




 本文详细介绍了Spark机器学习库的实例使用方法,包括实例、数据和jar包的位置,以及如何通过spark-submit运行Java KMeans聚类实例。
本文详细介绍了Spark机器学习库的实例使用方法,包括实例、数据和jar包的位置,以及如何通过spark-submit运行Java KMeans聚类实例。
纯属踩坑记录。
spark本身就携带很多ml实例,
java 文件位置
在spark的根目录下面,有个examples文件夹,所有的实例都在里面

这里以java文件进行查找看看
在 cd examples/src/main/java/org/apache/spark/examples/ 目录下

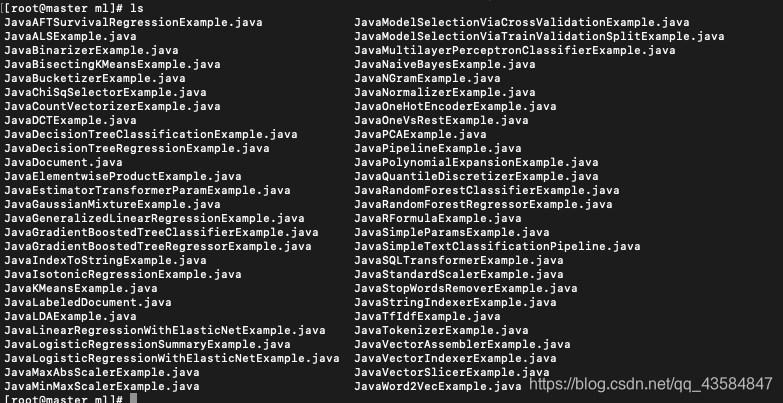
进入ml文件夹,就可以看到系统给的java的sparkml实例,如下图:
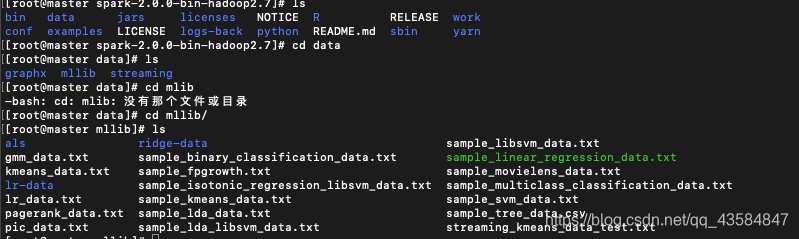
数据存放位置
在spark的根目录下面,有个data文件夹,所有的实例数据都在里面,情况如下图:
jar 包存放位置
在spark的根目录下面的examples里面,,有个jars文件夹,所有的jar包都在里面,情况如下图
运行实例
在了解了这些所在的位置之后,最简单的方法就是通过spark-submit进行提交
进入spark的根目录,执行下面这条命令:
./bin/spark-submit --class org.apache.spark.examples.ml.JavaKMeansExample --master local examples/jars/spark-examples_2.11-2.0.0.jar

⚠️⚠️⚠️⚠️⚠️⚠️spark-submit各参数的含义:
- –class
指的是类,这里的类是最上面那个包名.类名,这里包名是类 org.apache.spark.examples.ml 这里的类名是JavaKMeansExample
所以说,class便是 org.apache.spark.examples.ml.JavaKMeansExample - jar包 路径
这里就是 examples/jars下面的那个jar包,路径为 examples/jars/spark-examples_2.11-2.0.0.jar
~~~一个神奇的发现
~~~把上面说的那个class的后面的
运行之前一定要记得先把要用的数据集先传到hdfs上,不然会出现下面的错误,具体的解决方案请参考我另一篇专门讲解的文章,链接如下:https://blog.youkuaiyun.com/qq_43584847/article/details/98874497
 成功运行之后,kmeans聚类的运行结果如下:
成功运行之后,kmeans聚类的运行结果如下:


















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









