




 DF-GAN是针对文本到图像合成的生成对抗网络新模型,它解决了传统方法中生成器之间的纠缠、语义一致性不足及文本-图像融合不充分的问题。DF-GAN采用一级主干网络直接生成高分辨率图像,目标感知鉴别器通过匹配感知梯度惩罚和单向输出提升语义一致性,并通过深度文本-图像融合块更有效地融合文本信息。实验结果显示,DF-GAN在CUB和COCO数据集上超越了现有先进模型。
DF-GAN是针对文本到图像合成的生成对抗网络新模型,它解决了传统方法中生成器之间的纠缠、语义一致性不足及文本-图像融合不充分的问题。DF-GAN采用一级主干网络直接生成高分辨率图像,目标感知鉴别器通过匹配感知梯度惩罚和单向输出提升语义一致性,并通过深度文本-图像融合块更有效地融合文本信息。实验结果显示,DF-GAN在CUB和COCO数据集上超越了现有先进模型。
题目:DF-GAN:一种简单有效的文本-图像合成基线
时间:2022
CVPR
Abstract
从文字描述中合成高质量的逼真图像是一项具有挑战性的任务。现有的文本-图像生成对抗网络通常采用堆叠架构作为主干,但仍存在三个缺陷。首先,分层结构引入了不同图像尺度的生成器之间的纠缠。其次,现有的研究倾向于在对抗学习中应用和固定额外的网络来实现文本图像语义一致性,这限制了这些网络的监督能力。第三,以往广泛采用的基于注意的跨模态文本图像融合算法由于计算成本的原因,在一些特殊的图像尺度上受到限制。为此,我们提出了一种更简单但更有效的深度融合生成对抗网络(DF-GAN)。具体而言,我们提出:(i)一种新颖的单阶段文本-图像骨干,可以直接合成高分辨率图像,而不存在不同生成器之间的纠缠;(ii)一种新颖的由匹配感知梯度惩罚和单向输出组成的目标感知鉴别器,可以在不引入额外网络的情况下增强文本-图像语义一致性;(iii)一种新颖的深度文本-图像融合块,深化融合过程,使文本和视觉特征完全融合。与目前最先进的方法相比,我们提出的DFGAN更简单,更有效地合成真实和文本匹配的图像,并在广泛使用的数据集上获得更好的性能。DFGAN代码
Introduction
- 在过去几年中,生成对抗网络(GANs)在各种应用中取得了巨大的成功。其中,文本-图像合成是GANs最重要的应用之一。它旨在从给定的自然语言描述中生成真实和文本一致的图像。由于其实用价值,文本-图像合成近年来成为一个活跃的研究领域。
- 文本到图像合成的两个主要挑战是生成图像的真实性,以及给定文本和生成图像之间的语义一致性。由于GAN模型的不稳定性,最近的模型大多采用堆叠架构作为骨干来生成高分辨率图像。他们利用跨模态注意融合文本和图像特征,然后引入DAMSM网络、循环一致性或暹罗网,通过额外的网络来保证文本图像语义一致性。
- 虽然前人的研究成果令人印象深刻,但仍存在三个问题:首先,堆叠架构引入了不同生成器之间的纠缠,这使得最终细化的图像看起来像模糊形状和一些细节的简单组合。如图1(a)所示,最终的细化图像有着由G0合成的模糊形状,由G1合成的粗属性(如eye和beak) 以及由G2添加的细粒度细节(例如,眼睛反射)。最终合成的图像看起来像是不同图像尺度的视觉特征的简单组合。其次,现有研究通常在对抗性训练中固定额外的网络[33,50],使得这些网络很容易被生成器愚弄而合成对抗性特征[30,52],从而削弱了它们对语义一致性的监督能力。第三,跨模态注意[50]不能充分利用文本信息。由于计算成本高,它们只能在64×64和128×128图像特征上应用两次。它限制了文本图像融合过程的有效性,使模型难以扩展到更高分辨率的图像合成。
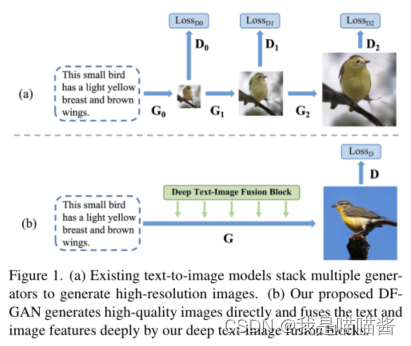
- 为了解决上述问题,我们提出了一种新的文本-图像生成方法,称为深度融合生成对抗网络(DF-GAN)。对于第一个问题,我们将堆叠的主干替换为一级主干。它由铰链损失和残差网络组成,可以稳定GAN训练过程,直接合成高分辨率图像。由于一级主干网中只有一个生成器,避免了不同生成器之间的纠缠。第二,设计了一个由匹配感知梯度惩罚(match - aware Gradient Penalty, MA-GP)和单向输出(One-Way Output)组成的目标感知鉴别器,以提高文本图像的语义一致性。MA-GP是鉴别器上的一种正则化策略。它追求目标数据(真实和文本匹配图像)上鉴别器的梯度为零。因此,MA-GP在真实和匹配的数据点处构建平滑的损失面,从而进一步促进生成器合成与文本匹配的图像。此外,考虑到之前的双向输出减慢了MA-GP下生成器的收敛过程,我们将其替换为更有效的单向输出。在第三个问题中,我们提出了深度文本-图像融合块(Deep text-image Fusion Block, DFBlock),以更有效地将文本信息融合到图像特征中。DFBlock由几个仿射变换组成。仿射变换是一个轻量级模块,它通过通道缩放和移动操作来操作可视特征图。在所有图像尺度上叠加多个DFBlock加深了文本-图像融合过程,使文本和视觉特征完全融合。
- 总体而言,我们的贡献可以总结如下:我们提出了一种新颖的单阶段文本到图像主干,可以直接合成高分辨率图像,而不会在不同生成器之间产生纠缠。我们提出了一种新的目标感知鉴别器,由匹配感知梯度惩罚(MA-GP)和单向输出组成。在不引入额外网络的情况下,显著提高了文本图像语义一致性。本文提出了一种新颖的**深度文本图像融合块 **(DFBlock),能够更有效、更深入地融合文本和视觉特征。在两个具有挑战性的数据集上进行的大量定性和定量实验表明,所提出的DF-GAN优于现有的最先进的文本到图像模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









