







目录
一、概述
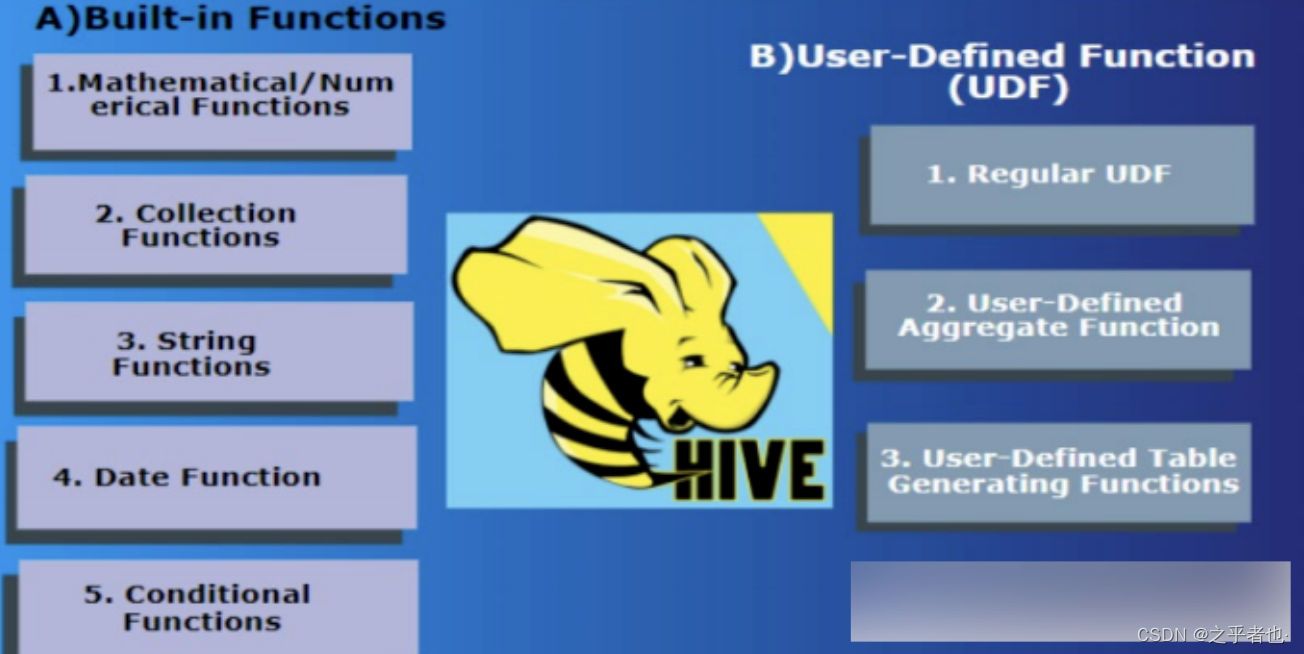
Hive是基于Hadoop的一个数据仓库工具,可以将结构化数据文件映射为一张数据库表,并提供类SQL语句操作。Hive内置了很多函数,可以满足基本的查询需求,同时还支持自定义函数(UDF)来实现更加灵活的操作。
官方文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
下面简单介绍Hive内置函数和UDF的相关内容:
1)内置函数
Hive内置函数主要用于集合函数、数学函数、日期函数、字符串函数和条件判断函数等方面。例如:
-
条件判断函数:
IF、WHEN、CASE、COALESCE等。 -
字符串函数:
LENGTH、SUBSTR、CONCAT、TRIM、LOWER、UPPER等; -
集合函数:
SUM、MAX、MIN、AVG、COUNT等; -
数学函数:
ROUND、EXP、LOG、SIGN等; -
日期函数:
YEAR、MONTH、DAY、HOUR、MINUTE、SECOND等;
2)自定义函数(UDF)
除了Hive内置函数之外,用户还可以自定义函数来实现更加灵活的操作。 Hive支持三种类型的自定义函数:
-
标量函数(
UDF):将一行中的一个值转换为另外一个值,比如字符串转小写; -
集合函数(
UDAF):作用于多个值上,并且返回一个结果,比如平均值; -
行级别函数(
UDTF):将一行中的一个或多个字段转换为多行,比如对一行中的字符串进行单词切分。
自定义函数用Java语言编写,需要继承Hive提供的UDF、UDAF或UDTF类,然后实现相应的方法。例如,下面是一个自定义的UDF函数,用于将字符串转为小写:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class Lowercase extends UDF {
public Text evaluate(Text str) {
if (str == null) {
return null;
} else {
return new Text(str.toString().toLowerCase());
}
}
}
以上是简单介绍Hive内置函数和UDF的相关内容,使用Hive内置函数可以满足常用的查询需求,而自定义函数可以更加灵活地满足特定的业务需求。
二、环境准备
如果已经有了环境了,可以忽略
# 登录容器
docker exec -it hive-hiveserver2 bash
# 连接hive
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
三、Hive 内置函数
先创建一张表来测试
# 登录容器
docker exec -it hive-hiveserver2 bash
# 登录hive客户端
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
# 建表
CREATE EXTERNAL TABLE external_table1 (
column1 STRING,
column2 INT,
column3 DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/hive/external_table/data';
添加数据
# 登录容器
docker exec -it hive-hiveserver2 bash
# 模拟一些数据
cat >data<<EOF
c1,12,56.33
c2,14,58.99
c3,15,66.34
c4,16,76.78
EOF
# 登录hive客户端
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
# 加载数据,local 是加载本机文件数据
load data local inpath './data' into table external_table1;
1)条件判断函数
1、If函数: if
语法:
if(boolean testCondition, T valueTrue, T valueFalseOrNull)
# 返回值: T
# 说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











