




==========================================================================
上周生病再加上课余的一些琐事,这边的进度就慢下来了,本篇笔记基于 斯坦福大学公开课cs229 的 lecture16,lecture 17
==========================================================================
零:一些认识
涉及到机器人的操控的时候,很多事情可能并不是supervised和unsupervised learning能够解决的,比如说andrew ng之前一直提到的自动控制直升飞机,另一个例子就是下棋,有可能很久之前的一步棋就埋下了后面失败的伏笔,而机器很难去判断一步棋的好坏。这就是增强学习需要解决的问题。
注:这里的Value价值即是很多书上写的Q值,貌似也有点差别,在于Q可能是Q(s,a)的,是给定状态和一个动作之后的V值,但差异不大。
一:马尔科夫决策过程 (Markov decision processes)
马尔科夫决策是一个五元组,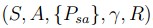 ,用一个机器人走地图的例子来说明它们各自的作用
,用一个机器人走地图的例子来说明它们各自的作用
S:状态集:就是所有可能出现的状态,在机器人走地图的例子中就是所有机器人可能出现的位置
A:action,也就是所有可能的行动。机器人走地图的例子假设机器人只能朝四个方向走,那么A就是{N,S,E,W}表示四个方向
P:就是机器人在S状态时采取a行动的概率
γ:叫做discount factor,是一个0到1之间的数,这个数决定了动作先后对于结果的影响度,在棋盘上的例子来说就是影响了这一步
棋对于最结果的影响有多大可能说起来比较模糊,通过后面的说明可能会讲得比较清楚。
R:是一个reward function,也就是可能是一个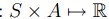 ,也可能是
,也可能是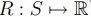 ,对应来说就是地图上的权值
,对应来说就是地图上的权值
======
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









