




MySQL - 奇技淫巧
文章目录
一:Json格式-存储灵活数据
这个功能要支持用户自定义主题、通知设置、字体大小…"
如果每个设置都建一个字段,那表结构得多臃肿啊!后来发现 MySQL 的 JSON 类型简直就是救星!
-- 创建用户偏好表,使用 JSON 类型存储灵活配置
CREATE TABLE user_preferences (
id INT PRIMARY KEY COMMENT '主键ID',
user_id INT COMMENT '用户ID',
preferences JSON COMMENT '用户偏好设置(JSON格式)'
) COMMENT='用户偏好表';
-- 插入测试数据(直接将每一个用户的自定义信息作为Json字段存储起来)
INSERT INTO user_preferences VALUES
(1, 1, '{"theme": "dark", "notifications": true, "fontSize": 14}'),
(2, 2, '{"theme": "light", "notifications": false, "fontSize": 16}'),
(3, 3, '{"theme": "dark", "notifications": true, "fontSize": 12}');
-- 查询 JSON 数据 (preferences -> '$.theme')表示将preferences中的theme字段拿到
SELECT preferences->'$.theme' FROM user_preferences WHERE user_id = 1;
二:with rollup-总计
适用于不仅要看每个部门的薪资情况,还要看总计类的情况(就是同时计算出小计)
-- 创建员工表
CREATE TABLE employees (
id INT PRIMARY KEY COMMENT '员工ID',
name VARCHAR(50) COMMENT '员工姓名',
department VARCHAR(50) COMMENT '所属部门',
salary DECIMAL(10,2) COMMENT '薪资'
) COMMENT='员工信息表';
-- 插入测试数据
INSERT INTO employees VALUES
(1, '张三', '技术部', 15000.00),
(2, '李四', '技术部', 18000.00),
(3, '王五', '技术部', 17000.00),
(4, '赵六', '市场部', 12000.00),
(5, '钱七', '市场部', 13000.00),
(6, '孙八', '人事部', 10000.00),
(7, '周九', '人事部', 11000.00);
-- 统计各部门员工数量和薪资总和,并计算总计
SELECT
department,
COUNT(*) as employee_count,
SUM(salary) as total_salary
FROM employees
GROUP BY department WITH ROLLUP;
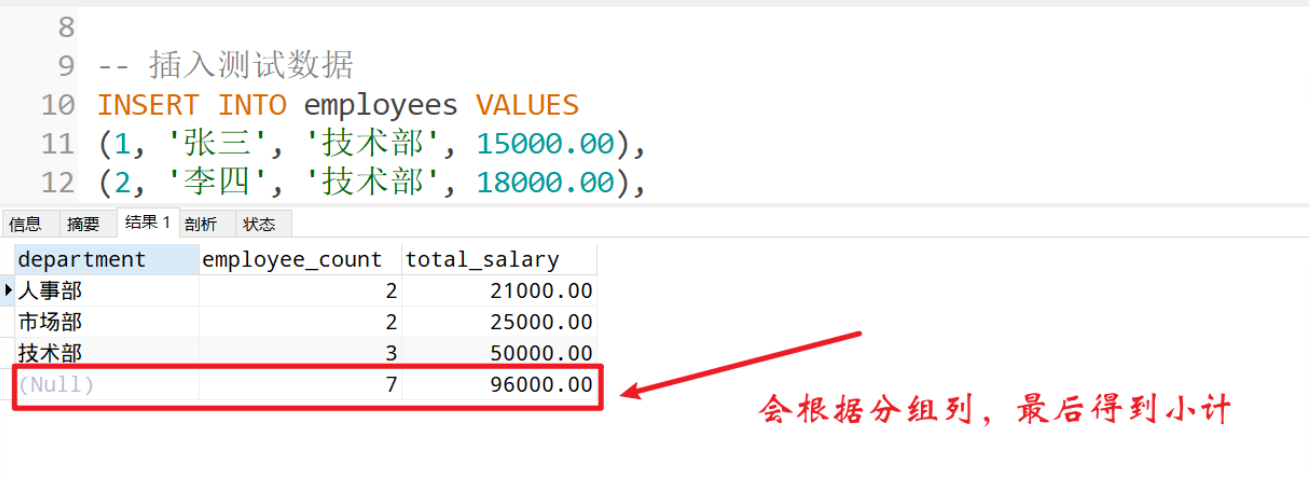
这样不管是前端还是后端拿到信息之后就可以通过部门字段是否为空进行判断是否是小计行。
三:case when-条件统计
一般用于状态统计比较多,例如离线人数,在线人数等等
-- 创建用户表
CREATE TABLE users (
id INT PRIMARY KEY COMMENT '用户ID',
name VARCHAR(50) COMMENT '用户名',
status VARCHAR(20) COMMENT '用户状态'
) COMMENT='用户信息表';
-- 插入测试数据
INSERT INTO users VALUES
(1, '张三', 'active'),
(2, '李四', 'active'),
(3, '王五', 'inactive'),
(4, '赵六', 'active'),
(5, '钱七', 'inactive');
-- 统计活跃和非活跃用户数量
SELECT
SUM(CASE WHEN status = 'active' THEN 1 ELSE 0 END) as active_users,
SUM(CASE WHEN status = 'inactive' THEN 1 ELSE 0 END) as inactive_users
FROM users;
四:insert ignore-避免重复插入
在处理批量导入数据时,遇到重复数据直接跳过,不会报错,让程序继续运行
-- 创建用户表(如果之前没创建)
CREATE TABLE users (
id INT PRIMARY KEY COMMENT '用户ID',
name VARCHAR(50) COMMENT '用户名',
email VARCHAR(100) COMMENT '邮箱'
) COMMENT='用户信息表';
-- 插入测试数据
INSERT INTO users VALUES
(1, '张三', 'zhangsan@example.com'),
(2, '李四', 'lisi@example.com');
-- 使用 INSERT IGNORE 插入数据,遇到重复则跳过
INSERT IGNORE INTO users (id, name, email) VALUES
(1, '张三', 'zhangsan@example.com'),
(3, '王五', 'wangwu@example.com');
五:on duplicate key update-插入或更新
用户更新个人信息,如果用户已存在就更新,不存在就插入,一行代码搞定
-- 使用 ON DUPLICATE KEY UPDATE 实现插入或更新
INSERT INTO users (id, name, email)
VALUES
(1, '张三', 'zhangsan_new@example.com'),
(4, '赵六', 'zhaoliu@example.com') -- 可以发现前半部分就是插入语句
ON DUPLICATE KEY UPDATE name = VALUES(name), email = VALUES(email); -- 后面表示如果存在key了,更新那些字段
六:find in set-集合查询
有时候我们需要查询某个分类下的所有商品,如果分类 ID 是以逗号分隔的字符串,用 FIND_IN_SET 就能轻松搞定!
这个技巧在处理多对多关系时特别有用。
-- 创建商品表
CREATE TABLE products (
id INT PRIMARY KEY COMMENT '商品ID',
name VARCHAR(100) COMMENT '商品名称',
category_ids VARCHAR(100) COMMENT '分类ID列表(逗号分隔)'
) COMMENT='商品信息表';
-- 插入测试数据
INSERT INTO products VALUES
(1, '商品A', '1,2,3'),
(2, '商品B', '2,3,4'),
(3, '商品C', '1,4'),
(4, '商品D', '3,4,5'),
(5, '商品E', '1,5,6');
-- 查询指定分类下的所有商品
SELECT * FROM products
WHERE FIND_IN_SET('1', category_ids); -- 那个商品包含分类id为1的??
七:group_concat-多行数据合并展示
这个功能在做报表时特别有用。比如要显示每个部门的所有员工名单,不用在代码里拼接,直接让数据库帮你搞定!
-- 使用 GROUP_CONCAT 合并部门员工名单
SELECT
department,
GROUP_CONCAT(name SEPARATOR ', ') as employees -- 每一个部门的员工用,拼接起来作为employees字段返回
FROM employees
GROUP BY department;
八:exists-代替in操作
这个技巧可以帮你优化查询性能。比如要找出所有包含高价商品的订单,用 EXISTS 比用 IN 子查询要快得多!
-- 创建订单表
CREATE TABLE orders (
id INT PRIMARY KEY COMMENT '订单ID',
user_id INT COMMENT '用户ID',
created_at DATETIME COMMENT '创建时间'
) COMMENT='订单表';
-- 创建订单项表
CREATE TABLE order_items (
id INT PRIMARY KEY COMMENT '订单项ID',
order_id INT COMMENT '订单ID',
price DECIMAL(10,2) COMMENT '商品价格'
) COMMENT='订单项表';
-- 插入测试数据
INSERT INTO orders VALUES
(1, 1001, '2024-03-20 10:00:00'),
(2, 1002, '2024-03-20 11:00:00'),
(3, 1002, '2024-03-20 11:30:00'),
(4, 1003, '2024-03-20 12:00:00'),
(5, 1003, '2024-03-20 14:15:00');
INSERT INTO order_items VALUES
(1, 1, 150.00),
(2, 1, 80.00),
(3, 2, 90.00),
(4, 3, 200.00),
(5, 4, 70.00),
(6, 5, 180.00);
-- 使用 EXISTS 查询包含高价商品的订单
SELECT * FROM orders o
WHERE EXISTS (
SELECT 1 FROM order_items oi
WHERE oi.order_id = o.id
AND oi.price > 100 -- 订单项表大于100的,其实就是先过滤一遍,然后主查询在过滤后的里面寻找就好了
);
九:row_number()-实现分页
做分页查询时,这个技巧特别有用。
不用写复杂的子查询,直接给每行数据编号,然后按编号筛选,简单又高效!
-- 创建文章表
CREATE TABLE articles (
id INT PRIMARY KEY COMMENT '文章ID',
title VARCHAR(200) COMMENT '文章标题',
content TEXT COMMENT '文章内容',
created_at DATETIME COMMENT '创建时间'
) COMMENT='文章表';
-- 插入测试数据
INSERT INTO articles VALUES
(1, '文章1', '内容1', '2024-03-20 09:00:00'),
(2, '文章2', '内容2', '2024-03-20 10:00:00'),
(3, '文章3', '内容3', '2024-03-20 11:00:00'),
(4, '文章4', '内容4', '2024-03-20 12:00:00'),
(5, '文章5', '内容5', '2024-03-20 13:00:00'),
(6, '文章6', '内容6', '2024-03-20 14:00:00'),
(7, '文章7', '内容7', '2024-03-20 15:00:00'),
(8, '文章8', '内容8', '2024-03-20 16:00:00'),
(9, '文章9', '内容9', '2024-03-20 17:00:00'),
(10, '文章10', '内容10', '2024-03-20 18:00:00');
-- 使用 ROW_NUMBER() 实现分页查询
SELECT * FROM (
SELECT
*,
-- 根据创建时间倒排,然后用row_number()函数进行编号并命名为row_num
ROW_NUMBER() OVER (ORDER BY created_at DESC) as row_num
FROM articles
) as t
-- 然后就可以使用row_num进行分页查询了,between...and
WHERE row_num BETWEEN 5 AND 10;
🎉 现在在框架中如果使用mybatis等一般都不会这样分页,但是这也是一个方法
十:with子句-处理复杂查询
这个功能让复杂的查询变得清晰易读。
比如要统计用户订单情况,可以先把统计数据算出来,然后再和其他表关联,代码结构清晰多了!
-- 使用 WITH 子句优化复杂查询 - 将用户统计出来,备用
WITH user_stats AS (
SELECT
user_id,
COUNT(*) as order_count,
SUM(amount) as total_amount
FROM orders
GROUP BY user_id
)
# 再和其他表进行关联,比较清晰
SELECT
u.name,
us.order_count,
us.total_amount
FROM users u
JOIN user_stats us ON u.id = us.user_id;
十一:日期时间和字符串的转换
1:日期到字符串
-- 使用date-format转换:日期 -> 字符串
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s') AS formatted_date;
-- 结果: '2023-05-15 14:30:22'
SELECT DATE_FORMAT('2023-05-15', '%W, %M %e, %Y') AS readable_date;
-- 结果: 'Monday, May 15, 2023'
2:字符串到日期
-- 使用str_to_date()函数进行 字符串 -> 日期
SELECT STR_TO_DATE('15-05-2023', '%d-%m-%Y') AS date_value;
-- 结果: '2023-05-15'
SELECT STR_TO_DATE('May 15, 2023 14:30', '%M %d, %Y %H:%i') AS datetime_value;
-- 结果: '2023-05-15 14:30:00'
3:unix时间戳
-- unix时间戳的转换
-- 时间戳转日期
SELECT FROM_UNIXTIME(1684143022) AS normal_date;
-- 结果: '2023-05-15 14:30:22'
-- 日期转时间戳
SELECT UNIX_TIMESTAMP('2023-05-15 14:30:22') AS unix_timestamp;
-- 结果: 1684143022
4:日期时间内容提取
-- 提取日期和时间部分
SELECT DATE('2023-05-15 14:30:22') AS only_date; -- '2023-05-15'
SELECT TIME('2023-05-15 14:30:22') AS only_time; -- '14:30:22'
SELECT YEAR('2023-05-15') AS year_part; -- 2023
SELECT MONTH('2023-05-15') AS month_part; -- 5
SELECT DAY('2023-05-15') AS day_part; -- 15
5:日期时间的计算
-- 日期时间计算
-- 添加时间间隔
SELECT DATE_ADD('2023-05-15', INTERVAL 1 DAY) AS next_day;
SELECT ADDDATE('2023-05-15', 7) AS next_week;
-- 减去时间间隔
SELECT DATE_SUB('2023-05-15', INTERVAL 1 MONTH) AS last_month;
SELECT SUBDATE('2023-05-15', 30) AS days_ago;
-- 日期差值
SELECT DATEDIFF('2023-06-01', '2023-05-15') AS days_diff; -- 17
6:更多技巧
-- 获取当前日期和时间的不同格式
SELECT NOW() AS current_datetime; -- '2023-05-15 14:30:22'
SELECT CURDATE() AS current_date; -- '2023-05-15'
SELECT CURTIME() AS current_time; -- '14:30:22'
SELECT CURRENT_TIMESTAMP; -- '2023-05-15 14:30:22'
-- 处理不同格式的字符串
-- 处理美国格式日期 (MM/DD/YYYY)
SELECT STR_TO_DATE('05/15/2023', '%m/%d/%Y') AS us_date;
-- 处理欧洲格式日期 (DD.MM.YYYY)
SELECT STR_TO_DATE('15.05.2023', '%d.%m.%Y') AS eu_date;
-- 生成日期序列
-- 生成最近7天的日期
SELECT DATE_SUB(CURDATE(), INTERVAL n DAY) AS date_series
FROM (
SELECT 0 AS n UNION SELECT 1 UNION SELECT 2 UNION SELECT 3
UNION SELECT 4 UNION SELECT 5 UNION SELECT 6
) AS numbers;
十二:分页查询与数据插入并发导致的数据重复问题
在分页查询的同时不断往数据库插入数据时,传统的LIMIT offset, size分页方式会导致数据重复或遗漏
1:游标分页
使用唯一且有序的列(如自增ID、时间戳)作为游标
-- 第一页
SELECT * FROM table
WHERE status = 'active'
ORDER BY id DESC
LIMIT 10;
-- 后续页(使用上一页最后一条记录的ID)
SELECT * FROM table
WHERE status = 'active' AND id < 使用上一页最后一条记录的ID
ORDER BY id DESC
LIMIT 10;
2:使用事务隔离级别
这种方法在高并发下可能有性能问题,且不是所有场景都适用
-- 设置事务隔离级别为可重复读RR(其实默认的就是,不用改这个)
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN;
-- 查询总数
SELECT COUNT(*) FROM table WHERE conditions;
-- 查询当前页数据
SELECT * FROM table WHERE conditions ORDER BY id LIMIT offset, size;
COMMIT;
3:使用时间戳分页
适用于按时间排序的场景
-- 第一页
SELECT * FROM table
ORDER BY create_time DESC, id DESC
LIMIT 10;
-- 后续页
SELECT * FROM table
WHERE create_time < last_create_time OR
(create_time = last_create_time AND id < last_id)
ORDER BY create_time DESC, id DESC
LIMIT 10;
4:使用物化视图或临时表
-- 创建临时快照
CREATE TEMPORARY TABLE temp_pagination AS
SELECT id FROM table WHERE conditions ORDER BY sort_column;
-- 然后基于临时表分页
SELECT t.* FROM table t
JOIN temp_pagination tp ON t.id = tp.id
WHERE tp.position BETWEEN offset AND offset + size;
5:应用层缓存策略
- 首次查询时缓存结果集ID列表
- 后续分页直接使用缓存的ID列表获取数据
- 设置合理的缓存过期时间


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









