




 本文探讨了如何利用Word2vec技术将音乐转化为语义向量,以此来捕获音乐的调性和和弦信息。通过在音乐数据集上训练skip-gram模型,结果显示,音乐切片的语义被有效捕获,和弦间的音调关系以及调的信息在嵌入空间中得以体现,证明了音乐和语言在向量化表示上的相似性,为音乐生成和其他应用奠定了基础。
本文探讨了如何利用Word2vec技术将音乐转化为语义向量,以此来捕获音乐的调性和和弦信息。通过在音乐数据集上训练skip-gram模型,结果显示,音乐切片的语义被有效捕获,和弦间的音调关系以及调的信息在嵌入空间中得以体现,证明了音乐和语言在向量化表示上的相似性,为音乐生成和其他应用奠定了基础。
机器学习算法在视觉领域和自然语言处理领域已经带来了很大的改变。但是音乐呢?近几年,音乐信息检索领域一直在飞速发展。这篇文章写的是NLP的一些技术是如何移植到音乐领域的。探寻了一种使用流行的 NLP 技术 word2vec 来表示复调音乐的方法。让我们来探究一下这是如何做到的……
Word2vec
词嵌入模型使我们能够通过有意义的方式表示词汇,这样机器学习模型就可以更容易地处理它们。这些词嵌入模型让我们可以用包含语义的向量来表示词汇。Word2vec 是一个流行的词向量嵌入模型,由 Mikolov 等人于 2013 年开发,它能够以一种十分有效的方式创建语义向量空间。
Word2vec 的本质是一个简单的单层神经网络,它有两种构造方式:1)使用连续词袋模型(CBOW);或 2)使用 skip-gram 结构。这两种结构都非常高效,并且可以相对快速地进行训练。在本研究中,我们使用的是 skip-gram 模型,因为 Mikolov 等人在 2013 年的工作中提到,这个方法对于较小的数据集更加高效。Skip-gram 结构使用当前词 w_t 作为输入(输入层),并尝试预测在窗口范围内与之前后相邻的词(输出层):
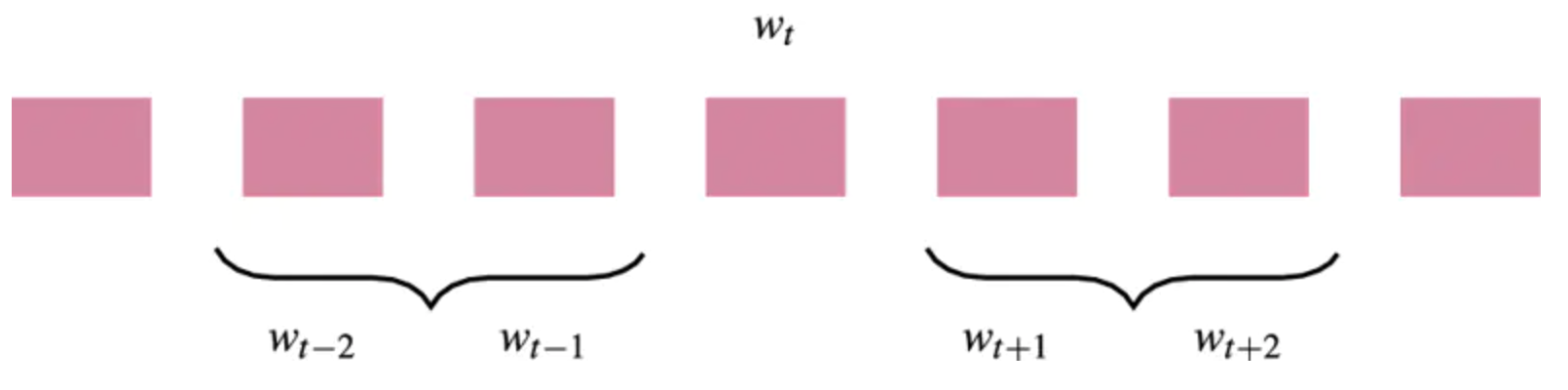
由于一些在网上流传的图片,人们对于 skip-gram 结构的样子存在一些疑惑。网络的输出层并不包含多个单词,而是由上下文窗口中的一个单词组成的。那么它如何才能表示整个上下文窗口呢?当训练网络时,我们实际会使用抽样对,它由输入单词和一个上下文窗口中的随机单词组成。
这种类型的网络的传统训练目标包含一个用 softmax 函数来计算 𝑝(𝑤_{𝑡+𝑖}|𝑤_𝑡) 的过程,而它的梯度计算代价是十分大的。幸运的是,诸如噪音对比估计(Gutmann 和 Hyvärine 于 2012 发表论文)和负采样(Mikolov 等人于 2013 年发表论文)等技术为此提供
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











