




前置知识
块:又称为物理块,是操作系统读写硬盘的基本单位,一个逻辑文件块对应一个物理块
文件级:逻辑文件会被切分成多个逻辑文件块,逻辑文件块对应物理块,物理块对应磁盘的多个扇区
块存储:存储设备共享给客户端的是一块裸盘,那么该存储设备提供的就是块存储。
特点:
1.客户端可定制性强,可以自己制作文件系统,然后挂载使用,或者直接把操作系统安装在块存储里
2.主要用于虚拟机的本地硬盘
文件存储:为了解决多台服务器之间数据共享。并且数据一致,存储设备中分出一块空间,然后制作文件系统,然后在存储设备中完成挂载,共享给客户端
特点:
1、客户端定制性差,不能自己制作文件系统,文件系统是在存储设备中制作好的,客户端使用的就是一个文件夹。
2.文件检索与存储过程都是在存储设备中完成的,意味着随着客户端数量的增多,存储设备的压力越来越大,所以文件存储会限制集群的扩展规模
3.主要用于中小规模集群的多服务器之间共享数据,并且保持一致
对象存储:为了解决服务器之间共享数据,并且保持一致性,并且没有文件系统的概念,数据的存储分为两部分,元数据+内容
客户端通过url地址的方式提交元数据与数据
特点:
没有文件检索的压力,服务端不会随着客户端数目的增多压力成倍增大
用途:
分布式存储
分布式文件存储系统组件介绍
传统存储设备:
直接附加存储(DAS):IDE,SATA,SCSI,SAS,USB
网络附加存储(NAS):NFS,CIFS
存储区局域网络(SAN):SCSI,FC-SAN,iSCSI
分布式存储:
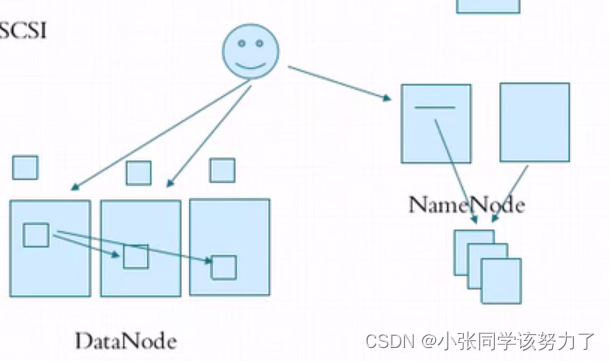
跨机架冗余
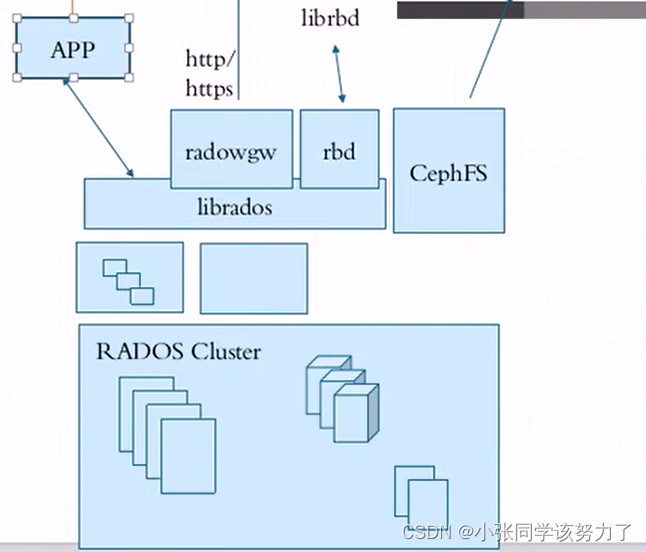
CEPH
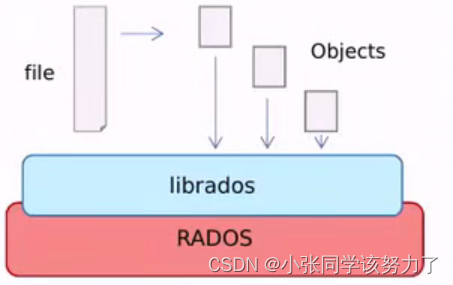
1.CEPH是一个统一的(提供对象存储、块存储和文件系统存储)、分布式存储(实现了真正的去中心化,理论上可以无限延展集群系统的规模)系统,它把每一个待管理的数据流(例如一个文件)切分为一到多个固定大小的对象数据流,并以其为原子单元完成数据存取
2.对象数据的底层存储服务是多个主机组成的存储集群,该集群也被称之为RADOS(Reliable Automatic Distributed Object Store)存储集群,即可靠、自动化、分布式对象存储系统
3.librados是RADOS存储集群的API,它支持C、C++、Java、Python、Ruby和PHP等编程语言
4.伪数据平衡,是通过算法达到的,object->hash算法–>pg->crush算法–>osd
5.ceph适用于海量小文件,或者单个文件容量大
优点:
1.性能
2.可扩展性,没有单点故障
3.可扩展性:未来可以理论上无限扩展集群规模
缺点:
1.耗费CPU
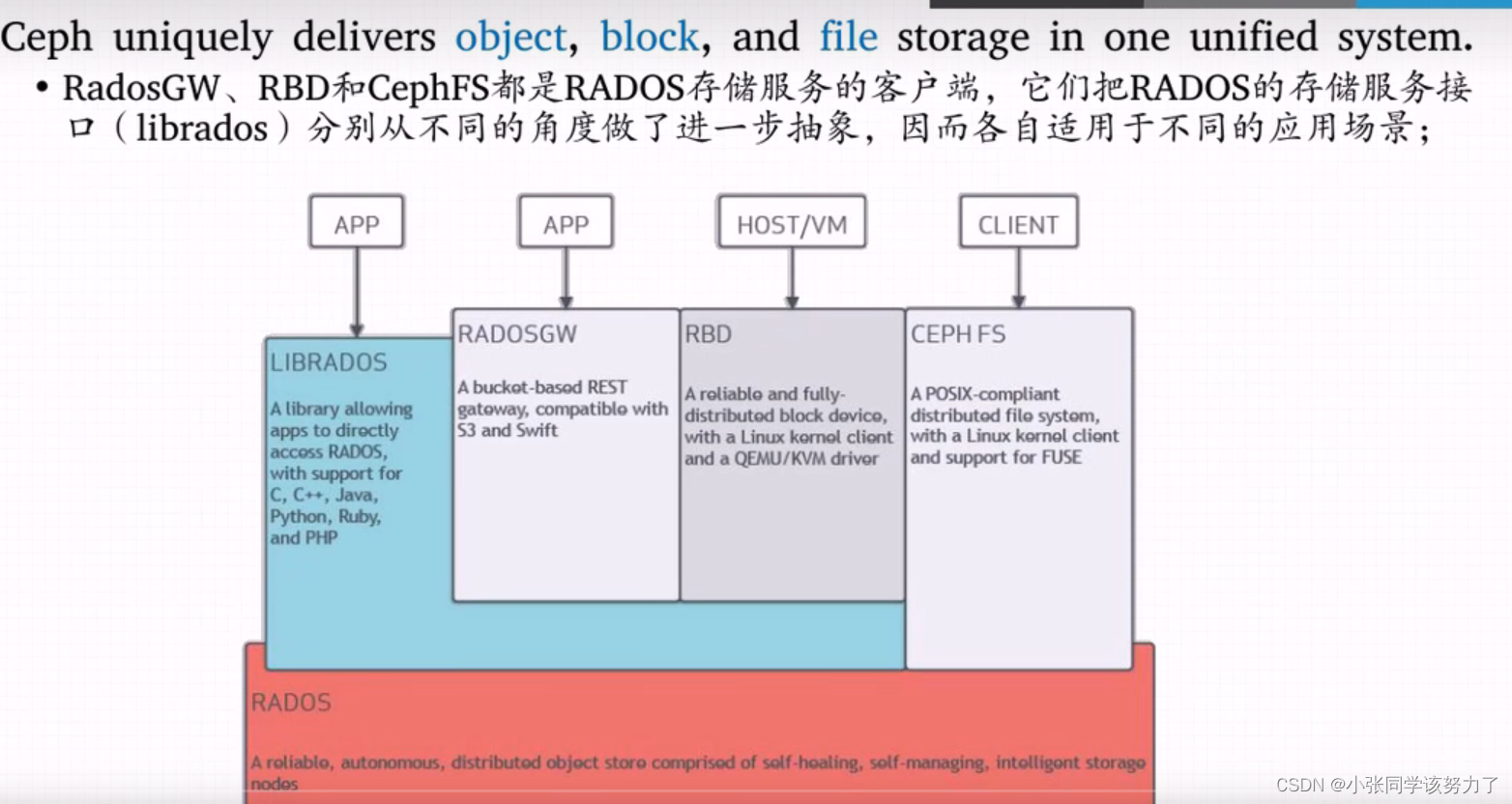
对象存储接口:RADOS GW
块存储接口:RBD
文件存储接口:Ceph FS
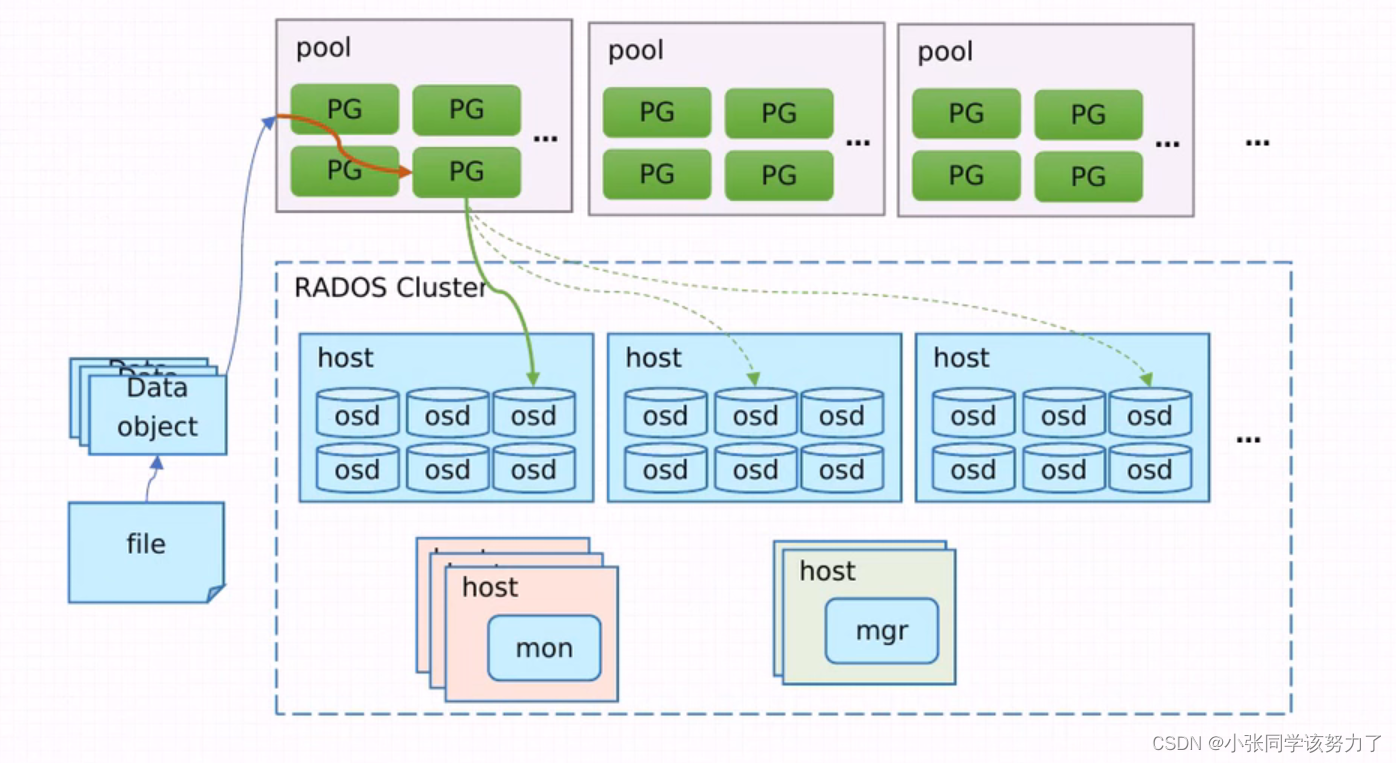
ceph的逻辑单位:
1.pool(存储池):
四大属性:
1.所有性和访问权限
2.对象副本数目,默认pool池中的一个pg只包含两个osd,生产环境推荐设
置为3个副本
3.pg数目,pg是pool的存储单位,pool的存储空间就由pg组成
4.crush规则集合
在创建存储池时需要指定pg个数,来创建pg,创建pg需要用到crush算法,
crush算法,crush算法决定pg与osd的对应关系,所以说,在客户端往ceph
中写入数据之前,pg与osd的对应关系已经是确定的
pg数目决定了数据的均匀性
crush算法决定了ceph存取数据的检索过程
pool有两种类型:
1.Replicated pool(默认):有副本的类型
2.Erasure-coded pool:没有副本
pool提供的能力:
1.Resilience(弹力):即在确保数据不丢失的情况允许一定的OSD失
败,这个数目取决于对象的拷贝份数或称副本数。
2.PG(放置组):ceph用pg把存放相同副本的osd归为一组。
3.CRUSH Rules(CRUSH规则):数据映射的策略。系统默认提供
“replicated_ruleset”。用户可以自定义策略来灵活地设置object存放的区
域。比如可以指定pool1中所有objects放置在机架1上,所有objects的第
1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务
器B上。定制CRUSH规则:

4.Snapshots(快照):你可以对pool做快照
5.Set Ownership:设置pool的owner的用户ID
6.Ceph集群创建后,默认创建了data和rgb三个存储池
2.pg(Placement Group,归属组)
pg的作用:pg相当于一个虚拟组件,对于集群伸缩,性能方面的考虑。
ceph将每个存储池分为多个pg,如果存储池为副本池类型,并会给该存储
池每个pg分配一个主osd加多个从osd,当数据量大的时候pg将均衡的分布
行不通集群中的每个osd上面。
是分配数据的最小单位,一个pg内包括多个osd,其中一个osd负责对外提
供服务,其他的osd负责备份
pg概念非常复杂,主要有如下几点:
pg也是对象的逻辑集合。pool中的副本数设置为3,则一个pg中包含3个
osd,同一个pg接收到的所有object在这3个osd上被复制。
epoch:pg map的版本号,它是一个单调递增的序列
acting set:支持一个pg的所有osd的有序列表。其中第一个osd是主osd,
其余为从osd,acting set是CRUSH算法分配的,但是不一定已经生效了。
up set:某一个pg map历史版本的acting set。在大多数情况下,acting set
和up set是一致的,除非出现了pg_temp
pg_temp:一个pg组里有三个组元osd,其中一个为组长,组长负责对外提
供服务,组员负责备份。
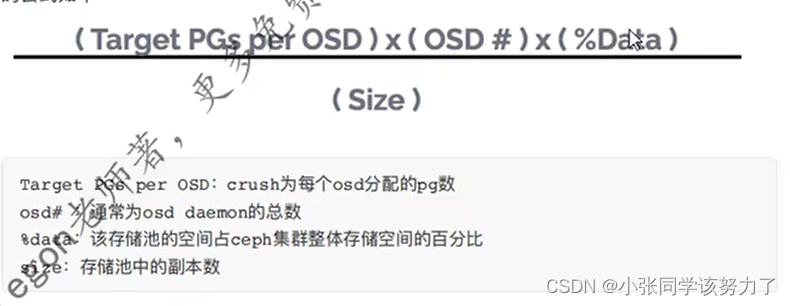
pg的数目:

pg的状态:
1.Creating创建中:PG正在被创建
2.Peering对等互联(处于该状态的PG不能响应IO请求):Peering就是
一个PG的所有OSD都需要互相通信来就PG的对象及元数据状态达
成一致的过程
3.Active活动的:Peering过程完成后,PG的状态就是Active的
4.Clean洁净的:在此状态下,主次OSD都已经被peered了、都处于就
绪状态,每个副本都就绪了
5.Down:PG掉线了,down状态持续300秒后状态设置为out踢出集群,
Ceph会启动自动恢复操作,选择其它的OSD加入
6.Degraded降级的:某个OSD被停止服务后,Ceph Mon将该OSD上的
所有PG的状态设置为degraded,即PG的osd数目不够
7.Remapped重映射:每当PG的acting set改变后,就会发生从旧
acting set改变后,就会发生从旧acting set到新acting set的数据迁移
8.Stale过期:每个OSD每隔0.5s向mon报告其状态,如果出现原因导致
osd报告状态失败了,或者其他OSD已经报告其主OSD down了,mon
将PG标记为stale状态
9.Undersized:PG副本数少于其存储池指定的个数
10.Scrubbing:各OSD会周期性检查其持有的数据对象的完性,以确保
主和从的数据一致,该时候状态就为此状态。
11.Recovering恢复中(增量恢复):一个OSD down后,其上面的PG
的内容的版本会比其他的OSD上的PG副本的版本落后。在它重启之后
Ceph会启动recovery过程来使其数据得到更新
12.Backfilling回填中(全量恢复):一个新OSD加入集群后,Ceph会尝
试将部分其他OSD上的PG挪到该新OSD上,该过程称为回填。与
recovery相比,回填是在零数据的情况下做全量拷贝,而恢复是在已
有数据的基础上做增量恢复
3.osd:
1.负责控制数据盘上的文件读写操作,与client通信完成各种数据对象操作
2.负责数据的拷贝和恢复
3.每个OSD守护进程监视它自己的状态,以及别的OSD的状态,并且汇报
给Monitor
osd上的pg数目:
1.不能过小,过小则数据不均
2.不能过大,过大则一个osd挂掉影响范围会很广,这会增大数据丢失的风险
4.monitor节点(整个集群的大管家)
1.监控全局状态->cluster map:
1.osd map
2.monitor map
3.pg map
4.crush map
2.负责管理集群内部状态(osd挂掉了,数据恢复等操作)
3.负责授权:
客户端访问时会先通过monitor验证操作权限
客户端需要根据monitor要到cluster map
4.monitor的个数为奇数,monitor节点不能超过半数挂掉,因为节点同步数
据用的是paxos算法(分布式强一致算法)
5.monitor进程可以跟osd在同一个物理节点上,但是不好
5.存储引擎:
hammer:
存储引擎filestore:osd daemon-xfs文件系统->磁盘
luminous:
存储引擎bluestore:osd daemon->lvm->裸磁盘


host(mom)是用来监视记录集群的节点数,多少个osd,各自处于什么状态。此外还负责维护整个集群的认证信息(CephX)。
host(mgr)跟踪运行时的指标数据(osd磁盘用了多少、还剩多少、每一个节点的CPU使用率等等、集群当前的状态),也提供了基于Python的插件来机组织和暴漏Ceph集群的信息。
osd:负责数据的存储、数据复制、数据恢复、数据重新均衡、提供监视信息给Monitors和Managers
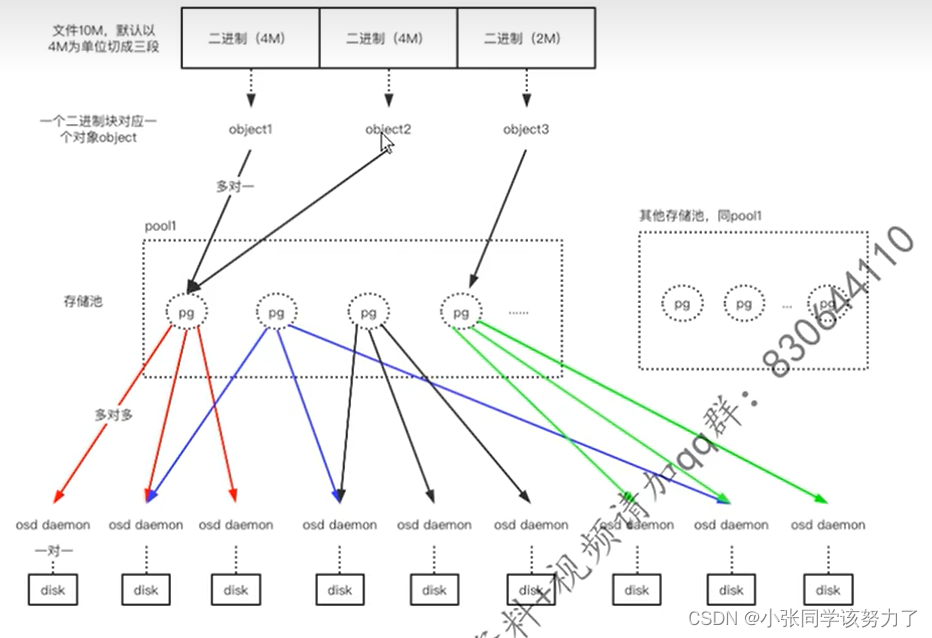
Ceph进行对象存储步骤:
1.从mon中获取最新的cluster map
2.客户端librad对二进制进行分块
file->object映射:
将用户要操作的file,映射为RADOS能够处理的object。本质就是按照object
的最大size对file进行切分。
3.客户端基于hash算法算出object将要在PG的ID(小数)
object->pg:
PG_ID=has(pool_id).hash(object_id)%PG总数
3.根据pool的冗余副本数量和数据类型根据CRUSH算法找到足够的osd进行存放,注意:在创建pool时,pg与osd的对应关系就确定了,此处只是查找它们
3.数据的写入,其实是写给主osd,由主osd再把数据给组员进行冗余
ceph集群扩容:
方案一:
新增一块磁盘,然后用osd daemon管理它。但问题是,新增一个osd
daemon,ceph会在该osd daemon上创建pg,说白了就是把该osd
daemon划分到一些pg组里,但凡一块osd daemon被分配到了pg里,
会发生数据迁移
方案二:osd daemon-lvm-裸盘下的扩容方式
从vg组里划分更多的空间给lvm,不必新增osd daemon
总结:如果集群考虑到日后要扩容,那么推荐使用方案二
Ceph进行文件存储
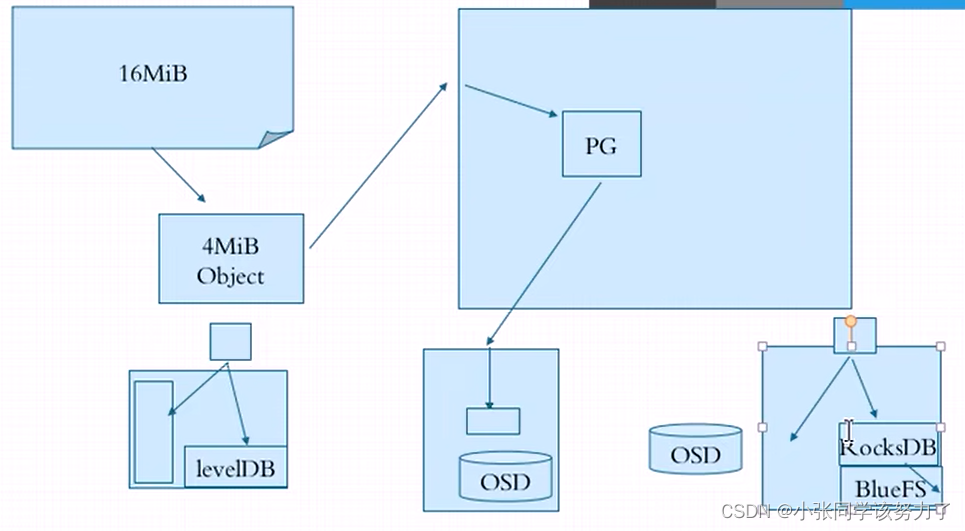
传统的采用左边的方式进行存储,对象数据存放在OSD中,元数据存放在OSD的文件系统中,levelDB(高性能的键值存储)存储对象自己的元数据
facebook改进后采用右边的方式进行存储,对象数据存放在OSD中,对象元数据以k-v形式放在RocksDB,RocksDB的数据放到BlueFS中。
Ceph部署
部署工具:

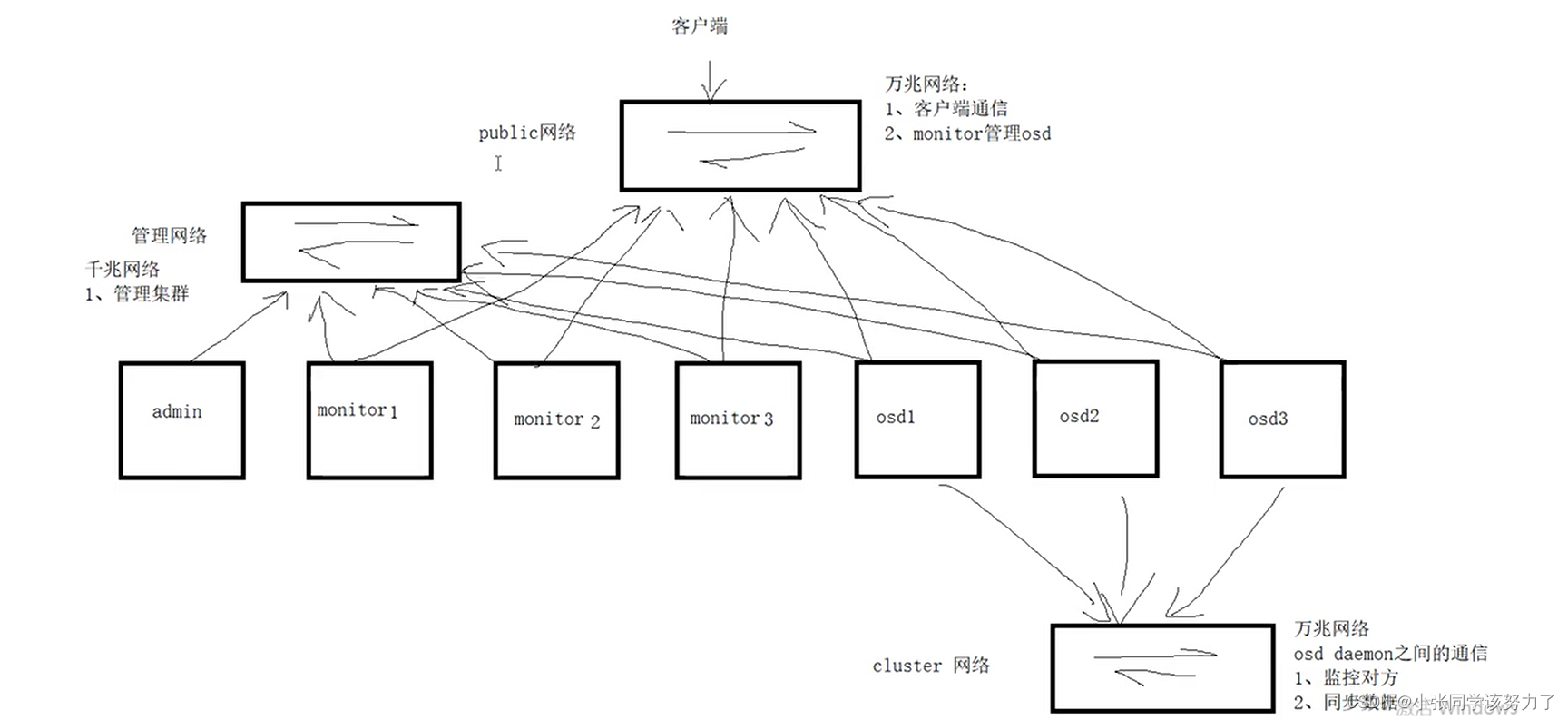
每个集群需要有两个网卡,一个网卡用于客户端进行调用,另一个网卡用于处理集群内部事务。
参考网站
#修改主机名
hostnamectl set-hostname ceph01
#修改/etc/hosts,添加以下配置
vim /etc/hosts
192.168.80.37 ceph01
192.168.80.47 ceph02
192.168.80.57 ceph03
# 停止
systemctl stop firewalld.service
# 禁用
systemctl disable firewalld.service
#关闭SELinux
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
#配置yum源
cd /etc/yum.repos.d/
mkdir bak && mv *.repo bak/
#下载aliyun的yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
#设置时间同步
# 设置时区
timedatectl set-timezone Asia/Shanghai
# 同步时间
yum install -y ntpdate
ntpdate time1.aliyun.com
#创建免密登陆
#在ceph01节点上执行
ssh-keygen
ssh-copy-id root@ceph01
ssh-copy-id root@ceph02
ssh-copy-id root@ceph03
#配置ceph源
vim /etc/yum.repos.d/ceph.repo
[ceph]
name=Ceph packages for
[ceph]
name=Ceph packages for
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
#安装ceph-deploy和ceph
#在ceph01节点上执行
yum install -y ceph-deploy ceph python-setuptools
#在ceph02和ceph03节点上执行
yum install -y ceph python-setuptools
#创建集群
#进行配置文件目录
cd /etc/ceph
#创建mon
ceph-deploy new ceph01 ceph02
#初始化mon
ceph-deploy mon create-initial
#查看集群状态
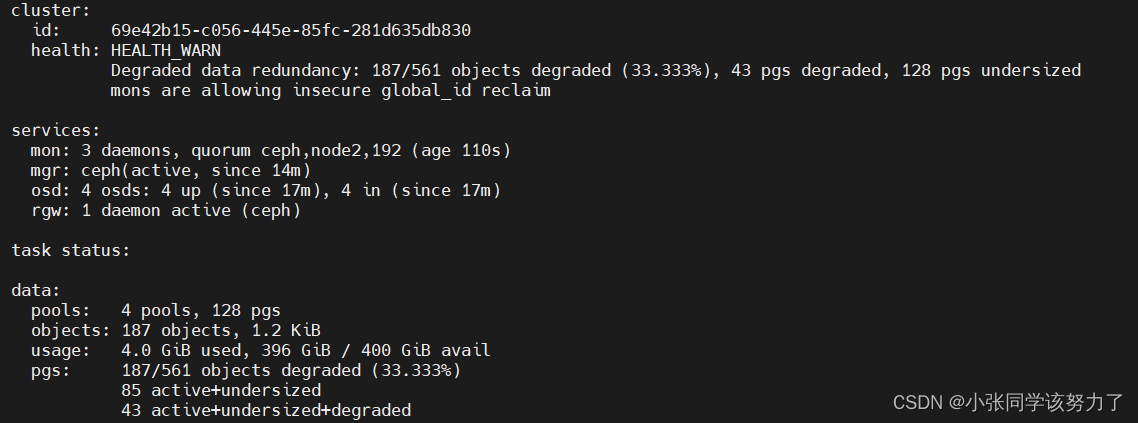
ceph -s
#创建osd
ceph-deploy osd create --data /dev/sdb ceph01
ceph-deploy osd create --data /dev/sdb ceph02
ceph-deploy osd create --data /dev/sdb ceph03
#查看集群状态
ceph -s
#查看osd状态
ceph osd stat
#查看osd目录树
ceph osd tree
#在ceph01节点上执行
ceph-deploy admin ceph01 ceph02 ceph03
#在ceph01、ceph02、ceph03节点上执行(/etc/ceph目录下)
chmod +r ceph.client.admin.keyring
#查看集群状态
ceph -s
创建mgr网关
#在ceph01节点上执行
cd /etc/ceph
ceph-deploy gatherkeys ceph01 ceph02 ceph03
ceph-deploy mgr create ceph01 ceph02 ceph03
#查看集群健康状态
ceph health
#安装octopus版本时还需要装以下模块
pip3 install pecan werkzeug
创建mds和pool
#以下操作均在ceph01节点上执行
#创建mds
ceph-deploy mds create ceph01 ceph02 ceph03
#创建存储池
ceph osd pool create cephfs_data 120
ceph osd pool create cephfs_metadata 120
#创建文件系统
ceph fs new cephfs cephfs_metadata cephfs_data
#查看文件系统
ceph fs ls
#查看mds节点状态
ceph mds stat
#常用命令
ceph osd pool get [存储池名称] size #查看存储池副本数
ceph osd pool set [存储池名称] size 3 #修改存储池副本数
ceph osd lspools #打印存储池列表
ceph osd pool create [存储池名称] [pg_num的取值] #创建存储池
ceph osd pool rename [旧的存储池名称] [新的存储池名称] #存储池重命名
ceph osd pool get [存储池名称] pg_num #查看存储池的pg_num
ceph osd pool get [存储池名称] pgp_num #查看存储池的pgp_num
ceph osd pool set [存储池名称] pg_num [pg_num的取值] #修改存储池的pg_num值
ceph osd pool set [存储池名称] pgp_num [pgp_num的取值] #修改存储池的pgp_num值
客户端挂载
(1) 内核驱动挂载
#安装依赖
yum install -y ceph-common
#创建挂载点
mkdir /mnt/cephfs
#获取存储密钥,管理节点执行
ceph auth get-key client.admin
#或从文件中获取
cat /etc/ceph/ceph.client.admin.keyring
#直接挂载
mount -t ceph 192.168.80.37:6789:/ /mnt/cephfs -o name=admin,secret=AQBkMoJge6sUAxAAg2s7u+s4p3wDDQNNx0TP9Q==
#建议将密钥保存到文件中然后再挂载
echo 'AQBkMoJge6sUAxAAg2s7u+s4p3wDDQNNx0TP9Q==' > /etc/ceph/admin.secret
mount -t ceph 192.168.80.37:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/admin.secret
#卸载
umount /mnt/cephfs/
(2) 用户控件挂载
#安装依赖
yum install -y ceph-fuse
#挂载
ceph-fuse -m 192.168.80.37:6789 /mnt/cephfs
#卸载
fusermount -u /mnt/cephfs
#扩容操作
扩容mon
#在ceph01节点上执行,修改ceph.conf文件
cd /etc/ceph
vim ceph.conf
[global]
fsid = 4ed770bf-5768-4ba5-b04f-f96a63bb98c9
mon_initial_members = ceph01, ceph02, ceph04 #添加ceph04
mon_host = 192.168.80.37,192.168.80.47,192.168.80.67 #添加ceph04的IP地址'
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public network = 192.168.80.0/24 #添加内部通信网段
#重新下发配置文件
ceph-deploy --overwrite-conf config push ceph01 ceph02 ceph03
#添加mon
ceph-deploy mon add ceph04
#查看集群状态
ceph -s
#扩容osd
ceph-deploy osd create --data /dev/sdb ceph04
docker部署ceph集群:
分别关闭防火墙和SElinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
创建相关的文件夹:
sudo mkdir -p /usr/local/ceph/{admin,data,etc,lib,logs}
拉取相关的镜像文件:
docker pull ceph/daemon:latest-nautilus
启动monitors服务
docker run -d --net=host \
--name=mon \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-e MON_IP=192.168.13.133 \
-e CEPH_PUBLIC_NETWORK=192.168.13.0/20 \
ceph/daemon:latest-nautilus mon
启动osd服务
docker run -d \
--name=osd \
--net=host \
--restart=always \
--privileged=true \
--pid=host \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-v /usr/local/ceph/data/osd:/var/lib/ceph/osd \
ceph/daemon:latest-nautilus osd_directory
启动manager服务
docker run -d --net=host \
--name=mgr \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
ceph/daemon:latest-nautilus mgr
启动mds服务
docker run -d \
--net=host \
--name=mds \
--privileged=true \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
-e CEPHFS_CREATE=0 \
-e CEPHFS_METADATA_POOL_PG=512 \
-e CEPHFS_DATA_POOL_PG=512 \
ceph/daemon:latest-nautilus mds
创建OSD磁盘
sudo mkdir -p /usr/local/ceph-disk
sudo dd if=/dev/zero of=/usr/local/ceph-disk/ceph-disk-01 bs=1G count=10
将虚拟文件虚拟成块设备
sudo losetup -f /usr/local/ceph-disk/ceph-disk-01
格式化
sudo fdisk -l
sudo mkfs.xfs -f /dev/loop6
将磁盘挂载到osd中
sudo mkdir /usr/local/ceph/data/osd/
sudo mount /dev/loop6 /usr/local/ceph/data/osd/
将相关数据copy给另外两台服务器
scp -r /usr/local/ceph node2地址:/usr/local/
scp -r /usr/local/ceph node3地址:/usr/local/
远程ssh调用启动mon
ssh node2 bash /usr/local/ceph/admin/start_mon.sh
ssh ceph3 bash /usr/local/ceph/admin/start_mon.sh
通过sudo docker exec mon ceph -s检查Ceph状态
在mon节点中生成osd的密钥
sudo docker exec -it mon ceph auth get client.bootstrap-osd -o /var/lib/ceph/bootstrap-osd/ceph.keyring
然后启动osd
启动mgr
sudo docker exec -it mon ceph auth get client.bootstrap-mgr -o /var/lib/ceph/bootstrap-mgr/ceph.keyring
在mon节点生成rgw的密钥信息
docker exec mon ceph auth get client.bootstrap-rgw -o /var/lib/ceph/bootstrap-rgw/ceph.keyring
启动rgw
docker run \
-d --net=host \
--name=rgw \
-v /etc/localtime:/etc/localtime \
-v /usr/local/ceph/etc:/etc/ceph \
-v /usr/local/ceph/lib:/var/lib/ceph \
-v /usr/local/ceph/logs:/var/log/ceph \
ceph/daemon:latest-nautilus rgw
CephFS部署
创建Data Pool
sudo docker exec osd ceph osd pool create cephfs_data 128 128
创建Metadata Pool
docker exec osd ceph osd pool create cephfs_metadata 64 64
创建CephFS
docker exec osd ceph fs new cephfs cephfs_metadata cephfs_data
查看FS信息
sudo docker exec osd ceph fs ls
搭建rgw节点
docker exec ceph mon ceph auth get client.bootstrap-rgw -o /var/lib/ceph/bootstrap-rgw/ceph.keyring
启动镜像
docker run -d --privileged=true --name ceph-rgw --network ceph-network --ip 192.168.13.134 -e CLUSTER=ceph -e RGW_NAME=ceph-rgw -p 7480:7480 -v /usr/local/ceph/lib:/var/lib/ceph/ -v /usr/local/ceph/etc:/etc/ceph -v /etc/localtime:/etc/localtime:ro ceph/daemon:latest-luminous rgw
测试添加rgw用户
docker exec rgw radosgw-admin user create --uid="testuser" --display-name="Yogen"
再添加一个子账号和密钥
docker exec rgw radosgw-admin subuser create --uid=testuser --subuser=testuser:swift --access=full
docker exec rgw radosgw-admin key create --subuser=testuser:swift --key-type=swift --gen-secret
查询账号信息
docker exec rgw radosgw-admin user info --uid=testuser
开启dashboard功能
docker exec mgr ceph mgr module enable dashboard
创建证书
docker exec mgr ceph dashboard create-self-signed-cert
创建登陆用户与密码:
docker exec mgr ceph dashboard set-login-credentials admin admin
如果上条报错则
docker exec -it mgr bash
vi /tmp/ceph-password.txt
admin
exit
docker exec mgr ceph dashboard ac-user-create admin -i /tmp/ceph-password.txt administrator
配置外部访问端口
docker exec mgr ceph config set mgr mgr/dashboard/server_port 18080
配置外部访问IP
docker exec mgr ceph config set mgr mgr/dashboard/server_addr 192.168.13.133
关闭https(如果没有证书或内网访问, 可以关闭)
docker exec mgr ceph config set mgr mgr/dashboard/ssl false
重启Mgr DashBoard服务
docker restart mgr

Auth相关
一︰认证与授权
Ceph使用cephx协议对客户端进行身份验证,集群中每一个Monitor节点都可以对客户端进行身份验证,所以不存在单点故障。cephx仅用于Ceph集群中的各组件,而不能用于非Ceph组件。它并不解决数据传输加密问题,但也可以提高访问控制安全性问题。
二:认证授权流程如下
1、客户端向Monitor请求创建用户。
2、Monitor返回用户共享密钥给客户端,并将此用户信息共享给MDS和OSD. 3、客户端使用此共享密钥向Monitor进行认证。
4、Monitor返回一个session key给客户端,并且此session key与对应客户端密钥进行加密。此session key过一段时间后就会失效,需要重新请求。
5、客户端对此session key进行解密,)如果密钥不匹配无法解密,这时候认证失败。6、如果认证成功,客户端向服务器申请访问的令牌。
7、服务端返回令牌给客户端。
8、这时候客户端就可以拿着令牌访问到MDS和OSD,并进行数据的交互。因为MDS和Monitor之间有共享此用户的信息,所以当客户端拿到令牌后就可以直接访问。
三︰相关概念
1、用户
用户通常指定个人或某个应用
个人就是指定实际的人,比如管理员
而应用就是指客户端或ceph集群中的某个组件,通过用户可以控制谁可以如何访问ceph集群中的哪块数据。
ceph支持多种类型的用户,个人与某应用都属于client类型。还有mds、osd、mgr一些专用类型。
2、用户标识
用户标识由“TYPE.ID"组成,通常ID也代表用户名,如client.admin、osd.1等。
3、使能caps
使能表示用户可以行使的能力,通俗点也可以理解为用户所拥有的权限。对于不同的对象所能使用的权限也不一样,大致如下所示。
Monitor权限有r、w、x和allow、profile、cap。
OSD权限有: r、w、x、class-read、class-wirte和profile osd。
另外osD还可以指定单个存储池或者名称空间,如果不指定存储池,默认为整个存储池。MDs权限有:allow或者留空。
#关于各权限的意义:
allow:对mds表示rw的意思,其它的表示“允许”。
r:读取。
w:写入。
x︰同时拥有读取和写入,相当于可以调用类方法,并且可以在monitor上面执行autn操作。class-read:可以读取类方法,x的子集。
class-wirte:可以调用类方法,x的子集。*∶这个比较特殊,代表指定对象的所有权限。
profile∶类似于Linux下sudo,比如profile osd表示授予用户以某个osd身份连接到其它osD或者Monitor的权限。
profile bootstrap-osd表示授予用户引导OSD的权限,关中此处可查阅更多资料。
4、keyring秘钥环文件
keyring文件是一个包含密码,key,证书等内容的一个集合。一个keyring文件可以包含多个用户的信息,也就是可以将多个用户信息存储到一个keyring文件。
keyring自动加载顺序
当访问Ceph集群时候默认会从以下四个地方加载keyring文件。
letclceph/cluster-name.user-name.keyring:通过这种类型的文件用来保存单个用户信息,文件名格式固定︰集群名.用户标识.keyring。如ceph.client.admin.keyring。这个代表ceph这个集群,这里的ceph是集群名,而clientadmin为admin用户的标识。
letclceph/cluster.keyring:通用来保存多个用户的keyring信息。/etclceph/keyring:也用来保存多个用户的keyring信息。
letc/ceph/keyring.bin:二进制keyring文件,也用来保存多个用户的keyring信息。
Ceph常用命令
生成osd树状结构:
#创建数据中心:datacenter0
ceph osd crush add-bucket datacenter0 datacenter
#创建机房:room0
ceph osd crush add-bucket room0 room
#创建机架:rack0,rack1,rack2
ceph osd crush add-bucket rack0 rack
ceph osd crush add-bucket rack1 rack
ceph osd crush add-bucker rack2 rack
#把机房room0移动到数据中心datacenter0下
ceph osd crush move room0 datacenter=datacenter0
#把机架rack0、rack1、rack2移动到机房room0下
ceph osd crush move rack0 room=room0
ceph osd crush move rack1 room=room0
ceph osd crush move rack2 room=room0
#把主机osd1移动到:datacenter0/room/rack0下
ceph osd crush move osd1 datacenter-datacenter0 room=room0 rack=rack0
#把主机osd2移动到:datacenter0/room/rack0下
ceph osd crush move osd2 datacenter-datacenter0 room=room0 rack=rack0
#把主机osd3移动到:datacenter0/room/rack0下
ceph osd crush move osd3 datacenter-datacenter0 room=room0 rack=rack0
crush相关
#导出crush视图
ceph osd getcrushmap -o test.bin
#将二进制文件test.bin导出为txt
crushtool -d test.bin -o test.txt
统一节点的ceph.conf文件
#将admin节点的ceph.conf推送到其他节点
ceph-deploy --overwrite-conf config push mon0 mon1
重启服务
#重启服务
systemctl restart ceph.target
#重启守护ceph进程
systemctl restart ceph-mgr.target
systemctl restart ceph-mds.target
systemctl restart ceph-mon.target
systemctl restart ceph-osd.target
systemctl restart ceph-osd@1.target
systemctl restart ceph-osd@2.target
systemctl restart ceph-osd@3.target
#平滑重启
#tell子命令
ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value}[--{name}={value} ]
#在管理节点运行
ceph tell mon.mon01 injectargs --mon_allow_pool_delete=trueceph tell mon.* injectargs --mon_allow_pool_delete=true
#daemon子命令
ceph daemon {daemon-type}.{id} config set {name]={value}
ceph daemon mon.mon01 config set mon_allow_pool_delete false
#通过socket文件
#如果超过半数的monitor节点挂掉,此时通过网络访问ceph的所有操作都会被阻塞,但monitor的本地socket还是可以通信的。
ceph --admin-daemon /var/run/ceph/ceph-mon.mon03.asok quorum_status
集群状态
#查看集群状态
ceph -s
#关闭自动重平衡
ceph osd set noout
#恢复自动重平衡
ceph osd unset noout
#查看配置
ceph config dump
#查看mon集群状态
ceph mon dump
#所有 Pool 的状态和所有 OSD 的状态
ceph osd dump
#查看存储池信息
ceph osd pool ls detail
#设置存储池应用类型
ceph osd pool application disable rbdpool cephfs
#重启服务
systemctl restart ceph-
auth相关
#查看ceph 集群中的认证用户及相关的key
ceph auth list#简写:ceph auth ls
#查看某一用户详细信息
ceph auth get client.admin
#只查看用户的key信息
ceph auth print-key client.admin
#创建用户,用户标识为client.test。指定该用户对mon有r的权限,对osd有rw的权限,osd没有指定存储池,所以是对所有存储池都有rw的权限。在创建用户的时候还会自动创建用户的密钥。
ceph auth add client.test mon "allow r" osd "allow rw"
#修改用户权限
ceph auth caps client.test mon "allow r" osd "allow rw pool=kvm"
#删除用户,用户名为osd.0
ceph auth del osd.0
#创建一个名为client.admin的用户,设置好用户对mds、osd、mon的权限,然后把密钥导出到文件中
ceph auth get-or-create client.admin mds 'allow *' osd 'allow * ' mon 'allow * '>/etc/ceph/ceph.client.admin.keyring1
#或者
ceph auth get-or-create client.admin mds /'allow * ' osd 'allow *' mon 'allow * '-o /etclceph/ceph.client.admin.keyringL,
#创建一个名为osd.0的用户,设置好用户对mon、osd的权限,然后把密钥导出到文件中
阳式
ceph auth get-or-create osd.0 mon 'allow profile osd' osd 'allow * ' -olvar/ liblceph/osd/ceph-0/keyring
#创建一个名为mdsmic3的用户,设置好用户对mon、osd、mds的权限,然后把密钥导出到文件中
ceph auth get-or-create mds.nc3 mon 'allow rwx ' osd 'allow *' mds 'allow *'-o/var/lib/ceph/mds/ceph-cs1/ keyring
pool相关
1.创建存储池
#语法:ceph osd pool create <pool name> <pg num> <pgp num> [type]pool name:存储池名称,必须唯一。
pg num:存储池中的pg数量。
pgp num:用于归置的pg数量,默认与pg数量相等。
type:指定存储池的类型,有replicated和erasure,默认为replicated。
#例:创建一个副本池
ceph osd pool create eaon test 32 32#生路type,默认为replicated
2、修改存储池的pg数
注意:在更改pool的PG数量时,需同时更改PGP的数量。PGP是为了管理placement而存在的专门的PG,它和PG的数量应该保持一致。如果你增加pool的pg_num,就需要同时增加pgp_num, ,保持它们大小一致,这样集群才能正常rebalancing。
ceph osd pool set egon_test pg_num 60ceph osd pool set egon_test pgp_num 60
3、查看存储池
#查看ceph集群中的pool数量
ceph osd lspools
#查看名字与详情
ceph osd pool ls
ceph osd pool ls detail
#查看状态
ceph osd pool stats
4、重命名
ceph osd pool rename <old name> <new name>
5、在集群中删除一个pool,注意删除poolpool映射的image会直接被删除,线上操作要谨慎存储池的名字需要重复两次
eeph osd pool delete tom_test tom_test --yes-i-really-really-mean-it
#删除时会报错:
Error EPERM:pool deletion is disabled; you must first set the
mon_allow_pool_delete config option to true before you can destroy a pool
这是由于没有配置mon节点的 mon_allow_pool_delete字段所致,解决办法就是到mon节点进行相应的设置。
解决方案:
ceph tell mon.* injectargs --mon_allow_pool_delete=true
ceph osd pool delete tom_test tom_test --yes-i-really-really-mean-it删除完成后最好把mon_allow_pool_delete改回去,降低误删的风险
6、为一个ceph pool配置配额、达到配额前集群会告警,达到上隙后无法再写入数据
当我们有很多存储池的时候,有些作为公共存储池,这时候就有必要为这些存储池做一些配额,限制可存放的文件数,或者空间大小,以免无限的增大影响到集群的正常运行。设置配额。
#查看池配额设置
ceph osd pool get-quota ipool_nameA
#对对象个数进行配额
ceph osd pool set-quota {pool2name} max_objects {number}
#对磁盘大小进行配额
ceph osd pool set-quoea ipocl_name} max_bytes {number}
#例:
ceph osd pool set-quota egon_test max_bytes 1000000000
7、配置参数
于存储池的配置参数可以通过下面命令获取。
ceph osd pool get <pool name> [ key name ]
如
ceph osd pool get <pool name> size
pg相关
1、查看pg组映射信息
ceph pg dump#或ceph pg ls
2、查看pg信息的脚本,第一个行为pool的id号
ceph pg dump awk
BEGIN { IGNORECASE =1
/^PG_STAT/ { col=l; while ( $col!="UP" ) {col++}; col++
/^[ 0-9a-f]+\.[ 0-9a-f]+/ { match ($O,/^ [ 0-9a-f]+/ ) ; poolmsubstr($0,RSTART,RLENGTH) ; poollist[ pool]=0 ;
up=$col; i=0; RSTART=0;RLENGTH=0; delete osds; while(match(up,/10-9]+/)>0)osds[++i]=substr(up,RSTART,RLENGTH ) ; up = substr(up,RSTART+RLENGTH )
for(i in osds) {array [ osds [i ] , pool]++; osdlist [ osds[i]];}
}
END {
printf ( " \n" );
printf ( "pool :lt"); for (i in poollist) printf( "8s1c ",i); printf ( " | SUM \n") ;for (i in poollist) printf ( "----
for (i in osdlist) i printf ( "osd.silt", i) ; sum=o;
for (j in poollist) { printf("%i\t", array[i,j]); sum+=array[i,j];sumpool[j]+=array[i,j] }; printf("]%i\n , sum)
for (i in pqollist) printf ( "--------
2tf( "_---------------\n" );
printf ( "SUM:\t" ) ; for (i in pooIist) printf( "%s\t" ,sumpool[i]);
printf("|\n") ;
}'
3、查看pg状态
ceph pg stat
而常
公
4、查看一个pg的map
cephog uiap 1.7b
5x.,查询一个pg的详细信息
ceph pg 1.7b query
6、清理一个pg组
ceph pg scrub 1.7b
7、查看pg中stuck(卡住)的状态
ceph pg dump_stuck unclean
ceph pg dump_stuck inactive
ceph pg dump_stuck stale
mon相关
#查看mon状态
ceph mon stat
#查看mon映射信息
ceph mon dump
#检查Ceph monitor仲裁/选举状态
ceph quorum_status --format json-pretty
#查看mon信息包括ip地址
获得一个正在运行的mon map,并保存在1.txt文件中
ceph mon getmap -o 1.txt
mbnmaptool --print 1.txt
mds相关
#查看mds状态
ceph mds stat
ceph mds dump
#删除mds节点
ssh rootemon01 systemctl stop ceph-mds.target
ceph mds rm o#删除一个不活跃的mds#启动mds后,则恢复正常
#关闭mds集群
ceph mds cluster_down
#开启mds集群
Iceph mds cluster_up
#设置cephfs文件系统存储方式最大单个文件尺寸
ceph mds set max_file_size 1024000000000
osd相关:
1、查看osd状态
ceph osd stat
2、查看osd树
ceph osd tree查看
ceph osd ls-tree rackl#查看osd tree中rack1下的osd编号
3、查看osd映射信息
ceph osd dump
4、查看数据延迟
ceph osd perf
5、查看CRUSH map
ceph osd crush dump
6、查看与设置最大osd daemon的个数
#查看
ceph osd getmaxosdmax_osd = 12 in epoch 379
#设置最大的 osd daemon的个数(当扩大 osd daemon的时候必须扩大这个值)
ceph osd setmaxosd 2048
7、设置osd的权重
ceph osd reweight 3 0.5#把osd.3的权重改为0.5
8、暂停osd(暂停后整个ceph集群不再接收数据)
ceph osd pause#暂停的是所有的osd
9、再次开启osd (开启后再次接收数据)
ceph osd unpause
10、设置标志flags ,不允许关闭osd、解决网络不稳定,osd 状态不断切换的问题
eeph osd set nodown
取消设置
ceph osd unset nodown

















 1890
1890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









