




目录
- 模型结构详解
- 数学原理与推导
- 代表性变体及改进
- 应用场景与优缺点
- PyTorch代码示例
1. 模型结构详解
1.1 核心架构
输入序列 → 词嵌入 → 位置编码 → 编码器堆叠 → 解码器堆叠 → 输出序列
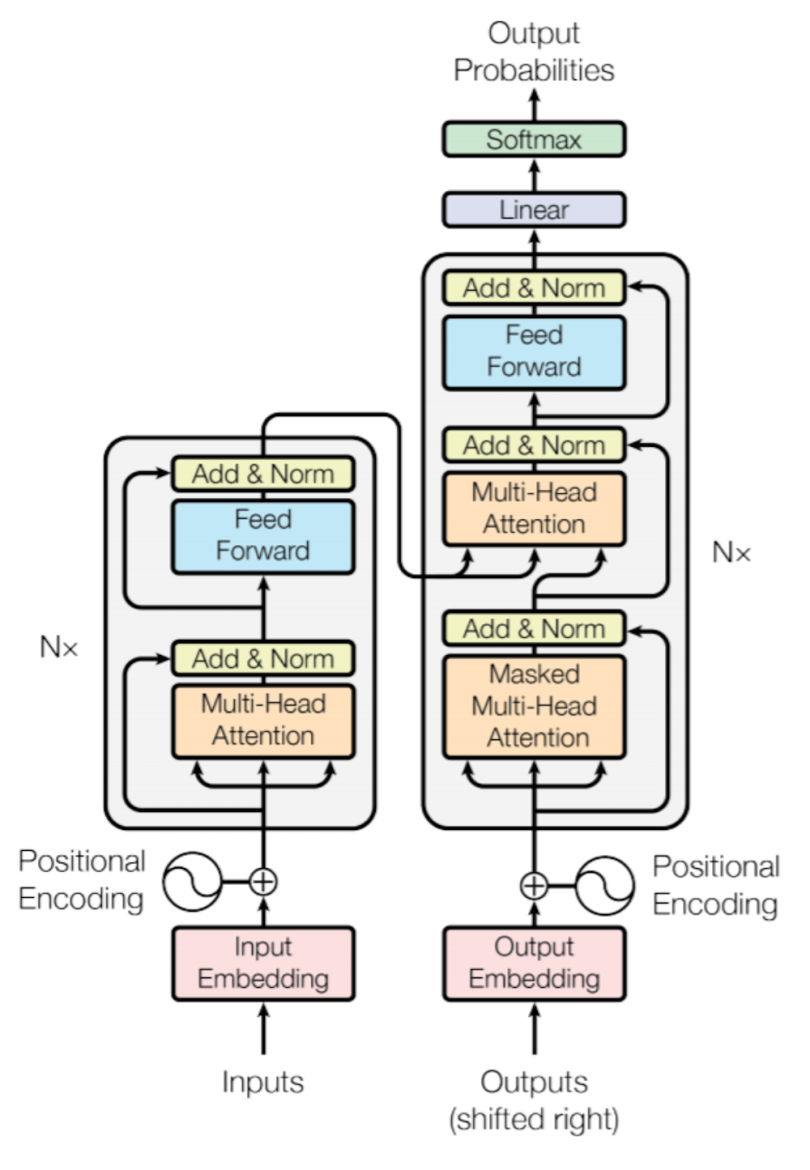
1.1.1 编码器-解码器结构
- 编码器:由N个相同层堆叠,每层含 多头自注意力 + 前馈网络
- 解码器:在编码器基础上增加 交叉注意力 层,用于关注编码器输出
1.1.2 核心组件
- 自注意力机制:计算序列元素间依赖关系
- 位置编码:注入序列位置信息(正弦函数或学习式)
- 残差连接 & 层归一化:每子层后应用
1.1.3 输入输出
- 输入:Token序列(如文本词ID或图像分块)
- 输出:
- 自回归任务(如GPT):逐个生成Token
- 非自回归任务(如BERT):全序列并行输出
2. 数学原理与推导
2.1 自注意力计算

其中:
- Q∈Rn×dk:查询矩阵
- K∈Rm×dk:键矩阵
- V∈Rm×dv:值矩阵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









