



 本文详细介绍ELK(Elasticsearch、Logstash、Kibana)与Spring Cloud的集成过程,涵盖Logstash与Kibana的安装配置,Spring Cloud项目创建,及与ELK的集成步骤。同时,探讨了Zipkin的集成与原理,分布式事务处理,以及如何使用RabbitMQ收集跟踪数据。
本文详细介绍ELK(Elasticsearch、Logstash、Kibana)与Spring Cloud的集成过程,涵盖Logstash与Kibana的安装配置,Spring Cloud项目创建,及与ELK的集成步骤。同时,探讨了Zipkin的集成与原理,分布式事务处理,以及如何使用RabbitMQ收集跟踪数据。
1.安装Logstash
(1)Logstash的作用是什么?
帮助我们收集数据(input),并将数据讲给ElasticSearch.(output)
2.安装Kibana
(1)Kibana的作用是什么
Kibana是图形化界面,帮助管理
3.Spring_Cloud与ELK的集成-创建项目
(1)创建Provider接口。
(2)创建Provider服务。
(3)修改POM文件,添加服务相关坐标。
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
(4)修改POM文件,添加sleuth启动器坐标、添加logstash坐标。
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
(5)修改配置文件,添加服务相关配置。
spring.application.name=sleuth-elk-product-provider
server.port=9001
#设置服务注册中心地址,指向另一个注册中心
eureka.client.serviceUrl.defaultZone=http://user:123456@eur
eka1:8761/eureka/,http://user:123456@eureka2:8761/eureka/
#--------------db----------------
mybatis.type-aliases-package=com.book.product.pojo
mybatis.mapper-locations=classpath:com/book/product/mapper/
*.xml
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/book-prod
uct?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavi
or=convertToNull
spring.datasource.username=root
spring.datasource.password=root
(6)创建Consumer服务
。
(7)修改POM文件,添加服务相关坐标。
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
(8)修改POM文件,添加sleuth启动器坐标、添加logstash坐标。
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
(9)修改配置文件,添加服务相关配置。
spring.application.name=sleuth-elk-consumer
server.port=9010
eureka.client.serviceUrl.defaultZone=http://user:123456@eur
eka1:8761/eureka/,http://user:123456@eureka2:8761/eureka/
4.Spring_Cloud与ELK的集成-操作ELK
(1)Kibana操作界面中的Discover的作用是什么?
Discover 主要是做索引查询,功能非常强大
(2)Kibana操作界面中的Visualize的作用是什么?
视图展示,支持许多风格。
(3)Kibana操作界面中的Timelion的作用是什么?
Timelion 是一个时间序列数据的可视化功能,可以结合在一个单一的可视化完全独立的数据源。它是由一个简单的表达式语言驱动的,你用来检索时间序列数据,进行计算,找出复杂的问题的答案,并可视化的结果。这个功能由一系列的功能函数组成,同样的查询的结果,也可以通过 Dashboard 显示查看。
(4)Kibana操作界面中的DevTools的作用是什么?
可以直接操作 es 中的数据,使用户方便的通过浏览器直接与 Elasticsearch 进行交互。
(5)Kibana操作界面中的Management的作用是什么?
管理中的应用是在你执行你的运行时配置 kibana,包括初始设置和指标进行配置模式,高级设置,调整自己的行为和 Kibana,各种“对象”,你可以查看保存在整个 Kibana 的内容如发现页,可视化和仪表板
5.什么是Zipkin
(1)什么是Zipkin?
(2)Zipkin和ELK有什么区别?

6.创建Zipkin服务端
(1)@EnableZipkinServer注解的作用是什么?
开启Zipkin服务
7.Spring Cloud与Zipkin的集成
(1)创建Provider服务接口项目。
(2)创建Provider服务。
(3)修改POM文件,添加相关坐标。
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
(4)修改POM文件,添加Zipkin坐标。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
(5)修改配置文件,添加服务相关配置。
spring.application.name=sleuth-zipkin-product-provider
server.port=9001
#设置服务注册中心地址,指向另一个注册中心
eureka.client.serviceUrl.defaultZone=http://user:123456@eur
eka1:8761/eureka/,http://user:123456@eureka2:8761/eureka/
spring.zipkin.base-url=http://127.0.0.1:9411
#--------------db----------------
mybatis.type-aliases-package=com.book.product.pojo
mybatis.mapper-locations=classpath:com/book/product/mapper/
*.xml
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/book-prod
uct?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
spring.datasource.username=root
spring.datasource.password=root
(6)修改配置文件,添加Zipkin URL配置。
spring.zipkin.base-url=http://127.0.0.1:9411
(7)创建Consumer服务。
(8)修改POM文件,添加相关坐标。
(9)修改POM文件,添加Zipkin坐标。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
(10)修改配置文件,添加服务相关配置。
spring.application.name=sleuth-zipkin-consumer
server.port=9010
spring.zipkin.base-url=http://127.0.0.1:9411
eureka.client.serviceUrl.defaultZone=http://user:123456@eur
eka1:8761/eureka/,http://user:123456@eureka2:8761/eureka/
(11)修改配置文件,添加Zipkin URL配置。
8.Zipkin的原理剖析
(1)Zipkin有哪些时间类型?每种事件类型表示什么含义?

(2)Zipkin的执行原理是什么?
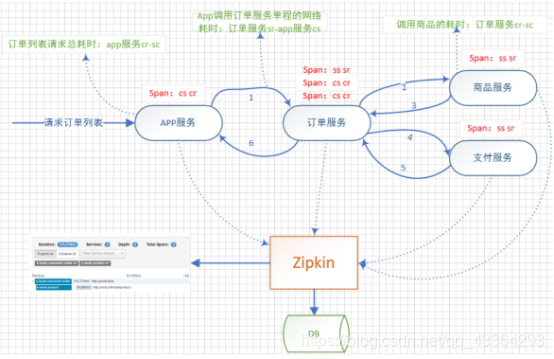
9.采用RabbitMQ收集Zipkin的跟踪数据-创建服务端
(1)@EnableZipkinStreamServer注解的作用是什么?
通过rabbitMQ获取数据的Zipkin服务
10.采用RabbitMQ收集Zipkin的跟踪数据-创建客户端
(1)创建Provider服务。
(2)需改POM文件,添加服务相关坐标。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
(3)修改POM文件,添加Zipkin Stream、Binder Rabbit坐标。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
(4)修改配置文件,添加服务相关配置。
spring.application.name=sleuth-zipkin-mq-product-provider
server.port=9001
#设置服务注册中心地址,指向另一个注册中心
eureka.client.serviceUrl.defaultZone=http://user:123456@eur
eka1:8761/eureka/,http://user:123456@eureka2:8761/eureka/
spring.rabbitmq.host=192.168.70.139
spring.rabbitmq.port=5672
spring.rabbitmq.username=zxw
spring.rabbitmq.password=123456
#--------------db----------------
mybatis.type-aliases-package=com.book.product.pojo
mybatis.mapper-locations=classpath:com/book/product/mapper/*.xml
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/book-prod
uct?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavi
or=convertToNull
spring.datasource.username=root
spring.datasource.password=root
(5)修改配置文件,添加RabbitMQ连接配置。
spring.rabbitmq.host=192.168.70.139
spring.rabbitmq.port=5672
spring.rabbitmq.username=zxw
spring.rabbitmq.password=123456
(6)创建Consumer服务。
(7)需改POM文件,添加服务相关坐标。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
(8)修改POM文件,添加Zipkin Stream、Binder Rabbit坐标。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
(9)修改配置文件,添加服务相关配置。
spring.application.name=sleuth-zipkin-consumer
server.port=9010
spring.rabbitmq.host=192.168.70.139
spring.rabbitmq.port=5672
spring.rabbitmq.username=zxw
spring.rabbitmq.password=123456
eureka.client.serviceUrl.defaultZone=http://user:123456@eur
eka1:8761/eureka/,http://user:123456@eureka2:8761/eureka/
(10)修改配置文件,添加RabbitMQ连接配置。
spring.rabbitmq.host=192.168.70.139
spring.rabbitmq.port=5672
spring.rabbitmq.username=zxw
spring.rabbitmq.password=123456
(11)访问Zipkin服务端查看结果。
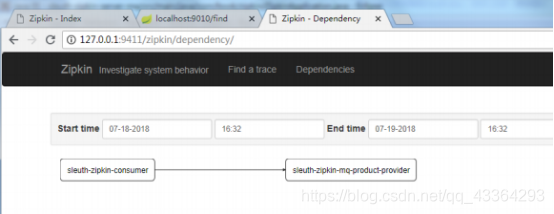
11.跟踪数据持久化到MySQL
(1)创建Zipkin服务端。
(2)修改POM文件,添加服务相关坐标。
(3)修改POM文件,添加MySQL数据库驱动坐标,添加jdbc启动器。
(4)修改配置文件,添加服务相关配置
(5)修改配置文件,添加Zipkin储存类型。
(6)执行MySQL脚本。
(7)访问Zipkin服务端,查看MySQL数据库中数据。
12.什么是分布式事务
(1)什么是分布式事务?
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位
于不同的分布式系统的不同节点之上。
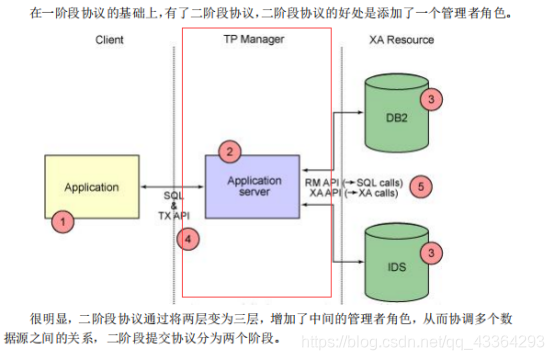
13.XA的两阶段提交方案
(1)什么是XA协议?
XA 协议由 Oracle Tuxedo 首先提出的,并交给 X/Open 组织,作为资源管理器(数据库)
与事务管理器的接口标准。目前,Oracle、Informix、DB2 和 Sybase 等各大数据库厂家都提
供对 XA 的支持。XA 协议采用两阶段提交方式来管理分布式事务。XA 接口提供资源管理
器与事务管理器之间进行通信的标准接口。
(2)什么是XA一阶段提交?
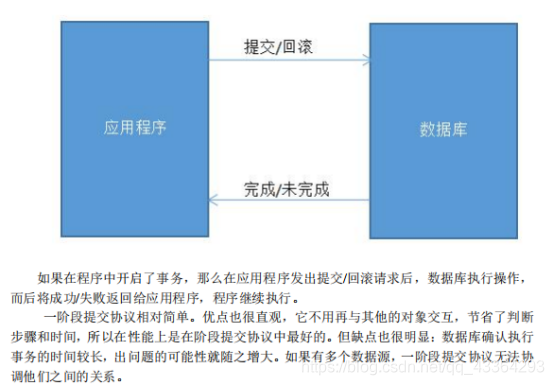
(3)什么是XA二阶段提交?
14.TCC分布式事务解决方案
(1)什么是TCC解决方案?
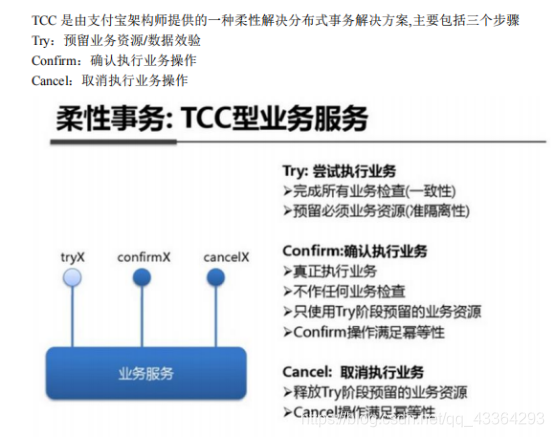
(2)TCC原理是什么?
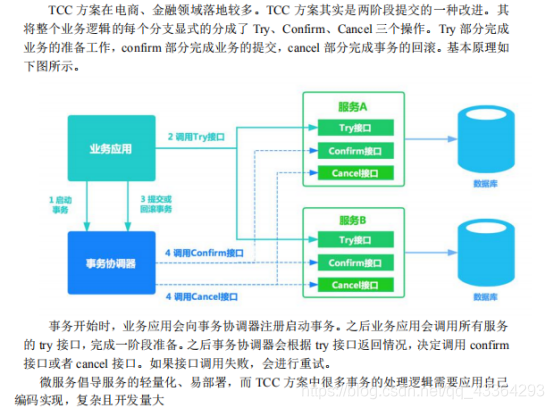
(3)TC优点是什么?
让应用自己定义数据库操作的粒度,使得降低锁冲突、提高吞吐量成为可能。
(4)TCC的缺点是什么?
对应用的侵入性强。业务逻辑的每个分支都需要实现 try、confirm、cancel
三个操作,应用侵入性较强,改造成本高。
实现难度较大。需要按照网络状态、系统故障等不同的失败原因实现不同的
回滚策略。为了满足一致性的要求,confirm 和 cancel 接口必须实现幂等。
15.分布式事务中间件解决方案
(1)什么是分布式事务中间件解决方案?
分布式事务中间件其本身并不创建事务,而是基于对本地事务的协调从而达到事务一致性
的效果。典型代表有:阿里的 GTS(https://www.aliyun.com/aliware/txc)、开源应用 LCN。
16.什么是LCN框架
(1)什么事LCN分布式事务处理框架?
LCN 并不生产事务,LCN 只是本地事务的协调工
在设计框架之初的 1.0 ~ 2.0 的版本时,框架设计的步骤是如下的,各取其首字母得来
的 LCN 命名。
锁定事务单元(lock)、确认事务模块状态(confirm)、通知事务(notify)

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









