






先看图片
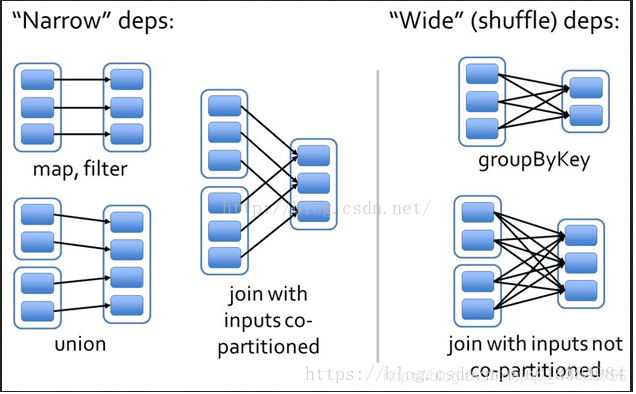
判断宽窄依赖的根本:父类分区内的数据,会被子类RDD中的指定的唯一一个分区所消费。如果是,那么就是窄依赖,如果不是则为宽依赖
那么我想了想如果使用repartition和coalesce那么是怎么样呢。
具体的实现:
package com.ygy.sparkTest
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object mytest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("test")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD((1 to 10), 3)
rdd.saveAsTextFile("out1")
sc.stop()
}
}
这是代码效果用文字说吧。
第一次 1 to 10 分区数3
分区内容:123 456 78910
第二次repartition 分区数4
分区内容:258 369 10 147
判断:宽依赖。进行了shuffle 父rdd的数据发送到不同的子rdd的数据中
第三次coalesce 分区数2
分区内容:123 45678910
判断:窄依赖。没有进行shuffle 父rdd的数据发送到同一个子rdd数据中
第四次 coalesce 分区数2 第二个参数设置为true 进行shuffle
分区内容:134679 25810
判断:宽依赖。进行了shuffle 父rdd的数据发送到不同的子rdd的数据中
最后总结:父RDD中分区内的数据,是否在子类RDD中也完全处于一个分区,如果是,窄依赖,如果不是,宽依赖。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









