




自然语言处理
自然语言处理是语言学的一个分支,侧重于对人类语言的词法、语法、语句等的研究。在计算机领域,主要用来研究,如何让计算机处理、生成甚至理解人类的语言,并且多种语言的传统学习任务也逐将被机器所代替。
一. sklearn 的特征提取
1.使用DictVectorizeier对字典的数据特征进行抽取与向量化
- 模块导入
from sklearn.feature_extraction import DictVectorizer
- 创建DictVectorizer模型
dvc = DictVectorizer()
- 创建一个列表l,列表中的元素为字典

- 用dvc 来进行训练

在该数据中,city和landmark都是字符串类型的数据,不可以参与到运算,因此把city这一个属性
拆成了6个,把landmark一个属性拆成了6个,每个属性代表city挥着landmark的一个取值, 如果是具体的数字, 类型则不变
- 把矩阵转成数组,使用 toarray() 方法
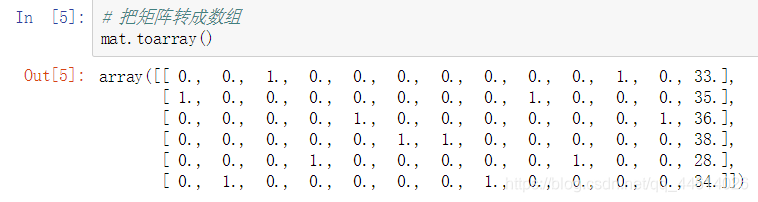
查看每个属性列的含义

2. 使用CountVectorizer并且不去掉停用词条的条件下,对文本进行向量化
- 导入数据集模块
from sklearn import datasets
-
从datasets中下载新闻文本
由于是在线下载,数据量比较大,耗时可能会有点长,且界面会比以往略有卡顿

-
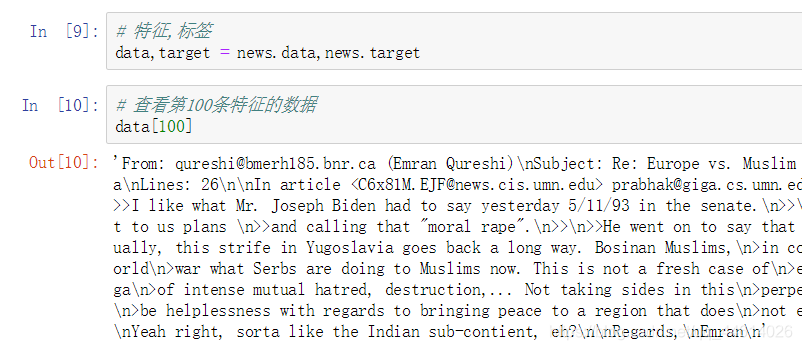
取出特征和标签
-
分离测试集与训练集

查看一下训练特征的数据
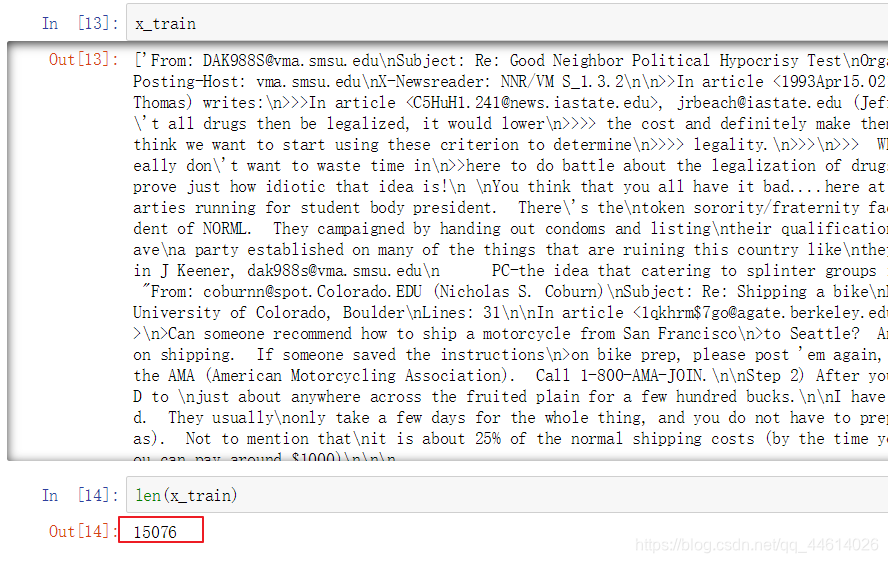
一般情况下不建议直接查看,因为数据量大,耗时且容易卡顿,
使用 len() 查看数据长度(也就是数据量),有15076条数据 -
创建CountVectorizer模型

-
训练并转换x_train

-
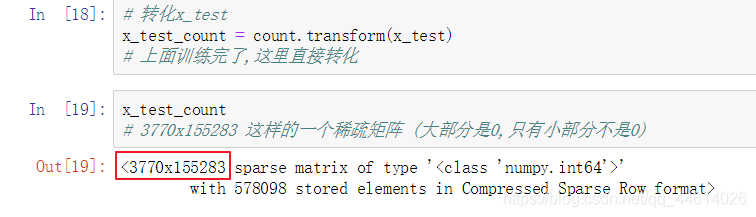
转化x_test
-
将稀疏矩阵转为数组
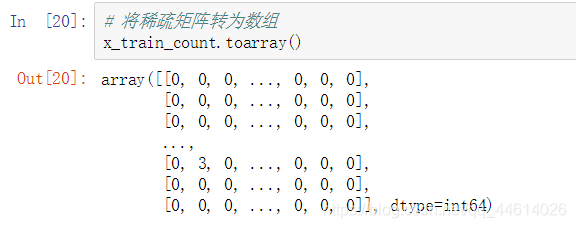
CountVectorizier模型,在进行训练的时候,首先会统计训练集上总共有多少种词汇,对每一种词汇都是一个特征(例如:上例中所有的训练数据中有155283种词汇,每一个词都是一个特征,一句话中如果出现了n次某种词汇,就会把该词汇对应的属性设置为n)
3.用TfidVectorizier来进行去掉停用词的情况下的特征提取
什么叫停用词呢?就是这个词语,在这句话中没有什么含义,那么这个词的特征就不出现了,这个特征就为0处理,这样会比上面不去掉停用词更加智能
-
创建 TfidfVectorizer 模型

-
训练并转换x_train,转化x_test
二. NLTK
模块安装
pip install nltk
1.词袋法
用sklearn中的CountVectorizier和TfidVectorizier来进行特征提取
这两种方法的提取:就是把整个数据集上的所有的语句中的词汇设置成特征,然后将每一句话的单词出现的次数映射对应的词汇上
- 先创建三句话,类型都为string类型

- 创建CountVectorizer模型

- 将第一句话和第二句话组合起来
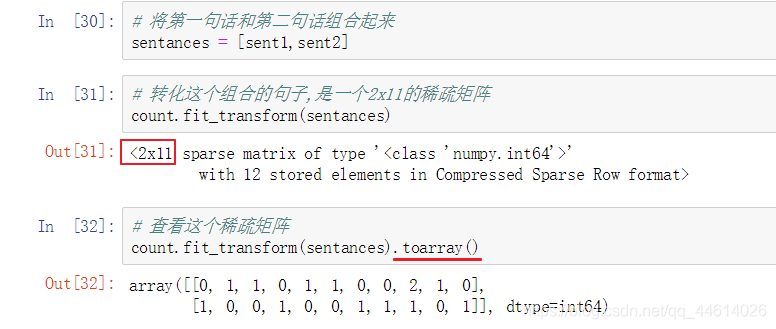
- 进行特征提取,提取词汇

这个特征有什么特点呢?
这里一共有11个单词,对应稀疏矩阵中2x11中的11
稀疏矩阵由两句话组成,对应x11中的2
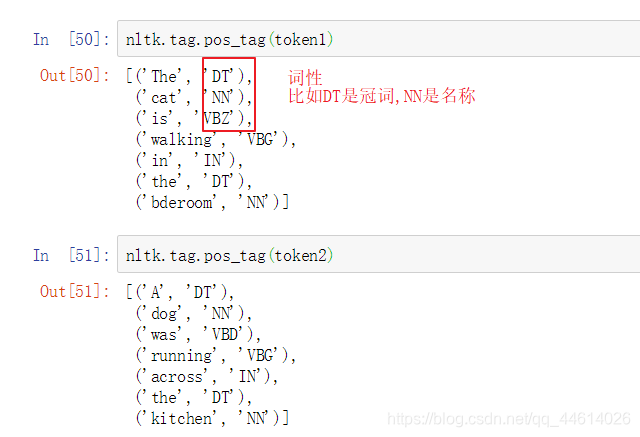
第一句话中 “The cat is walking in the bderoom” 没有across这个单词,所以稀疏矩阵第一行第一列的元素用0表示,而对应的bedroom这个单词,第一行第一列中为1,恰好第一句话中有这个单词
2.用NLTK处理
- 导入模块
import nltk
-
用NLTK来做词语的切分

分别对三句话做了词语的切分 -
寻找每一句话的词根
3.1 初始化一个Stemmer对象,寻找原始词根

3.2 分别对以上三句话寻找原始词根

-
对每一个词汇进行标注,在使用之前首先要下载如下内容
由于是在线下载,可能会耗费些时间
调用一下tag.pos_tag()这个函数
三 . 向量词(Word2Vec)技术
词袋法,可以视作向量化技术,通过这种技术,可以对文本之间的内容进行一定度量. 如果对于两段文字来说,词袋法就表现的无能为力
查看新闻news的data
- 导入模块
from bs4 import BeautifulSoup
import re
import nltk
如果没有安装bs4模块,使用命令pip下载
- 用nltk在线下载词法分析包

这个包的下载过程会有点耗时,因为内容很多
下载之后,可以根据路径查看一下
语法分析包有很多,一般情况下只分析英文,这里的news的内容也是英文的
- 定义一个函数,用于将每条新闻中的句子逐一剥离出来,并且返回一个列表

- 将每条新闻都用定义的函数转化
5) 创建向量词转化模型

sentances参数, 要转化成向量词的语句
workers参数, 转化的时候用多少个cpu内核
size参数, 词向量的维度
min_count参数, 保证被考虑的词汇的频度
window参数, 定义训练词向量的上下文窗口大小
注意: 这个模型被创建出来以后就可以根据我们指定的参数来训练
model 的创建就伴随着训练,训练完以后,model中包含了一个300维的向量,
15w多种词汇量最终会根据相关程度合并到到300个维度中
- 利用训练好的模型来寻找和money相关的10个词汇
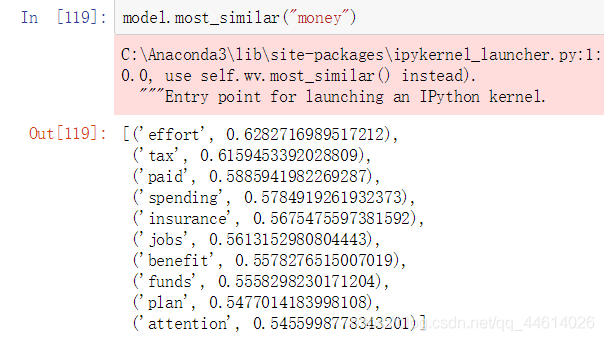
和money相关最大的词为effort 相关系数为0.62…
在不是用语言学字典的前提下,词向量技术仍然根据上下文信息,来查找词汇之间相似性;这一技术,不仅节省的大量的专业人员的操作,而且可以作为一个模型的基本应用,也可以用到更加复杂的自然语言处理中

















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









