



 本文介绍了Apache Flink作为流处理引擎的主要特点和应用场景,包括低延迟、高吞吐、事件时间和处理时间语义等。通过实例展示了如何在电商、物联网、电信和金融等行业中应用Flink进行数据处理。同时,提供了批处理和流处理的Java代码示例,以及如何通过监听socket实时获取和处理数据。
本文介绍了Apache Flink作为流处理引擎的主要特点和应用场景,包括低延迟、高吞吐、事件时间和处理时间语义等。通过实例展示了如何在电商、物联网、电信和金融等行业中应用Flink进行数据处理。同时,提供了批处理和流处理的Java代码示例,以及如何通过监听socket实时获取和处理数据。
Flink入门
你未必出类拔萃,但一定与众不同
文章目录
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
选择Flink
-
流数据更真实地反映了我们的生活方式
-
传统的数据结构是基于有限数据集的
我们的目标
- 低延迟
- 高吞吐
- 结果的准确性
- 良好的容错性
需要处理流数据的行业
-
电商和市场营销
数据报表 广告投放 业务流程需要
-
物联网IOT
传感器实时数据采集和显示 实时报警 交通运输业
-
电信业
基站流量调配
-
银行和金融业
实时结算和通知推送,实时检测异常行为
Flink 的主要特点
事务驱动
基于流的世界观,一切都是由流组成的,离线数据是有界的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流
分层API
越顶层越抽象,表达含义越简明,使用越方便
越顶层越具体,表达能力越丰富,使用越灵活
支持事件时间和处理时间语义
精确一次的状态一致性保证
低延迟,每秒处理数百万个事件毫秒级延迟
与众多常用存储系统的连接
高可用 动态扩展 实现7*24小时全天候运行
安装flink
1.前往官网下载flink https://flink.apache.org/downloads.html
这里下载的是1.8.1
链接:https://pan.baidu.com/s/1lHZSstEuSYXyHLhBIXIi1g
提取码:1234
2.下载成功后解压缩到当前文件夹。使用cmd进入命令窗口 进入bin目录下 运行 start-cluster.bat


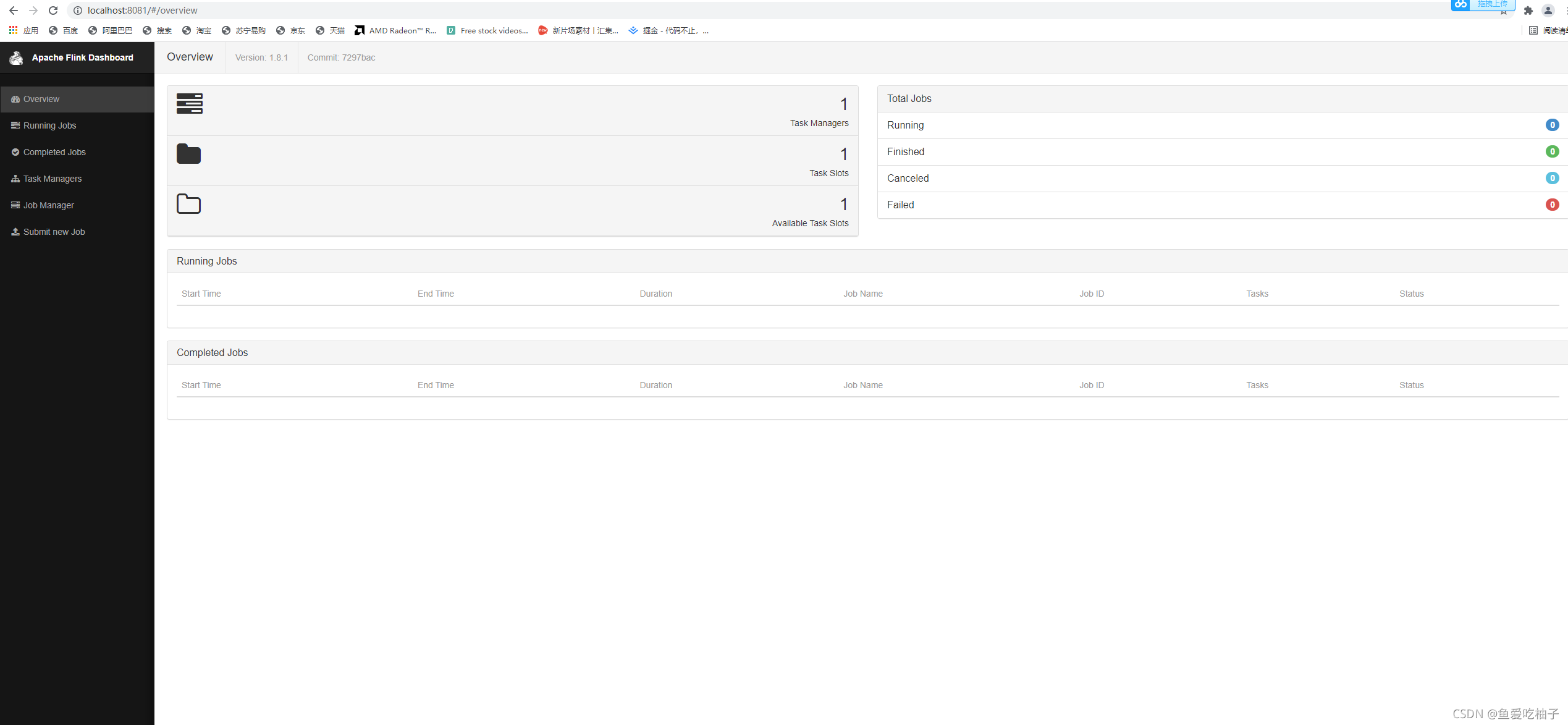
3.访问http://localhost:8081 访问成功即是下方页面
flink简单上手
1.打开idea 创建maven项目 写入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
test.txt
Life is always let us was black
and blue all over but afterwards
the injured local will become our most strong place
Every adversity
every failure
every heartache carries with
it the seed on an equivalent or greater benefit
2.批处理
public class WordCount {
public static void main(String[] args) throws Exception {
//创建执行环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
//从文件读取数据
String inputSrc = "E:\\JavaProject\\flink\\FlinkTutorial\\src\\main\\resources\\test.txt";
DataSet<String> stringDataSource = environment.readTextFile(inputSrc);
//对数据集进行处理,按空格分词展开,转换成
DataSet<Tuple2<String, Integer>> resultSet = stringDataSource.flatMap(new MyFlatMapper())
.groupBy(0) //按照第一个位置的word分组
.sum(1); //将第二个位置上的数据求和
resultSet.print();
}
//自定义类。实现FlatMapFunction
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String,Integer>>{
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
//按空格进行分词
String[] words = s.split(" ");
for (String word : words) {
collector.collect(new Tuple2<String, Integer>(word,1));
}
}
}
}
3.流处理
public class StreamWordCount {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置线程并行数
environment.setParallelism(8);
//从文件读取数据
String inputSrc = "E:\\JavaProject\\flink\\FlinkTutorial\\src\\main\\resources\\test.txt";
DataStream<String> stringData = environment.readTextFile(inputSrc);
//基于数据流进行转换计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultSet = stringData.flatMap(new WordCount.MyFlatMapper())
.keyBy(0) //按照第一个位置的word分组
.sum(1); //将第二个位置上的数据求和
resultSet.print();
environment.execute();
}
}
4.输出结果
批处理结果
(an,1)
(Life,1)
(black,1)
(let,1)
(or,1)
(carries,1)
(every,2)
(always,1)
(will,1)
(afterwards,1)
(and,1)
(equivalent,1)
(local,1)
(seed,1)
(Every,1)
(greater,1)
(benefit,1)
(on,1)
(all,1)
(injured,1)
(blue,1)
(failure,1)
(is,1)
(us,1)
(with,1)
(our,1)
(strong,1)
(heartache,1)
(most,1)
(place,1)
(the,2)
(adversity,1)
(become,1)
(but,1)
(it,1)
(over,1)
(was,1)
流处理结果
7> (with,1)
8> (is,1)
1> (it,1)
7> (always,1)
3> (blue,1)
2> (on,1)
8> (let,1)
6> (afterwards,1)
4> (every,1)
3> (all,1)
6> (strong,1)
3> (over,1)
5> (Life,1)
5> (us,1)
5> (was,1)
4> (heartache,1)
5> (carries,1)
1> (greater,1)
2> (equivalent,1)
8> (black,1)
7> (become,1)
8> (and,1)
8> (but,1)
8> (injured,1)
7> (adversity,1)
8> (an,1)
3> (local,1)
6> (or,1)
3> (will,1)
3> (our,1)
2> (Every,1)
5> (the,1)
4> (seed,1)
5> (most,1)
4> (benefit,1)
3> (place,1)
6> (failure,1)
5> (the,2)
4> (every,2)
监听socket实时获取数据
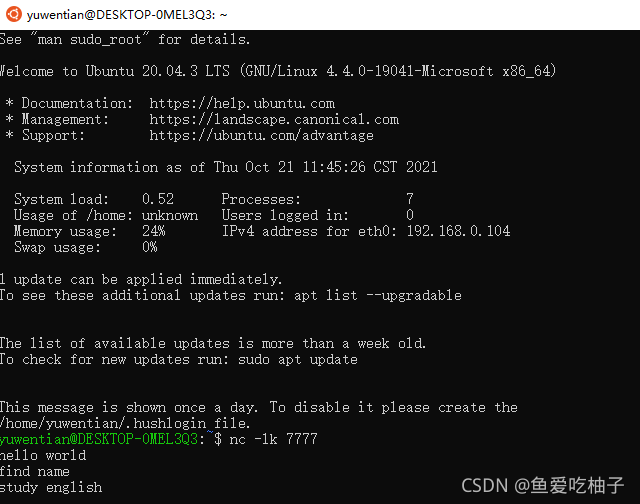
1.启动ubuntu 输入 nc -lk 7777 开启监听模式,用于指定nc将处于监听模式。
2.修改maven中的代码
public class StreamWordCount {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置线程并行数
environment.setParallelism(8);
//从socket文本流读取数据
DataStream<String> inputDataStream = environment.socketTextStream("localhost",7777);
//基于数据流进行转换计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultSet = inputDataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0) //按照第一个位置的word分组
.sum(1); //将第二个位置上的数据求和
resultSet.print();
environment.execute();
}
}
3.实时打印输出
3> (hello,1)
5> (world,1)
4> (find,1)
4> (name,1)
1> (english,1)
5> (study,1)


















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











