




 本文介绍了五种常见的机器学习技巧,包括L1/L2正则化、数据增强、dropout、BatchNormalization和提前停止,详细解释了它们的作用、优缺点及应用场景。
本文介绍了五种常见的机器学习技巧,包括L1/L2正则化、数据增强、dropout、BatchNormalization和提前停止,详细解释了它们的作用、优缺点及应用场景。
1. L1、L2正则化
在loss函数上添加权重的L1/L2范数,作为正则化项。
L1正则化有助于生成一个稀疏权值矩阵,让有效特征数量变少,常用于特征选择;
L2正则化可以压缩权重,常用于 w, 权重绝对值大小会整体倾向于减小,不会出现特别大的值,是训练时的常规手段。
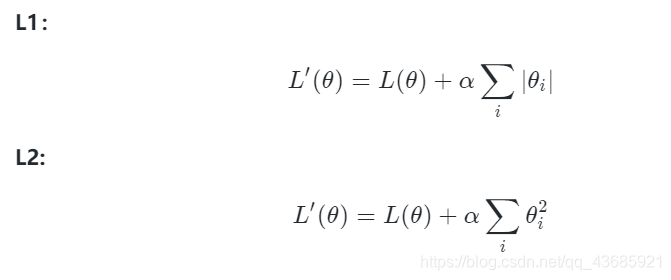
2.数据增强
向数据中添加噪声和人工扰动来提升网络的泛化能力,如颜色变换、几何变换等;
优点:易于实现和使用,是训练时的必备手段。
3.dropout
以一定的概率丢弃神经元,是bagging方法的近似,同时能提高训练速度,不过有可能会引起方差漂移,和批量归一化不能兼容。要使用BN就要把dropout放在BN之后。
优点:易于实现,对硬件无开销。
4.BatchNormalization
通过变换把每层的数据归一化,变为同分布的,是白化操作的一种近似。
优点:能有效解决深度网络的梯度爆炸、梯度弥散等问题。
5.提前停止
限制迭代次数,防止模型过度训练造成的过拟合。
优点:容易实现,无硬件开销。
缺点:提前停止有一定的风险,判断过拟合的次数并不容易确定。

















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









