




urllib框架
1、 在pycharm新建爬虫项目
新建一个python项目,可以新创一个环境变量,这个环境变量就专供爬虫的项目使用
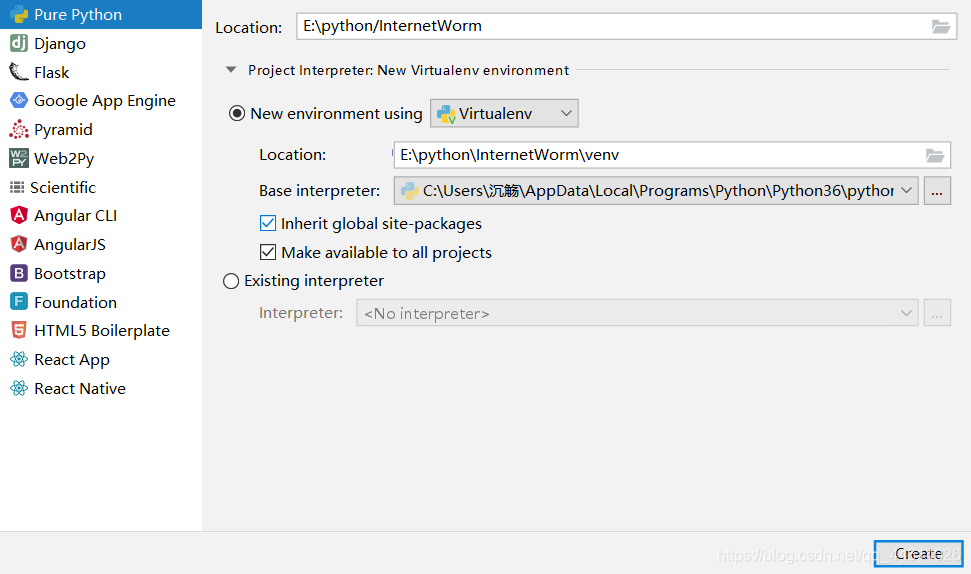
打开这个项目后,可以在项目根目录下创建一个空文件夹,比如新创一个文件夹day01,该文件夹下还能继续创建文件夹
以后创建的文件夹可以都和day01同级,这样这些代码就都在同一个项目中,使用的都是同样的环境变量,避免了每次都新建环境变量,且安装的包方便于使用
2、 爬虫urllib框架
urllib是python中的一个用于处理http请求以及url的工具,它是爬虫的一个基础框架,后面的requests、scrapy等框架都是基于urllib进行的二次封装
2.1 urlopen()
urlopen() 用于打开一个远程的url链接,并且向这个链接发起http请求,然后获取响应
myurllib .py
# 导入urllib框架
from urllib import request
url = "http://www.baidu.com/"
res = request.urlopen(url=url)
print(res)
# 得到的是一个对象 <http.client.HTTPResponse object at 0x0000023729DA8A58>
# 这个响应对象中包含响应头和响应体
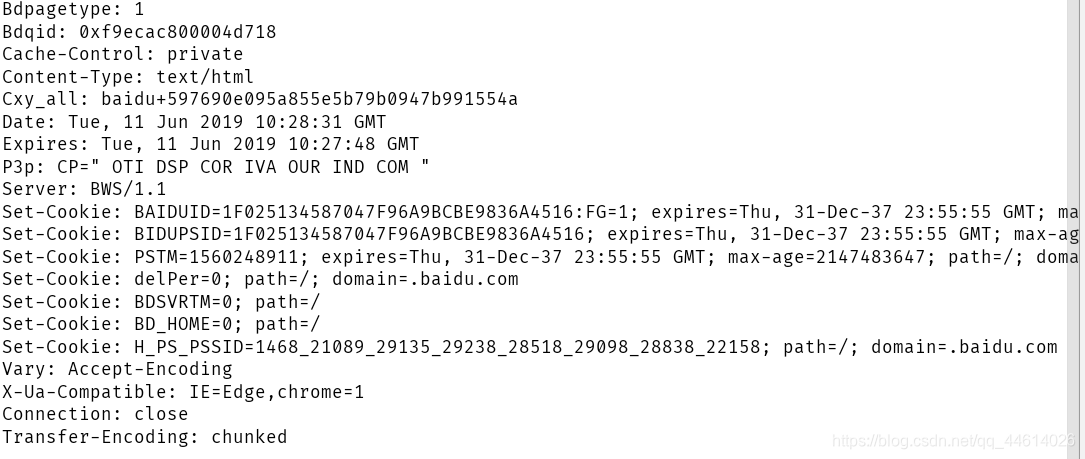
print(res.headers) # 打印响应头
print(res.url)
#打印url 得到的是 http://www.baidu.com/
print(res.status) #打印状态码 得到的是 200
# 读取响应体
# 1)读取所有的响应体并且整合成一个二进制的字符串
r1 = res.read()
print(r1.decode('utf-8'))
#得到的是百度的网页源代码
# 2)读取一行
r2 = res.readline()
print(r2)
r3 = res.readline()
print(r3)
# 3)读取多行
r4 = res.readlines()
print(r4)
# 用read系列的方法来读取的时候,每一次读取要接着上一次的断点继续
得到的响应头是这一段
2.2 urlretrieve(url,filename)
urlretrieve(url,filename) 用于打开url这个链接并且发起请求,把响应体写入到filename中
myurllib2 .py
# 导入urllib框架
from urllib import request
url = 'http://www.baidu.com/'
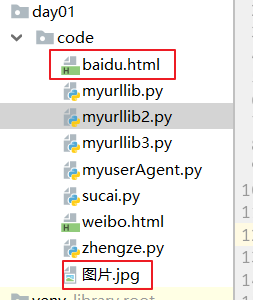
res2 = request.urlretrieve(url=url,filename='./baidu.html')
print(res2)
# 打印的是一个元组
#打开百度,随便找一张图片,将图片链接复制下来
img="http://pic9.nipic.com/20100923/2531170_140325352643_2.jpg"
request.urlretrieve(url=img,filename='./图片.jpg')
可以看到,这两个文件就被存储下来了
2.3 urlencode()
urlencode() 用于对url进行编码
url一般情况下不能接受汉字,需要将汉字编码成二进制,urlopen() 方法不能直接对url中的汉字进行编码
myurllib3 .py
# 导入urllib框架
from urllib import request
from urllib import parse
# 导入parse工具
url = 'http://www.baidu.com/'
# 首先将参数写出字典的形式
dic={
'ie':'utf-8',
'wd':'老王0',
}
# 然后用urlencode方法,编码成url的参数形式
data =parse.urlencode(dic)
print(data)
# 得到的是 ie=utf-8&wd=%E8%80%81%E7%8E%8B
# 拼接url
url +=data
request.urlopen(url=url)
print(url)
# url就变成了 http://www.baidu.com/ie=utf-8&wd=%E8%80%81%E7%8E%8B0
2.4 添加代理来伪装成浏览器
如果我们直接用urlopen方法爬取微博
from urllib import request
url = "https://weibo.cn/"
request.urlopen(url=url)
#会返回 urllib.error.HTTPError: HTTP Error 403: Forbidden
反爬之一: 用户代理;
在web开发中,同一url往往可以对应不同的界面信息(即用不同的终端来访问同一个url的时候,往往得到的数据不一样),后台可以根基前端的请求头中用户代理(user-agent)的不同来返回不同版本的数据;如果检测到前端的请求中没有用户代理,就认为是一个非法访问,就会拒绝
解决方案:添加代理来伪装成浏览器
myuserAgent .py
from urllib import request
url = 'https://weibo.cn/'
# 添加代理来伪装浏览器
# 1 创建Request对象
req = request.Request(url=url,headers={'User-Agent':' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'})
# 用Request对象伪装浏览器
# 2 用加入了请求头的Requset对象来发起请求
res = request.urlopen(req)
print(res)
# 把响应体写入本地
with open('weibo.html','wb') as fp:
fp.write(res.read())
headers需要去浏览器中找,右键 检查,依次查找,有些会隐藏
headers要写成字典的形式
3、爬取百度图片
3.1 正则
这里需要用到一些正则的知识,先来回顾一下正则
\w 任意的字母、数字、下划线
\W 处理字母、数字、下划线以外任意一个字符
\d 任意的数字
\D 任意的非数字
\s 任意的空白
\S 任意的非空白
[abc] a、b或者c中任意一个
[a-zA-F0-9] 匹配a-z或者A-F或者1-9中的任意有一个
[^abc] 匹配非a、b、c中的任意一个
. 任意的可见字符
^ 从开头开始匹配
$ 以哪些字符结尾
+ 前面的规则重复至少1次
* 前面的规则重复0到多次
? 前面的规则重复0或1次
{m} 重复m次
{m,n} 至少m次至多n次
{m,} 至少m次
{,n} 至多n次
re.S 把多行字符串看成一行
re.M 把多行字符串拆成多个单行字符串
re.I 忽略大小写
3.2 这里还用到了生成器
举个简单的例子,回顾一下生成器
ey .py
def func(a,b):
c = a+b
print(c)
return "Are you OK"
f = func(10,20)
print(f)
# 对于普通函数,函数调用表达式的值是函数的返回值
def func1(a,b):
c = a+b
print(c)
for _ in range(10):
yield "Are you OK"
p = func1(20,40)
print(p)
#这里并没有打印 c 得到的是一个生成器的对象 <generator object func1 at 0x0000020CCE4BE150>
# 函数中如果加入了yield,函数在调用的时候,不会直接调用,而是把函数调用的过程放入了一个生成器容器中,并且把yield后面的值作为生成器容器的一个元素;函数只有在迭代生成器的时候才能调用
for i in p:
print(i)
# 这时就会打印c的结果 打印一个数字60
然后后面打印的都是 'Are you OK'
3.3 爬取美女图片
sucaiSpider .py
在同级目录下新建一个imgs文件夹,用来存放图片
url解析,注意变化的规则,

页数变化时的路径变化,多查看几页

还有就是图片的url
有时候右键检查元素,图片的url并不能下载,不是正则匹配不正确,而是url经过了处理
查看网页源代码,ctrl+f输入关键字查找,找到图片的url,查看变化规则
sucai .py
from urllib import request
from time import sleep
#导入sleep的原因是设置等待,防止爬取太频繁而遇到反爬的一些问题
import re
# 1)数据的获取
# 封装一个函数,用于将多个页面标号转化请求对象
def request_from(url,page):
# 请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# 拼接url
if page == 1:
page_url= url + ".html"
else:
page_url = url + "_" + str(page) + ".html"
# 创建请求对象
req = request.Request(url=page_url,headers=headers)
return req
# 封装一个函数,传入一个页面标号的列表,对这些页面进行访问并且返回每次访问的响应体
def fetch_pages(url,pages):
for page in pages:
# 创建请求对象
req = request_from(url,page)
print("正在访问页面:",page)
# 向请求对象发起请求
res = request.urlopen(req)
# 将内容读取出来
html = res.read()
# 返回出去
yield html.decode("utf-8")
# 2)数据的解析
# 封装一个函数,传入一批的html源码,返回解析以后的一个有用的信息
def anylasis_html(html_list):
for html in html_list:
# 写一个正则规则来匹配页面上的图片的src
pat = re.compile(r'<div class="box picblock.*?<img .*?src2="(.*?)"',re.S)
ret = pat.findall(html)
# print(ret)
for img in ret:
yield img
# 3)数据的存储
def download_imgs(img_list):
for img in img_list:
print("当前正在下载:",img)
img_name = img.split("/")[-1] #取到图片名称
request.urlretrieve(url=img,filename="./imgs/"+img_name)
sleep(0.5)
if __name__ == '__main__':
url = "http://sc.chinaz.com/tupian/meinvxiezhen"
pages = [i for i in range(1,20)] # 列表生成器
html_gen = fetch_pages(url,pages)
img_list = anylasis_html(html_gen)
download_imgs(img_list)
今日代码链接
链接:https://pan.baidu.com/s/1besyCC754qsIGbhEvYvBjw
提取码:xblv
练习 :爬取糗事百科热图
糗事百科网址 https://www.qiushibaike.com/imgrank/
文件链接
链接:https://pan.baidu.com/s/10e43aTd243snFZlpxHRSew
提取码:yxw5

















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









