




 本文详细介绍了PyTorch中交叉熵损失函数CrossEntropyLoss的构成,它由softmax、log和负对数似然损失(NLLLoss)组成。NLLLoss用于计算每个类别的对数概率,取负值后输出。在示例中展示了NLLLoss的使用方法,解释了其如何根据目标类别选择对应的概率并计算平均值。通过理解这些概念,有助于深入掌握深度学习模型的损失计算。
本文详细介绍了PyTorch中交叉熵损失函数CrossEntropyLoss的构成,它由softmax、log和负对数似然损失(NLLLoss)组成。NLLLoss用于计算每个类别的对数概率,取负值后输出。在示例中展示了NLLLoss的使用方法,解释了其如何根据目标类别选择对应的概率并计算平均值。通过理解这些概念,有助于深入掌握深度学习模型的损失计算。
交叉熵公式
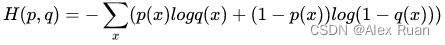
在pytorch中
 细究其中CrossEntropyLoss是由softmax+log+NLLLoss组成
细究其中CrossEntropyLoss是由softmax+log+NLLLoss组成
那百度一下NLLLoss是什么?
from torch import nn
import torch
# nllloss首先需要初始化
nllloss = nn.NLLLoss() # 可选参数中有 reduction='mean', 'sum', 默认mean
predict = torch.Tensor([[2, 3, 1],
[3, 7, 9]])
label = torch.tensor([1, 2])
nllloss(predict, label)
# output: tensor(-6)
nllloss对两个向量的操作为,继续将predict中的向量,在label中对应的index取出,并取负号输出。label中为1,则取2,3,1中的第1位3,label第二位为2,则取出3,7,9的第2位9,将两数取平均后加负号后输出。
个人理解:所以整个过程就是在求每个class下的概率(softmax),然后取log,最后根据公式在目标class下的p是1,其余是0,所以直接把对应的index取出来即可
参考:
NLLLoss:https://zhuanlan.zhihu.com/p/383044774
交叉熵损失函数CrossEntropyLoss():https://zhuanlan.zhihu.com/p/98785902


















 1359
1359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









