




 本文探讨了CPU压测时遇到的问题,如CPU.idle过低,介绍了CPU.idle的概念及其影响,以及如何通过查看线程栈信息进行问题排查。此外,还涉及CPU负载评估、线程与进程的区别、通信方式,以及HTTP、HTTPS、TCP、UDP协议和数据库的相关知识。
本文探讨了CPU压测时遇到的问题,如CPU.idle过低,介绍了CPU.idle的概念及其影响,以及如何通过查看线程栈信息进行问题排查。此外,还涉及CPU负载评估、线程与进程的区别、通信方式,以及HTTP、HTTPS、TCP、UDP协议和数据库的相关知识。
目录
压测出现过什么问题?
线程等待时使用用户态程序,没有使用sleep空闲态,导致CPU idle过低
cpu.idle很低会出现什么问题?
什么是cpu.idle
cpu.idle指的是CPU处于空闲状态时间比例
CPU利用率主要分为用户态,系统态和空闲态,分别表示CPU处于用户态执行的时间,系统内核执行的时间,和空闲系统进程执行的时间,三者之和就是CPU的总时间
cpu.idle过低排查方式
- top 或者 jps 或者 ps -ef | grep java,假定我们找到的是java 进程 PID=9527
- 使用命令:top -H -p 9527,找到java进程中的线程情况
- 找到占用cpu较高的排名靠前的几个线程 PID 假如找到的耗CPU较高的线程 PID=95271
- 查看该线程的堆栈信息,使用命令:jstack -l 95271 或者 jstack -F 95271
- 分析堆栈的信息,进一步进行排查代码逻辑
为什么查看线程的栈信息可以看到当前程序的执行路径
假设程序调用C函数模块,先保存C函数的地址和变量,执行到C函数中的B函数时循环模块时执行时间过长,栈中一直保存以上信息,栈是先进后出的,执行到C中B函数时时间太长,则判定这段代码有问题。
CPU idle是如何统计的
假设两个进程,进程A在sleep()时,执行B进程,当两个进程都在sleep()时,则执行系统空闲任务,idle增加。
程序中执行i++这种类似程序时(用户逻辑),是用户态的,用户执行的时间增长(线程状态:运行态)
程序中执行read()这种类似的程序时(系统调用),是系统态的,系统内核执行时间增长(线程状态:运行态)
程序中执行sleep()这种类似的程序时(休眠动作,等待锁),是空闲态的,空闲系统进程执行时间增长(线程状态:阻塞态)
一个傻逼等待如下
delay()
{
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
for(i=0;i<10000000;i++);
}
}
main ()
{
for(j=0;i<10;j++) {
print(j);
delay();//一直在跑CPU,也能实现等待,但是idle是超低的,CPU负载大,不释放CPU
sleep(2);//释放CPU了,idle大
}
}
除了cpu.idle,还用什么衡量
cpu.load被定义为在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进程数
进程分为三种状态,一种是阻塞的进程blocked process,一种是可运行的进程runnable process,另外就是正在运行的进程running process
系统的load是指正在运行和准备好运行的进程的总数
如何评估cpu.load
如果cpu.load过大则表示有部分线程在等待获得cpu资源,过小表示cpu资源比较空闲。
对于cpu.load多少开始出现性能问题,外界有不同的说法,有的认为cpu.load/cores最好不要超过1,有的认为cpu.load/cores最好不要超过3,有的认为cpu.load不超过2*cores-2即可。
针对技术商服务进行压测时,发现load低时,接口TP999响应时间<50ms,而cpu.load/cores>4时,TP999响应时间约为200ms左右,多出来的时间可以理解为线程等待cpu处理的时间,可见cpu.load/cores过高时是影响接口响应时间的。
因此可以结合预期的接口响应时间,来定义每个服务的cpu.load/cores不超过多少。比如要求接口响应时间尽可能快的,最好确保cpu.load/cores不超过1,而对时间敏感性要求不太高时,一般要求cpu.load/cores不超过3。
说明:cores是几核,也就是几个CPU
如果load过大怎么处理
弹性扩容处理、手动扩容处理
什么是堆栈
堆是堆,栈是栈,堆是需要在程序执行时申请内存的(比如JAVA中new对象),并且内存在申请后不能自动释放的,JAVA中依靠GC清除废弃的内存的;
栈是程序执行时保存程序的执行路径的,包括函数地址,变量和函数的参数,栈是先进后出的,当前函数执行完毕,就把当前函数的变量等信息都弹出;所以栈时实时的去更新CPU的,不需要人为的清理
什么是垃圾回收机制GC
复制、标记清除、标记压缩
线程和进程的区别是什么?
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
线程的状态有几种
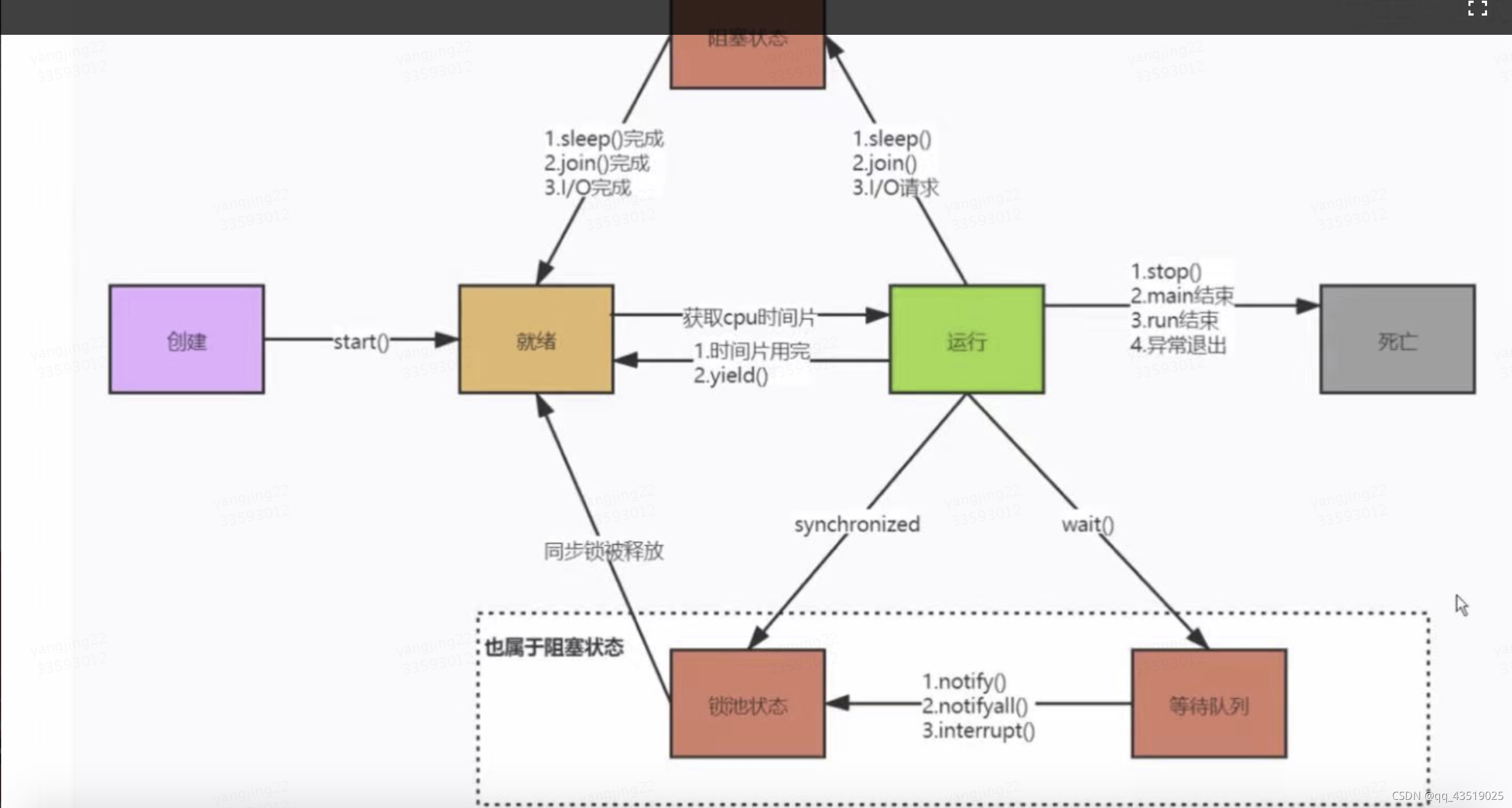
线程和进程都是上面五种状态,线程是一种特殊的进程
创建线程的方式有哪些,它们的区别是什么
继承Thread类、实现接口runnable、实现Callable接口,使用FutureTask类包装
在继承和使用当前线程上面思考
进程之间的通信方式
消息队列通信、共享内存通信(向操作系统指定一块内存)、套接字( socket )
TCP/IP,HTTP协议,通过socket发出去
线程之间的通信方式
volatile关键字、Object类提供了线程间通信的方法:wait()、notify()、notifyaAl()
HTTP和HTTPS的区别
HTTP用的端口号是80号端口,HTTPS用的端口号是443
HTTP是超文本传输协议,信息采用铭文传输,HTTPS是具有安全性SSL加密的传输协议
HTTP协议建立链接的过程比HTTPS协议更快,因为HTTPS除了三次握手还要经历SSL握手;
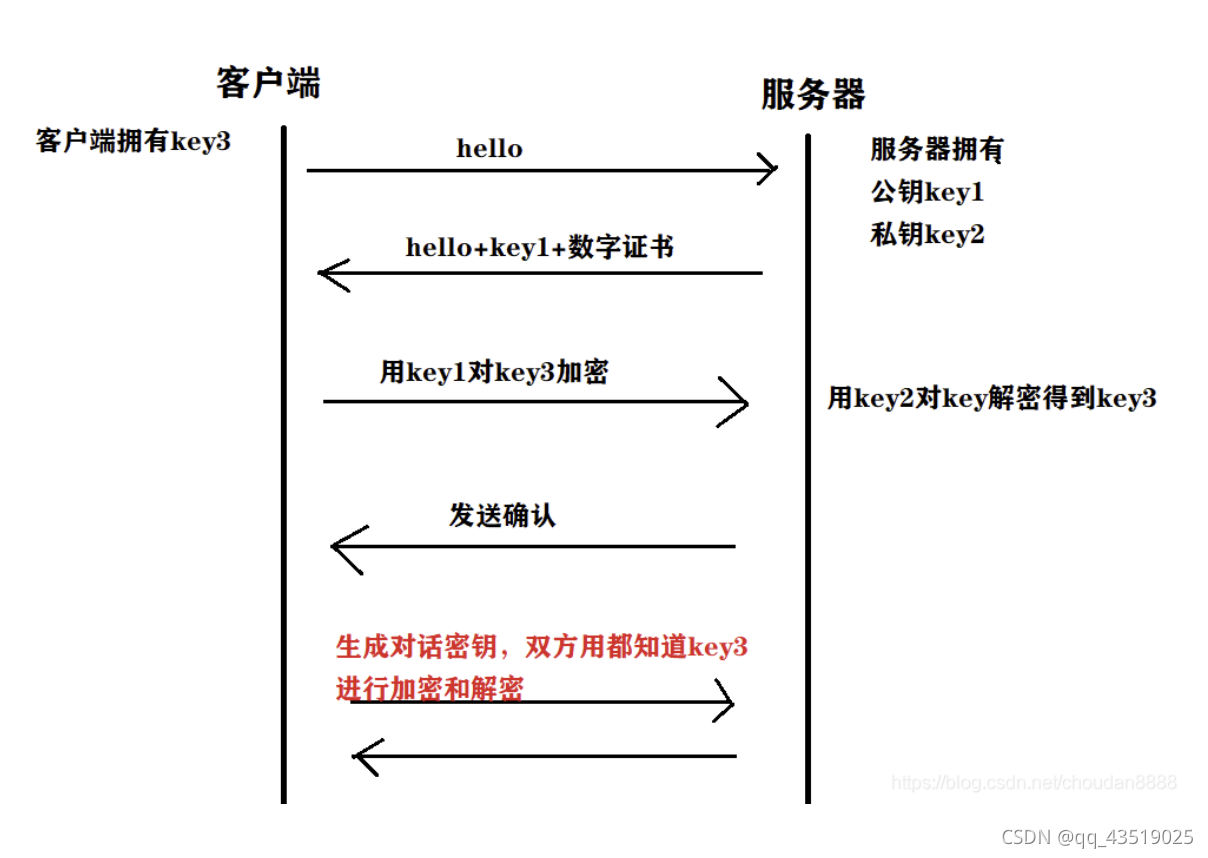
SSL建立连接的原理
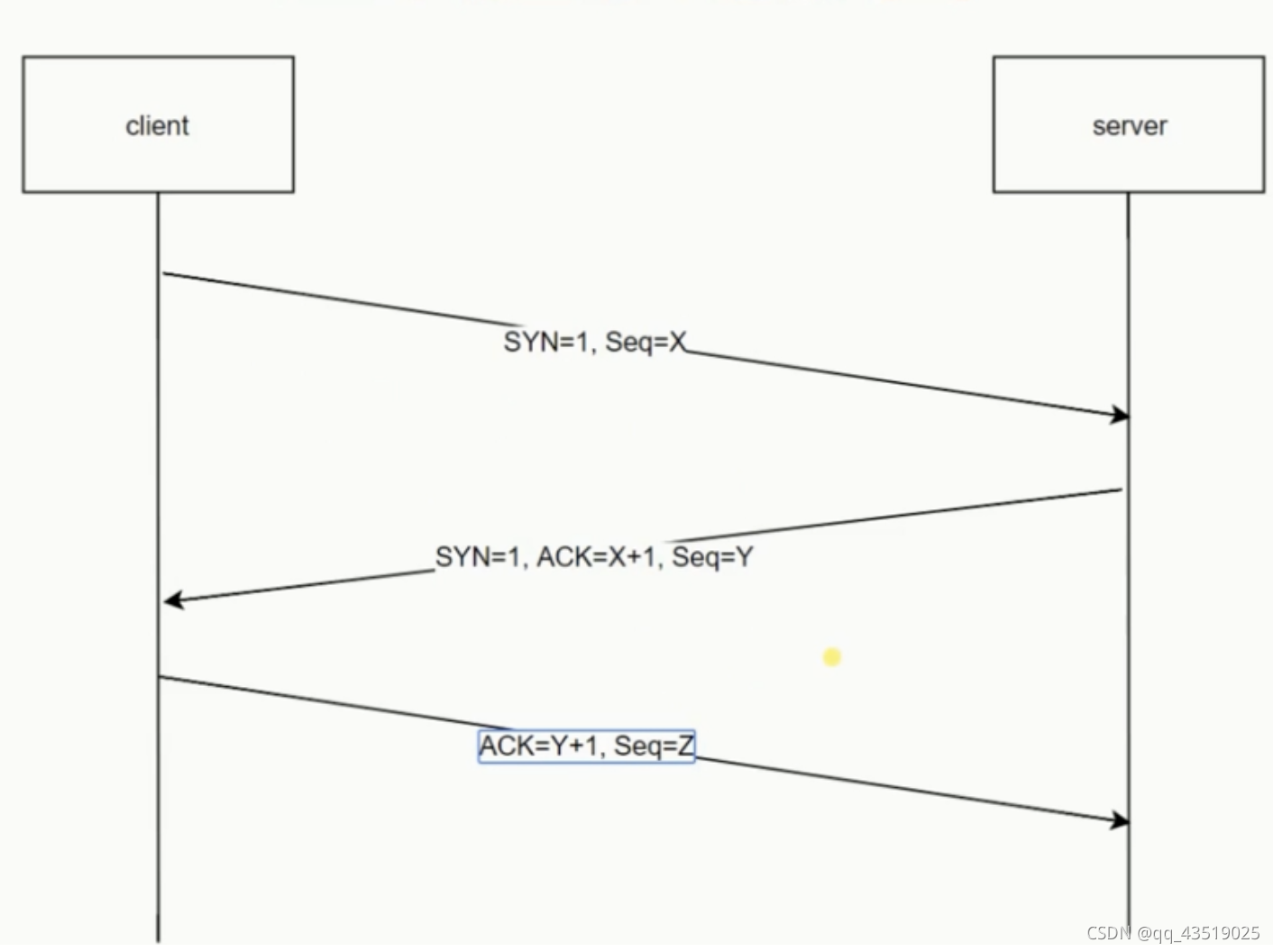
三次握手和四次挥手的过程
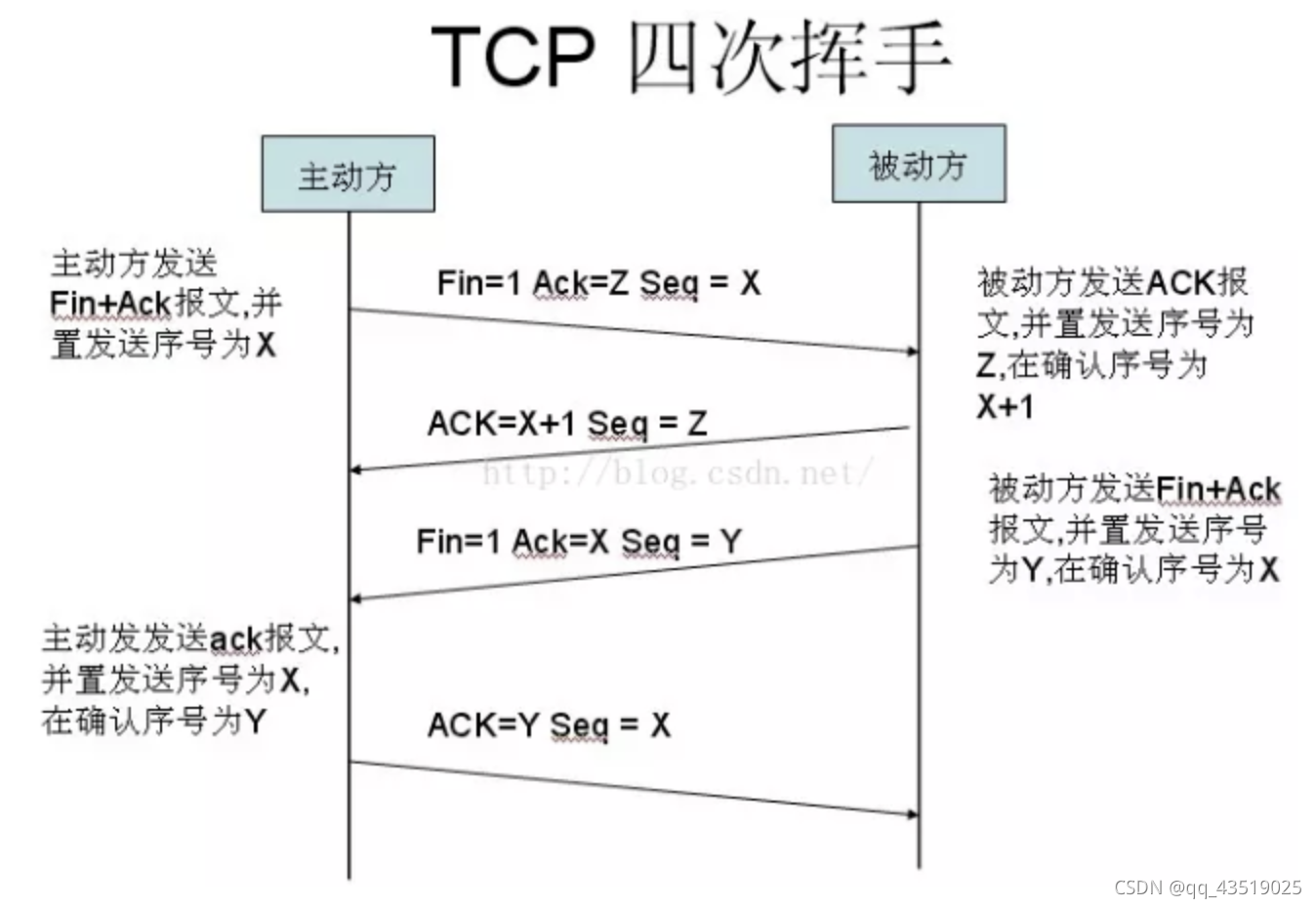
为什么是四次挥手
因为服务端可能还有消息没有发送到客户端
OSI七层模型及各层作用

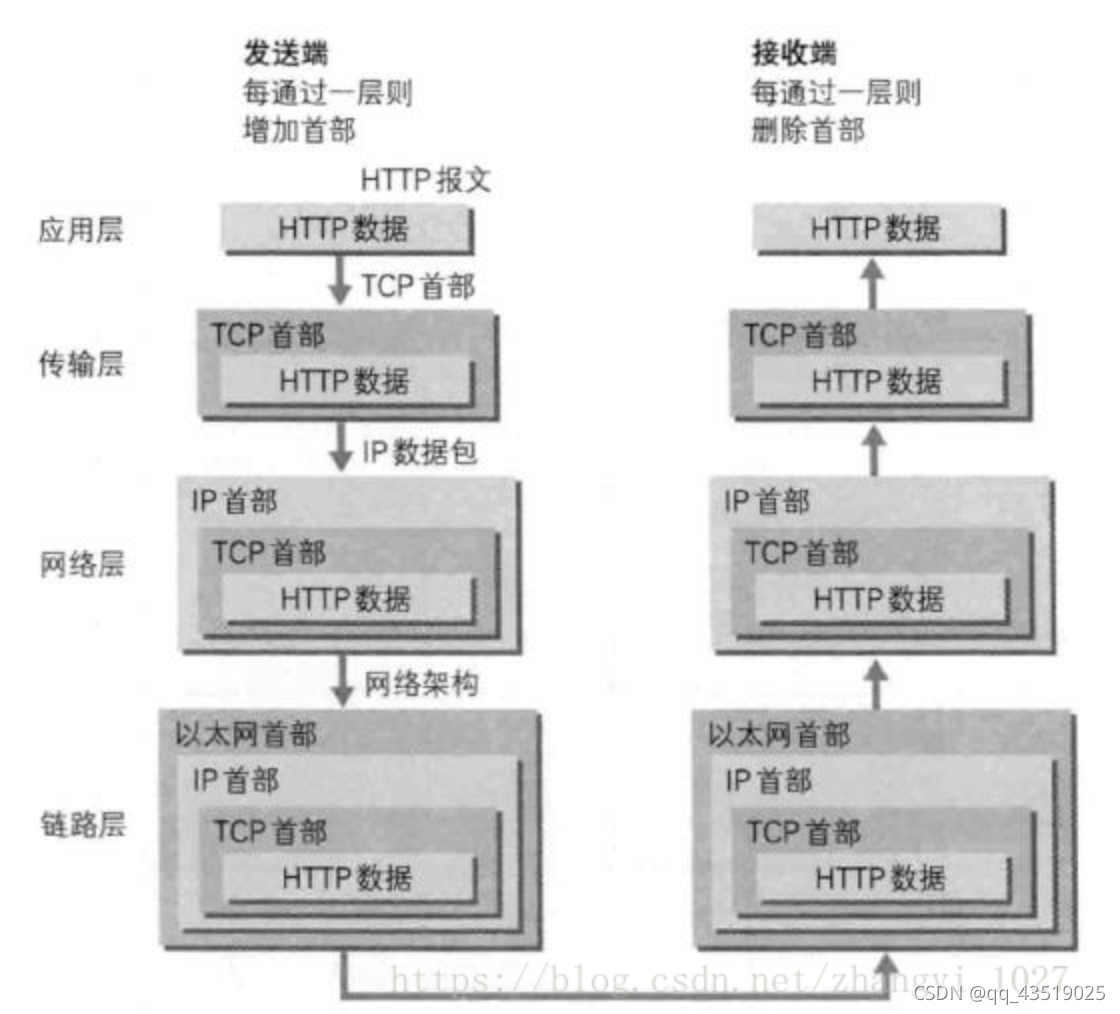
TCP和UDP的区别
TCP 是面向连接的,UDP 是面向无连接的
TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
TCP 保证数据正确性,UDP 可能丢包
TCP 保证数据顺序,UDP 不保证
UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
TCP数据传输慢,UDP数据传送快
每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。
TCP对系统资源要求较多,UDP对系统资源要求较少。
TCP 是面向字节流的,UDP 是基于数据报的。
TCP相比UDP为什么是可靠的
1、确认和重传机制 2、数据排序 3、流量控制 4、拥塞控制:“慢启动”、“拥塞避免”、“快速重传 ”、“快速恢复”
HTTP的常用状态码

404:服务器无法根据客户端的请求找到资源
500:服务器内部错误,无法完成请求
锁类型有哪些
乐观锁、悲观锁
死锁产生的原因及四个必要条件及如何解决
两把锁调用顺序不一致导致的(至少两把锁,一把锁不可能产生死锁)
原因:
1) 系统资源不足;
2) 进程运行推进的次序不合适;
3) 资源分配不当。
四个条件:
1) 互斥条件:一个资源一次只能被一个进程访问。
2) 请求与保持: 一个进程因请求资源而阻塞时,对已获得的资源保持不放。
3) 不可剥夺:进程已获得的资源,在未使用完之前,不得强行剥夺。
4) 循环等待:若干进程之间形成一种头尾相接的循环等待资源关系。
解决方式:两把锁调用顺序一致、超时放弃
为什么用锁
并发+资源共享
Mysql如何做分布式锁

索引的类型有哪些
普通索引、唯一索引、主键索引、组合索引、全文索引
创建索引的三种方式
在执行create table时创建索引
使用Alter table命令去增加索引
使用create index命令来创建
索引为什么查询快
B+树
B+树的关键字全部存放在叶子节点中,非叶子节点用来做索引,而叶子节点中有一个指针指向一下个叶子节点。做这个优化的目的是为了提高区间访问的性能。而正是这个特性决定了B+树更适合用来存储外部数据。
Mysql为什么要主从复制

Mysql主从复制的原理是什么?
(1)master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,则将其改变写入二进制日志中;
(2)slave服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/OThread请求master二进制事件
(3)同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/OThread和SQLThread将进入睡眠状态,等待下一次被唤醒。
也就是说:
- 从库会生成两个线程,一个I/O线程,一个SQL线程;
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
- 主库会生成一个log dump线程,用来给从库I/O线程传binlog;
- SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;

如何解决慢查询

数据库的三范式是什么?
列不可再拆分、属性完全依赖主键、不可传递依赖
数据库的隔离级别
可重复读、读取提交内容、读取未提交内容、可串行化
MySQL默认是可重复读,但会导致“幻读”,存储引擎通过多版本并发控制机制解决了幻读问题。
脏读:一个事务读取了未提交事务执行过程中的数据
不可重复读:对于数据库中的某个数据,一个事务执行过程中多次查询返回不同查询结果,这就是在事务执行过程中,数据被其他事务提交修改了
虚读(幻读):幻读是事务非独立执行时发生的一种现象,例如事务T1批量对一个表中某一列列值为1的数据修改为2的变更,但是在这时,事务T2对这张表插入了一条列值为1的数据,并完成提交。此时,如果事务T1查看刚刚完成操作的数据,发现还有一条列值为1的数据没有进行修改,而这条数据其实是T2刚刚提交插入的,这就是幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点同脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体
数据库的左外连接和右外连接

事务的特性是什么
原子性、一致性、隔离性、持久性
ACID靠什么保障的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









