();
//重复执行任务 下文②讲解
reExecutePeriodic(outerTask);
}
}
下面这两种任务提交方式的区别,就在于设置下一次任务执行时间的setNextRunTime()方法中!
- ①:scheduledAtFixedRate ------- 可能会堆积任务以至于OOM。
- ②:scheduledWithFixedDelay
两个方法在把任务包装成ScheduledFutureTask时传入的循环周期并不一样,一个为正,一个为负。
unit.toNanos(period) //scheduledAtFixedRate传入的为正
unit.toNanos(-delay) //scheduledWithFixedDelay传入的为负
而setNextRunTime又根据循环周期的正负来设置下一次执行的时间
①: private void setNextRunTime() {
long p = period;
if (p > 0) //scheduledAtFixedRate下次任务执行时间,是直接加在后边的,可能会堆积任务
time += p;
else //scheduledWithFixedDelay下次任务执行时间,不是直接加在后边
time = triggerTime(-p);
}
那么任务是怎么被周期性的执行呢?看一下 reExecutePeriodic(outerTask);方法:
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(true)) {
//又把这个任务放进队列中,再次执行
super.getQueue().add(task);
if (!canRunInCurrentRunState(true) && remove(task))
task.cancel(false);
else
//这里是增加一个worker线程,避免提交的任务没有worker去执行
//原因就是该类没有像ThreadPoolExecutor一样,woker满了才放入队列
ensurePrestart();
}
}
5. Timer和ScheduledThreadPoolExecutor的区别
两者都可以完成任务的定时执行,但是阿里巴巴推荐使用定时线程池ScheduledThreadPoolExecutor,为什么呢?
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println("Timer类实现延时执行任务!");
}
},100,1000);
因为Timer是单线程,他依赖内部的一个线程属性TimerThread
private final TimerThread thread = new TimerThread(queue);
而TimerThread 继承了Thread类,也就是说Timer是一个单线程的!
class TimerThread extends Thread {}
测试代码:
public class TimerTest {
public static void main(String[] args) {
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println("Timer类实现延时执行任务一!");
throw new RuntimeException();
}
},100,1000);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println("Timer类实现延时执行任务二!");
throw new RuntimeException();
}
},100,1000);
}
}
测试结果:

结论:如果Timer中的任务有异常,那么Timer中剩下的所有任务都会抛异常,而定时线程池中一个任务出现异常,其他任务照常执行,这就是Timer和ScheduledThreadPoolExecutor的区别。
6. 自定义线程池的参数依据
在给线程池设定线程参数时,要根据任务性质来区别!
- ①:cpu密集型
- 也叫计算密集型,系统中大部份时间用来做计算、逻辑判断等,一般而言CPU占用率相当高。多线程跑的时候,可以充分利用起所有的cpu核心,比如说4个核心的cpu,开4个线程的时候,可以同时跑4个线程的运算任务,此时是最大效率。但是如果线程远远超出cpu核心数量 反而会使得任务效率下降,因为频繁的切换线程也是要消耗时间的
- 线程数一般设置为:
线程数 = CPU核数+1
- ②:IO密集型
- 指任务需要执行大量的IO操作,涉及到网络、磁盘IO操作。当线程因为IO阻塞而进入阻塞状态后,该线程的调度被操作系统内核立即停止,不再占用CPU时间片段,而其他IO线程能立即被操作系统内核调度,等IO阻塞操作完成后,原来阻塞状态的线程重新变成就绪状态,而可以被操作系统调度。所以,像数据库服务器中的IO密集型线程来说,线程的数量就应该适量的多点。
- 线程数一般设置为:
线程数 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
CPU密集型 vs IO密集型:
我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
7. execute() 和 submit() 提交任务方法的区别
execute() 和 submit() 两者都是提交任务,不过execute没返回值,而submit有返回值。他们的关系如源码所示:submit方法里边包含了exectue,不过是多一层Future封装!在主线程中可以用Future的API==>get() 方法来获取结果。
//submit()方法
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task); //把任务包装成Future
execute(ftask); // 执行execute方法
return ftask;
}
7.1 execute() 和 submit() 的使用:
//execute
poolExecutor.execute(()->{
System.out.println("execute方法,无返回结果!!");
});
//submit
Future<Integer> submit = poolExecutor.submit(() -> {
System.out.println("submit方法,有返回结果!!");
Thread.sleep(2000);
return 1;
});
//业务代码。。。
System.out.println(submit.get()); //等待
System.out.println("main线程上边有get(),会等待submit提交的任务执行完,才往后执行");
从上面的代码可以看出,submit.get()会等待submit提交的任务完成后,才取回结果,往下执行。所以get()方法尽量放在业务代码最后调用,以便于submit提交的任务在执行计算的同时,业务代码也在执行。但是如果submit提交的任务,一直阻塞(比如,远程调用服务、网络原因),那么主线程调用get()也会跟着被阻塞,造成请求时间过长,用户体验相当不好!如何解决呢?submit也提供了对应的API!
public V get(long timeout, TimeUnit unit) //get方法设置超时时间,超时自动删除任务!
使用超时的方法,就解决了请求一直阻塞问题!
7.2 get()方法获取任务结果的流程
public V get() throws InterruptedException, ExecutionException {
int s = state;
//如果任务状态是未完成
if (s <= COMPLETING)
//完成任务前阻塞或者超时终止
s = awaitDone(false, 0L);
return report(s);
}
awaitDone(false, 0L)主要是对线程进行阻塞!方法如下
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
//WaitNode是一个任务节点,任务最终会形成一个队列
WaitNode q = null;
boolean queued = false;
//死循环,注意:get()方法可能是多个线程一起调用,
//死循环用于多线程任务结果获取时阻塞并入队
for (;;) {
//如果当前线程被中断
if (Thread.interrupted()) {
//删除此节点
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
//如果线程状态为已完成,则释放cpu
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
//如果节点为空,也就是第一次获取结果,则创建一个节点,并重新循环
else if (q == null)
q = new WaitNode();
//使用CAS的方式,把节点入队!
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
//如果设有超时时间,比较是否超时,超时则删除节点!
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
//上述条件完成后,线程阻塞park,等待任务执行完毕后唤醒!!!
else
LockSupport.park(this);
}
}
当submit提交的任务执行完毕后,阻塞的线程会被唤醒!唤醒一定是在执行完成后才发生的,上文中看到submit方法最后调用的还是execute()方法,所以和execute的addWorker逻辑类似,不过程序执行是在FutureTask类中重写后的run方法中,代码就不贴了,进入run方法中的set(result)方法就可以看到unpark,具体如下!
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
finishCompletion();
}
}
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
//唤醒队列中阻塞的节点!!!
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
8. 美团的线程池技术文档
https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









