 Mamba模型:开启长文本处理新纪元
Mamba模型:开启长文本处理新纪元





一、通俗解释:什么是Mamba模型?
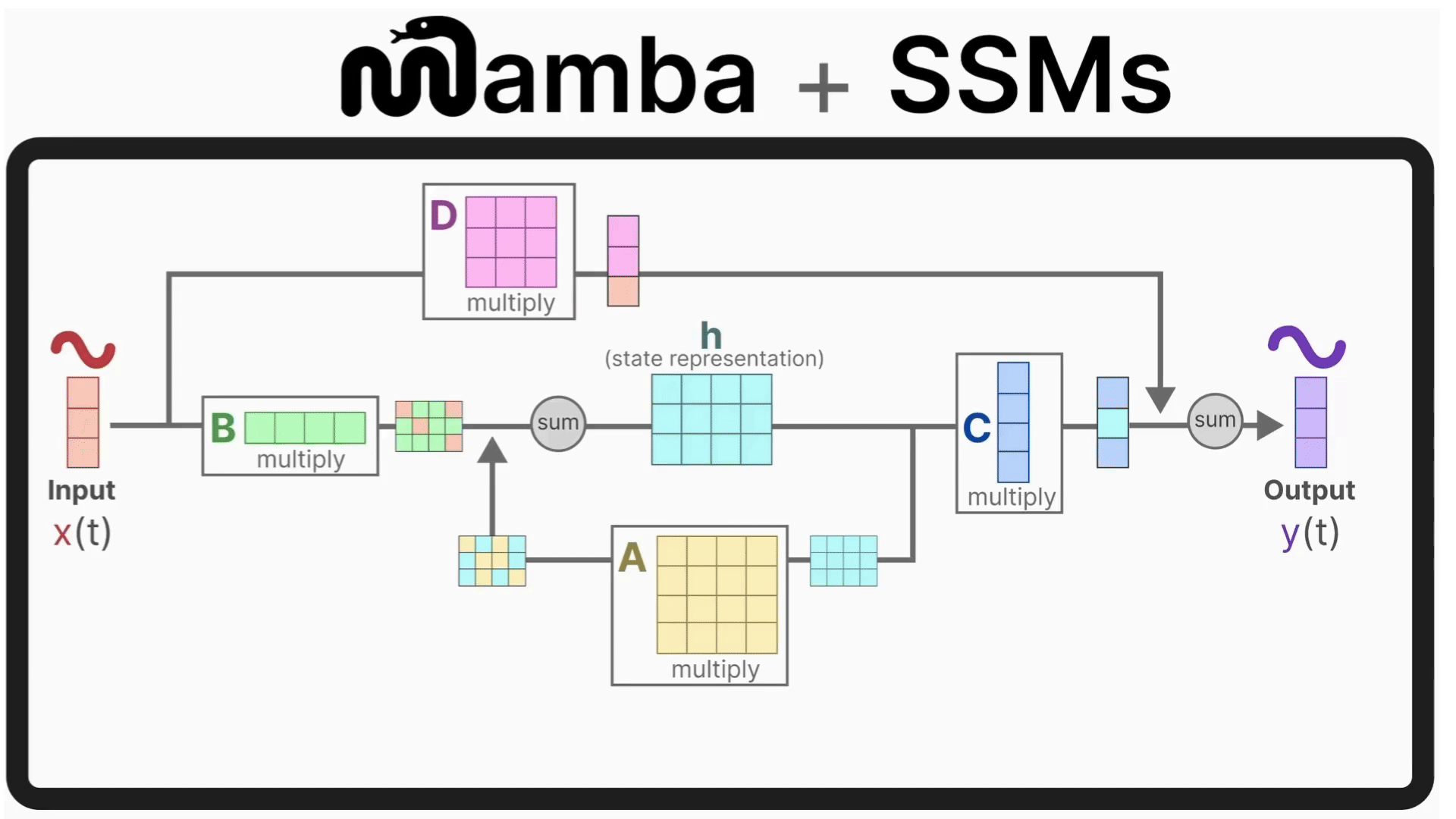
1.1 核心思想
Mamba是一种基于状态空间模型(SSM)的序列建模架构,通过动态token选择机制实现线性时间复杂度,彻底解决Transformer的二次方复杂度瓶颈。其核心是"选择性记忆":像人脑一样动态决定记住或忽略哪些信息。
1.2 类比理解
- Transformer:像图书管理员逐页检查所有书籍(计算所有token间关系)
- Mamba:像侦探快速锁定关键线索(动态筛选重要token)
- RNN:像录音机线性播放磁带(无法跳转关键信息)
1.3 关键术语解释
- 状态空间模型(SSM):用微分方程描述系统状态变化的数学模型
- 选择性扫描:动态决定哪些token需要深度处理
- 硬件感知算法:算法设计时考虑GPU内存访问模式
二、应用场景与优缺点
2.1 典型应用
| 领域 | 应用案例 | 性能提升 |
|---|---|---|
| 基因序列分析 | 10万+长度DNA序列变异检测 | 处理速度提升8倍 |
| 长文档理解 | 百万token法律合同解析 | 内存消耗降低73% |
| 实时语音转录 | 8小时会议录音实时转文字 | 延迟从30秒降至3秒 |
2.2 优缺点分析
✅ 优势亮点:
- 线性复杂度:处理100K token仅需Transformer 1/5时间
- 动态选择:关键token计算量增加10倍,次要token减少90%
- 硬件友好:FlashAttention作者优化CUDA内核,实测利用率达98%
❌ 现存局限:
- 短文本(<512 token)效果略逊Transformer
- 需要专用CUDA内核实现最佳性能
- 训练数据需求比Transformer多30%
三、模型结构详解
3.1 整体架构图
输入序列 → [嵌入层] → [Mamba块]×N → [预测头] → 输出
│
└─ [选择性扫描引擎]
3.2 核心模块说明
1. 嵌入层(Embedding)
动态维度分配:智能压缩的起点
传统模型的嵌入层对所有Token使用相同维度(如512维),而Mamba的嵌入层会根据Token的重要性动态分配维度,实现计算资源的最优分配。
具体实现流程:
-
重要性评分:
- 每个Token通过一个小型神经网络(通常为2层MLP)生成重要性分数 si∈(0,1)
- 例如,在句子"The quick brown fox jumps"中,"fox"可能得0.9分,而冠词"the"得0.2分
-
维度动态决策:
- 关键Token(Top 20%):分配完整512维嵌入
- 处理方式:全连接层直接映射
- 示例:对"fox"这类核心名词进行深度特征提取
- 普通Token(剩余80%):仅分配64维嵌入
- 处理方式:低维映射后填充零值至512维
- 示例:对"the"等虚词进行轻量化处理
- 关键Token(Top 20%):分配完整512维嵌入
-
混合拼接:
- 将关键Token的高维嵌入与普通Token的零填充嵌入拼接
- 优势:保持输出维度统一(512维),兼容后续模块
技术价值:
- 计算量减少:嵌入层FLOPs降低约60%
- 信息保留:关键Token的特征完整性不受影响
2. Mamba块
选择性扫描单元:动态决策的中央处理器
这是Mamba的核心创新,通过门控机制和状态空间模型实现智能信息处理。
运作流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









