




The Curse of Depth in Large Language Models
![]()

目录
1. 引言
本文提出了 “深度诅咒(The Curse of Depth)” 概念。
- 深度诅咒是观察到的现象,即 现代大型语言模型 (LLM) 中较深的层对学习和表示的贡献与较早的层相比要小得多。
- 这些较深的层通常表现出 对剪枝(pruning)和扰动的显着鲁棒性,这意味着它们 无法执行有意义的转换。
- 这种行为阻止这些层有效地促进训练和表示学习,从而导致资源效率低下。
- 研究确认,这一现象在 LLaMA、Mistral、DeepSeek 和 Qwen 等流行 LLM 中广泛存在。
理论与实证分析表明,导致 深层网络层低效 的原因是广泛使用的 前层归一化(Pre-Layer
Normalization,Pre-LN)。尽管 Pre-LN 稳定了 Transformer LLM 的训练,但其输出方差随着模型深度呈指数增长,导致深层 Transformer 块的导数趋近于单位矩阵,从而对训练贡献甚微。
为解决此问题,本文提出 “层归一化缩放(LayerNorm Scaling)”,通过按层深度平方根的倒数缩放归一化输出方差,显著提升了深层 Transformer 层的训练贡献。实验覆盖 130M 至 1B 参数规模,结果显示该方法在 LLM 预训练和监督微调中均优于 Pre-LN。
1.1 关键词
深度诅咒(Curse of Depth);预层归一化(Pre-Layer Normalization);层归一化缩放(LayerNorm Scaling);大型语言模型(Large Language Models);Transformer
2. 深度诅咒的实证证据
本文在多个 LLM 上进行层剪枝(pruning)实验,评估 Pre-LN 与 Post-LN 模型的深层网络层有效性。选取BERT-Large(Post-LN)、Mistral-7B、LLaMA2-7B/13B、DeepSeek-7B 和 Qwen-7B(均为 Pre-LN)进行分析,采用 性能下降指标 ∆P^(ℓ) 量化每层对模型整体性能的贡献。
![]()
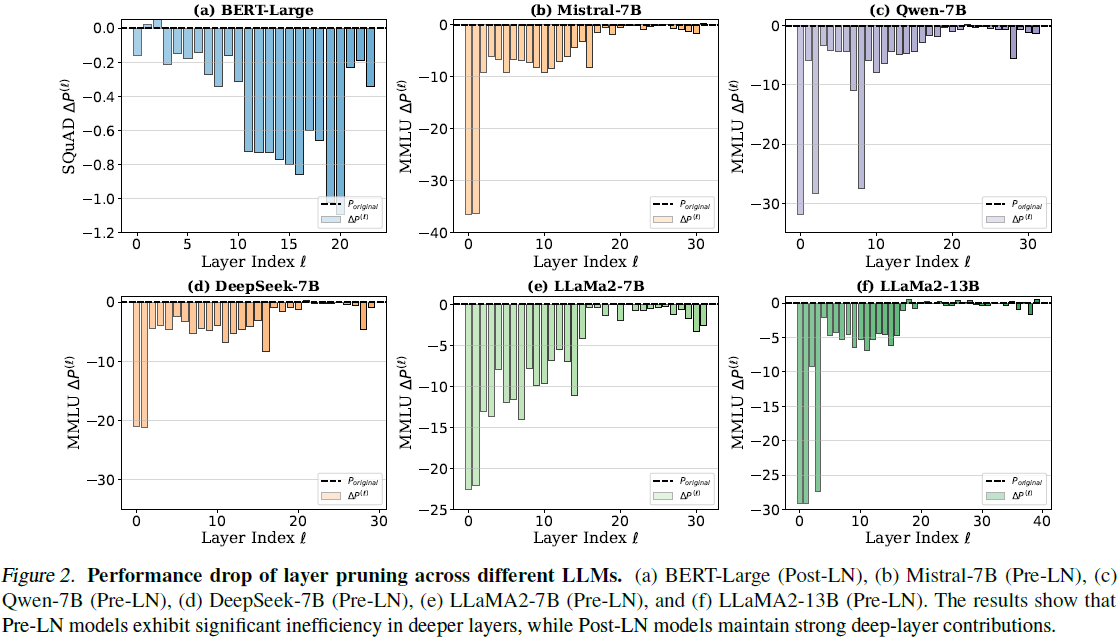
实验显示,
- BERT-Large(Post-LN)的深层剪枝显著影响性能,而其他模型(Pre-LN)的深层剪枝影响甚微,说明其深层贡献较小。
- 此外,随着模型规模增大,深浅层差异更为明显,凸显了深度诅咒对资源利用的挑战。
3. 深度诅咒分析
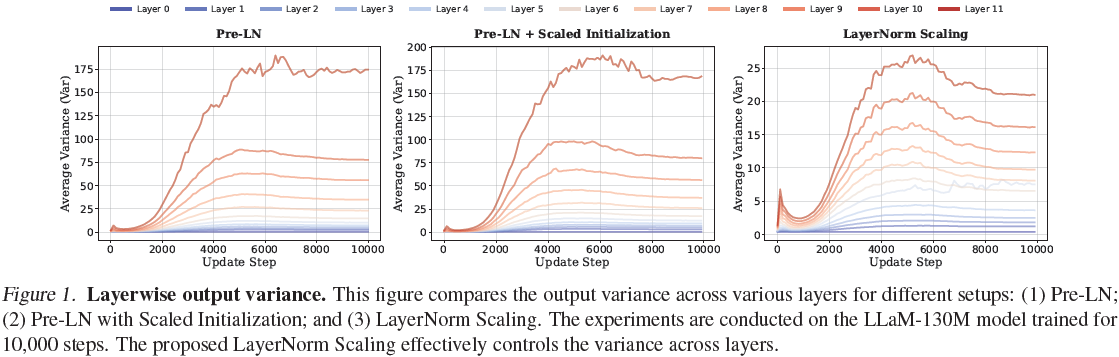
Pre-LN Transformer 中,输出方差随着深度呈指数增长(推导见原论文),使得深层梯度接近单位映射,限制了表达能力。
Post-LN Transformer 通过后层归一化保持各层方差恒定,梯度稳定性更高,但训练深层 Transformer 时易出现梯度消失。
4. 层归一化缩放
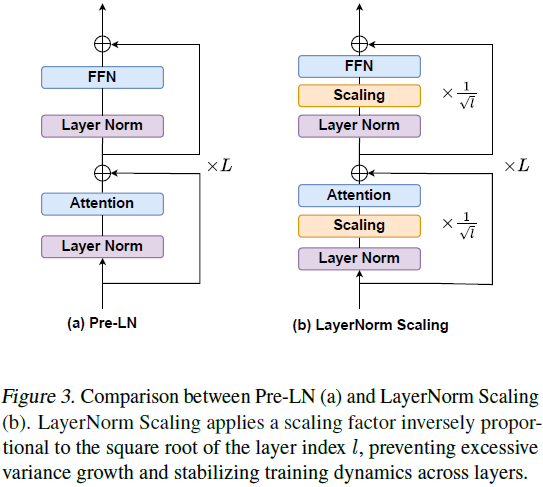
层归一化缩放通过在每层归一化输出上施加与层深度平方根成反比的缩放因子,将方差上界从指数级降低至多项式级(推导见原论文),稳定了训练动态。
相比于其他归一化方法(如 Mix-LN、DeepNorm 等),该方法无需额外超参数,计算高效且易于集成。
5. 实验
实验对比了 LayerNorm Scaling 与 Post-LN、Pre-LN、DeepNorm、Mix-LN 等方法在 130M、250M、350M 和 1B 参数规模下的性能。
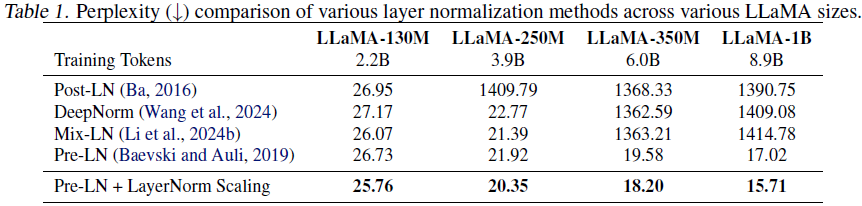
LayerNorm Scaling 在所有模型中均表现出最低的困惑度(Perplexity),尤其在 1B 模型中保持稳定训练,而 Mix-LN 在此规模下难以收敛。

与 Admin、Sandwich-LN 和 Group-LN 等方法的对比中,LayerNorm Scaling 的表现最佳,困惑度低于所有其他方法。
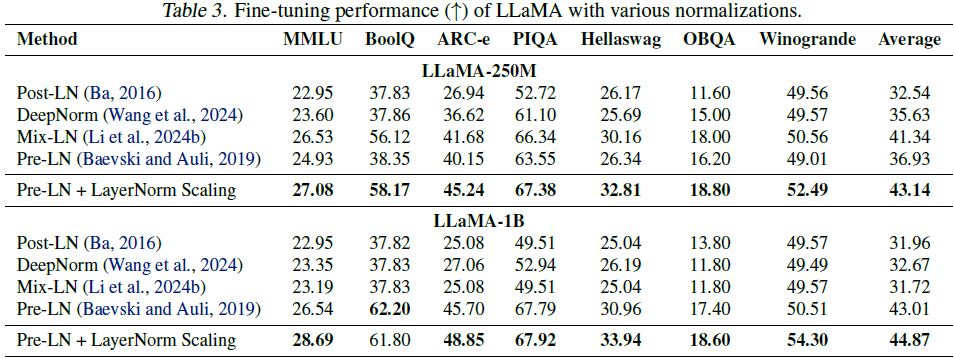
监督微调实验采用 Commonsense170K 数据集,涵盖 8 个下游任务,LayerNorm Scaling 在 250M 和 1B 模型上均取得了最高平均性能提升,尤其在 ARC-e 任务上,相比 Mix-LN 分别提升了 3.56% 和 3.15%。
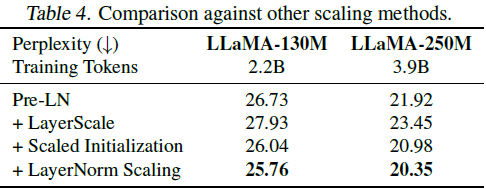
输出方差分析表明,LayerNorm Scaling 显著减少了深层输出方差,相比 LayerScale 和 Scaled Initialization 方法效果更优。
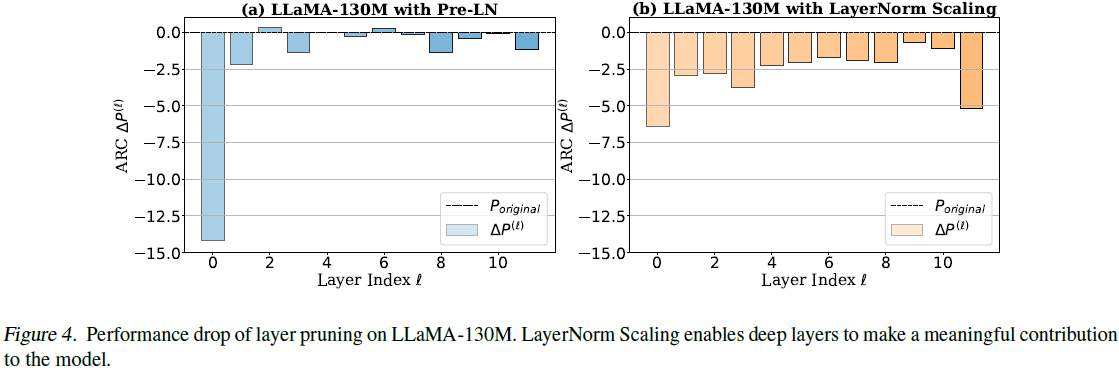
层剪枝实验进一步证实,采用 LayerNorm Scaling 的深层剪枝对性能影响更大,说明深层在训练中发挥了更积极的作用,验证了其在缓解深度诅咒、提高深层网络层有效性方面的有效。
6. 相关工作
最初,Vaswani 等人在 Transformer 架构中采用了残差连接后的 层归一化(Post-LN),但 Baevski 和 Auli、Dai 等人引入的 前层归一化(Pre-LN)逐渐成为主流,因其在深层 Transformer训练中的稳定性和性能优势。
Xiong 等人证明了 Post-LN 在输出层附近会产生较大梯度,需更小的学习率稳定训练,而 Pre-LN 能随着深度增加有效缩减梯度,适用于深层 Transformer。
Wang 等人验证了 Pre-LN 有助于堆叠更多层,而 Post-LN 易出现梯度消失问题。
此前的研究还包括 Bapna 等提出的多层连接、Liu 等的自适应模型初始化(Adaptive Model Initialization,Admin)用于稳定 Post-LN 残差依赖,以及 Wang 等提出的 DeepNorm,通过在归一化前对残差进行放大支持 1000 层 Transformer。
Ding 等提出的 Sandwich-LN 在每个子层输入输出均进行归一化,Takase 等的 B2T 方法跳过除最终层外的所有归一化。
Li 等提出的 Mix-LN 结合了 Pre-LN 和 Post-LN 以增强中间层性能,反映了社区在提升深层网络层训练稳定性和有效性方面的持续努力。
论文地址:https://www.arxiv.org/abs/2502.05795
项目页面:https://github.com/lmsdss/LayerNorm-Scaling
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









