




MOSS-MED: Medical Multimodal Model Serving Medical Image Analysis

目录
1. 引言
近年来,人工智能(AI)技术的飞速发展,特别是大型语言模型(LLMs)的崛起,使其在自然语言生成、指令理解和世界知识理解方面取得了显著成果。为扩展LLM的应用范围,研究者提出了多模态 LLM(MLLM),将视觉和音频等模态整合到语言模型中,使其在多模态场景中具有出色的理解和推理能力。
MOSS-MED 致力于医学图像分析这一具有挑战性的领域。医学图像涵盖 CT、X 光、超声、MRI 和病理切片等多种模态,涉及不同的器官和身体部位,这些图像具有复杂的视觉特征。MOSS-MED 旨在结合视觉理解和医学知识,为医学图像分析提供精准的辅助诊断和报告生成能力。
MOSS-MED 系列包括两款模型:
- MOSS-MED-2.5B:基于 MOSS2-2.5B-chat 语言模型。
- MOSS-MED-LLaMA:基于 LLaMA2-7B-chat 语言模型。
通过两阶段训练流程(通用领域与医学领域),MOSS-MED 实现了对医学图像的深度理解,尤其在生物医学视觉问答(VQA)任务中表现出色。
2. 相关工作
2.1 面向医学的大型模型
面向医学的大型模型通常根据输入模态和任务需求分为三类:
- 文本模态模型:仅处理文本输入,生成文本输出。这类模型通过在医学领域数据(如临床文本和医学论文)上进行预训练或微调,可用于疾病咨询、药物推荐等任务。
- 视觉模态模型:专注于医学图像任务,如图像分割和分类。研究者利用大规模视觉编码器,专门优化医学领域的分割和分类任务,帮助医生定位异常区域。
- 多模态模型:同时处理文本和视觉数据。例如,部分模型能为医学图像生成病例报告,并回答用户提出的相关问题。这类模型大大拓展了医学 AI 的应用范围。
2.2 视觉聊天机器人
视觉聊天机器人允许用户通过视觉输入与机器交互。借助 LLM 的强大生成和推理能力,这类机器人能够理解图片内容并用自然语言进行回答。
集成视觉编码器(如 ViT)和 LLM 的视觉聊天机器人通常通过一个可学习的接口模块将视觉特征映射到语言特征空间。这种架构在训练初期会使用大量图文配对数据进行视觉-文本对齐,随后通过指令微调提升模型对人类指令的理解和响应能力。
2.3 生物医学视觉问答(VQA)
生物医学 VQA 任务旨在基于医学图像回答相关问题,主要分为两类方法:
- 判别式方法:从预定义的候选答案集中选择最优答案。这类方法适用于封闭式问题,但难以处理开放式问题。
- 生成式方法:通过生成文本来回答问题,能够处理开放式和封闭式问题。这类方法可直接利用 LLM 的生成能力,生成更自然的回答。
3. 方法
3.1 模型架构
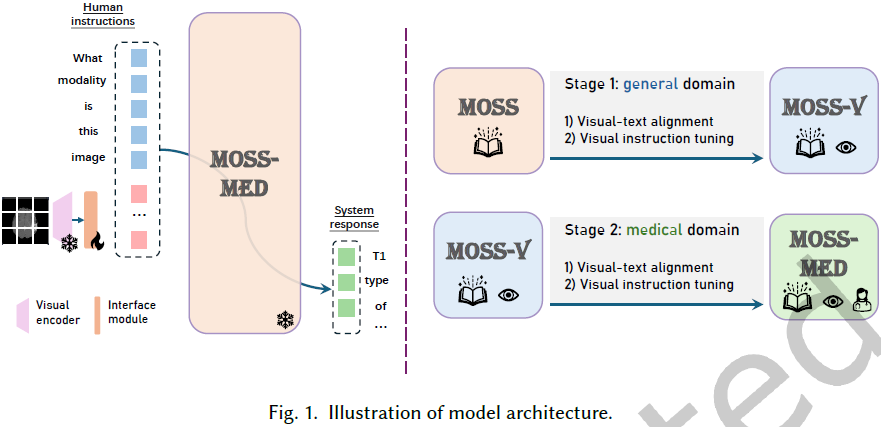
MOSS-MED 的模型架构包含三个主要组件:
- 视觉编码器:使用 CLIP 预训练的 ViT-L/14 模型,将图像转换为特征向量。
- 语言模型:MOSS2-2.5B-chat(用于 MOSS-MED-2.5B)和 LLaMA2-7B-chat(用于 MOSS-MED-LLaMA)。
- 接口模块:一个两层投影模块,将视觉特征映射到语言模型的嵌入空间,实现视觉-语言对齐。
3.2 数据格式
所有训练数据以标准化格式表示,每条数据样本为一个基于 2D 图像的人机对话,例如:
- 人类输入:图像 + 问题
- 系统输出:回答

3.3 训练流程
MOSS-MED 采用两阶段训练流程:
阶段 1:通用视觉能力扩展
- 视觉-文本对齐:使用图文配对数据训练接口模块,将视觉特征映射到语言特征空间。
- 视觉指令微调:通过指令数据微调接口模块和语言模型,提升模型理解和遵循指令的能力。
阶段 2:生物医学视觉能力扩展
- 生物医学视觉-文本对齐:与阶段 1 相似,使用医学图像及对应描述进行视觉-文本对齐。
- 生物医学视觉指令微调:与阶段 1 相似,利用医学指令数据集进行微调,使模型能更准确地回答医学相关问题。
4. 实验
4.1 训练目标
采用标准的语言建模目标——下一个 token 预测任务。损失函数为:
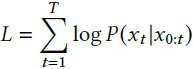
其中,x_t 为第 t 个 token,T 为序列长度。
4.2 训练细节
1)数据集:
阶段 1:
- 图文对齐:3.5M 张图文配对(来自 Conceptual Captions 和 SBU Captions)。
- 指令微调:880K 条来自 LVIS-INSTRUCT4V 的指令数据。
阶段 2:
- 医学图像-描述对齐:650K 条医学图像-描述配对(来自 PMC-OA、Quilt-1M 和 ROCOv2)。
- 医学指令微调:160K 条指令数据(来自 LLaVA-Med 和 Quilt-LLaVA)。
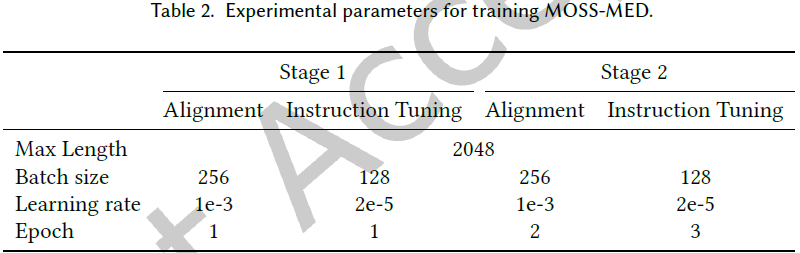
训练参数:使用 8 块 80GB 显存的 GPU 进行训练,采用 DeepSpeed 框架。
5. 生物医学视觉专长评估
5.1 评估详情
使用三大生物医学视觉问答(VQA)基准测试 MOSS-MED:
- pathVQA:病理学 VQA 数据集,包含开放式和封闭式问题。
- VQA-RAD:放射学 VQA 数据集,同样包含两类问题。
- SLAKE:大规模双语医学 VQA 数据集,本实验使用英文部分。
5.2 评估结果
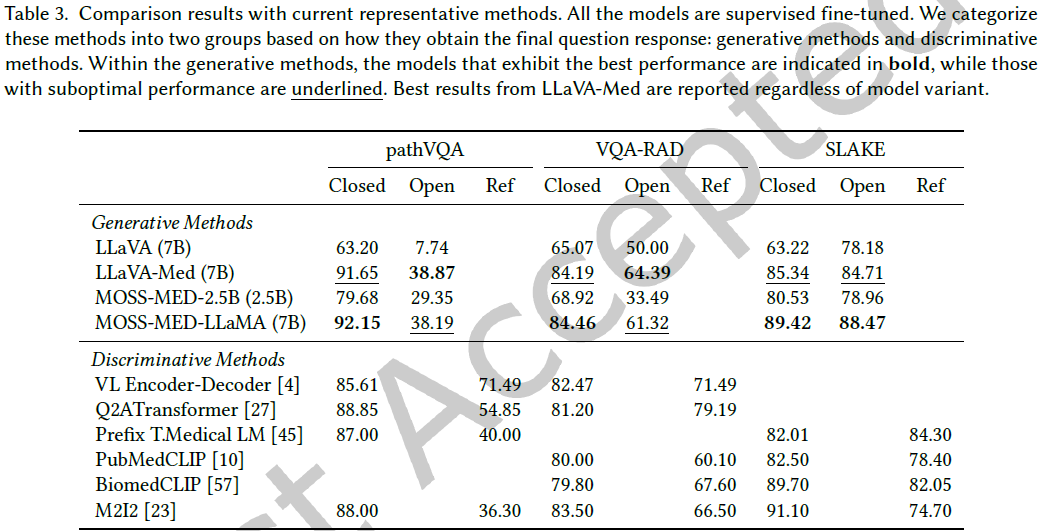
MOSS-MED-LLaMA 在封闭式(Closed)问题上的表现优于同类模型,在开放式(Open)问题上也表现突出。
与判别式方法(Discriminative Methods)相比,生成式方法(Generative Methods)的灵活性更强,能生成更详细的答案。
5.3 消融研究
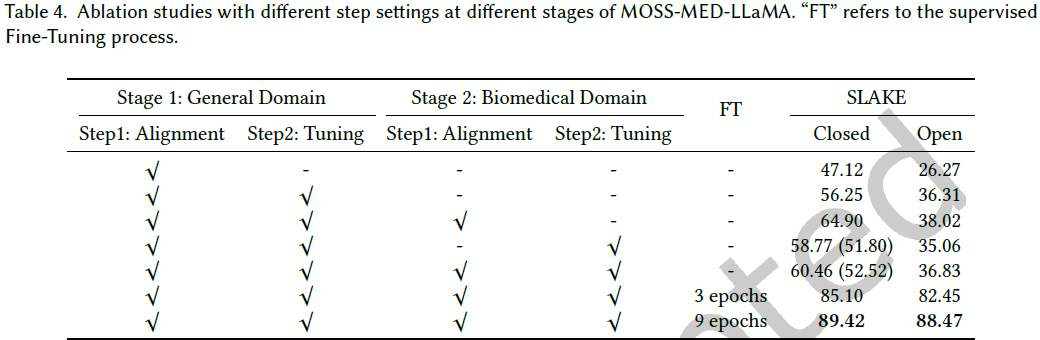
实验表明:
- 生物医学领域对齐对模型性能有显著提升。
- 阶段 1 的指令微调有助于提升模型对复杂指令的理解能力。
- 数据分布差异可能影响性能,例如指令微调数据与测试集的分布不一致时,模型表现会下降。
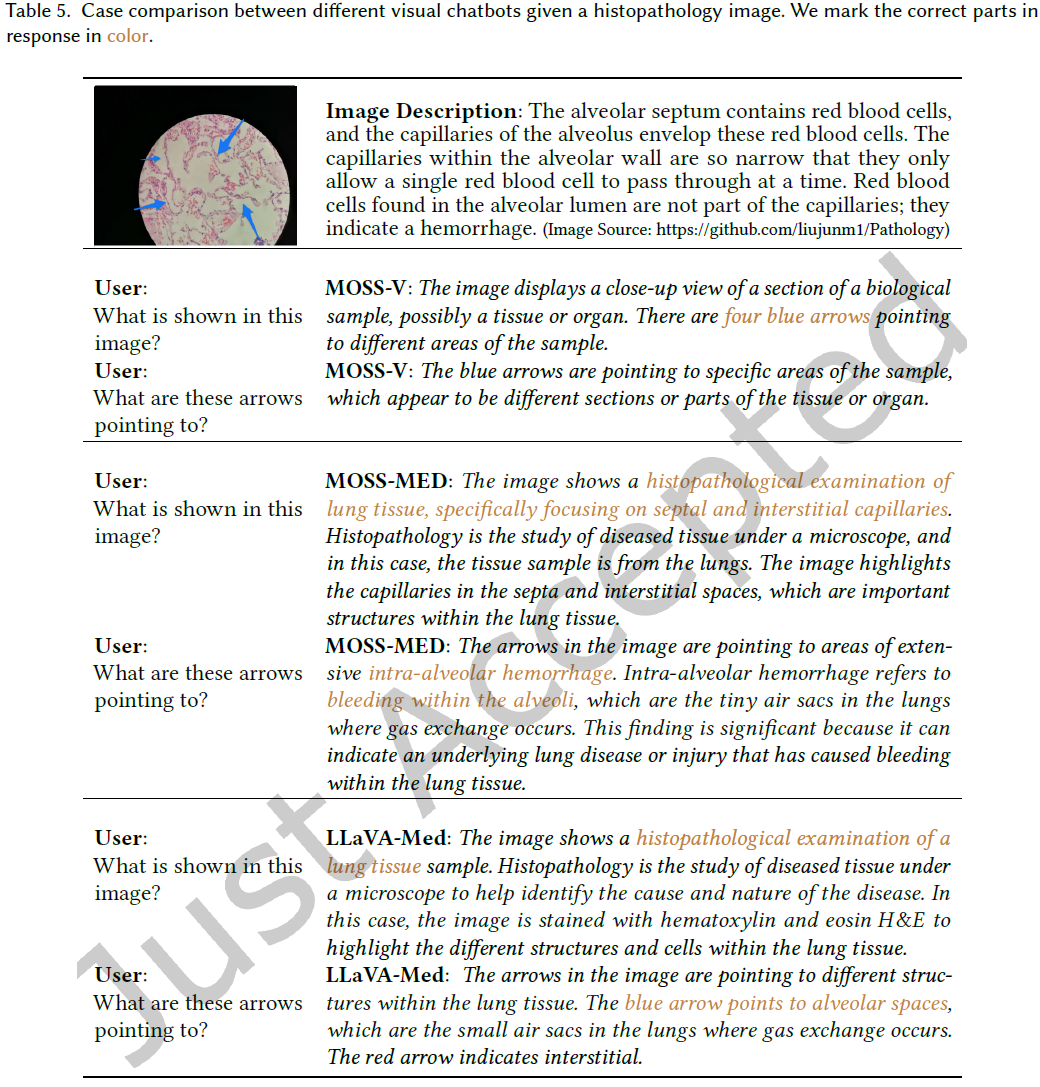
5.4 案例比较
MOSS-MED-LLaMA 能准确分析医学图像并提供详细描述。例如,在病理图像分析中,MOSS-MED-LLaMA 能指出肺部出血的可能性,而其他模型仅能给出一般描述。
6. 结论
本文提出 MOSS-MED,一款专注于医学图像分析的多模态大型语言模型。通过两阶段训练流程,MOSS-MED 实现了对医学图像的精准理解,尤其在生物医学 VQA 任务中表现出色。
未来工作:
- 提升视觉-语言对齐的质量。
- 采用更先进的图像编码器。
- 探索模型扩展规律以进一步提升性能。
论文地址:https://dl.acm.org/doi/10.1145/3688005
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









