




Log4j和Log4j2
文章目录
一:Log4j
1:选择不同日志级别的重要性
使用 Java 日志的时候,一定要注意日志的级别,比如常见的 DEBUG、INFO、WARN 和 ERROR。
- DEBUG 的级别最低,当需要打印调试信息的话,就用这个级别,不建议在生产环境下使用。
- INFO 的级别高一些,当一些重要的信息需要打印的时候,就用这个。
- WARN,用来记录一些警告类的信息,比如说客户端和服务端的连接断开了,数据库连接丢失了。
- ERROR 比 WARN 的级别更高,用来记录错误或者异常的信息。
- FATAL,当程序出现致命错误的时候使用,这意味着程序可能非正常中止了。
- OFF,最高级别,意味着所有消息都不会输出了。
2:错误的日志记录方式是如何影响性能的
为什么说错误的日志记录方式会影响程序的性能呢?
因为日志记录的次数越多,意味着执行文件 IO 操作的次数就越多,这也就意味着会影响到程序的性能
虽然说普通硬盘升级到固态硬盘后,读写速度快了很多,但磁盘相对于内存和 CPU 来说,还是太慢了
这也就是为什么要选择日志级别的重要性。对于程序来说,记录日志是必选项,所以能控制的就是日志的级别,以及在这个级别上打印的日志。
对于 DEBUG 级别的日志来说,一定要使用下面的方式来记录:
if(logger.isDebugEnabled()){
logger.debug("DEBUG 是开启的");
}
当 DEBUG 级别是开启的时候再打印日志,这种方式在你看很多源码的时候就可以发现,很常见。
切记,在生产环境下,一定不要开启 DEBUG 级别的日志,否则程序在大量记录日志的时候会变很慢,还有可能在你不注意的情况下,悄悄地把磁盘空间撑爆。
3:为什么选择 Log4j
- Log4j 更好用。java.util.logging 的日志级别比 Log4j 更多,但用不着,就变成了多余
- 不需要重新启动 Java 程序就可以调整日志的记录级别,非常灵活。可以通过 log4j.properties 文件来配置 Log4j 的日志级别、输出环境、日志文件的记录方式
- Log4j 还是线程安全的,可以在多线程的环境下放心使用
4:使用log4j
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
# config rootLogger
log4j.rootLogger = debug,stdout,D,E
# config logger stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
# config logger debug
# if the log level is debug, the log will be output to debug.log
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = debug.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
# config logger error
# if the log level is error, the log will be output to error.log
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
配置根 Logger
log4j.rootLogger = [ level ] , appenderName, appenderName, …
level 就是日志的优先级,从高到低依次是 ERROR、WARN、INFO、DEBUG。
如果这里定义的是 INFO,那么低级别的 DEBUG 日志信息将不会打印出来。
appenderName 就是指把日志信息输出到什么地方,可以指定多个地方,当前的配置文件中有 3 个地方,分别是 stdout、D、E。
配置日志输出的目的地
log4j.appender.appenderName = fully.qualified.name.of.appender.class
log4j.appender.appenderName.option1 = value1
…
log4j.appender.appenderName.option = valueN
Log4j 提供的目的地有下面 5 种:
org.apache.log4j.ConsoleAppender:控制台org.apache.log4j.FileAppender:文件org.apache.log4j.DailyRollingFileAppender:每天产生一个文件org.apache.log4j.RollingFileAppender:文件大小超过阈值时产生一个新文件org.apache.log4j.WriterAppender:将日志信息以流格式发送到任意指定的地方
配置日志信息的格式
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
log4j.appender.appenderName.layout.option1 = value1
…
log4j.appender.appenderName.layout.option = valueN
Log4j 提供的格式有下面 4 种:
org.apache.log4j.HTMLLayout:HTML 表格org.apache.log4j.PatternLayout:自定义org.apache.log4j.SimpleLayout:包含日志信息的级别和信息字符串org.apache.log4j.TTCCLayout:包含日志产生的时间、线程、类别等等信息
自定义格式的参数如下所示:
- %m:输出代码中指定的消息
- %p:输出优先级
- %r:输出应用启动到输出该日志信息时花费的毫秒数
- %c:输出所在类的全名
- %t:输出该日志所在的线程名
- %n:输出一个回车换行符
- %d:输出日志的时间点
- %l:输出日志的发生位置,包括类名、线程名、方法名、代码行数,比如:
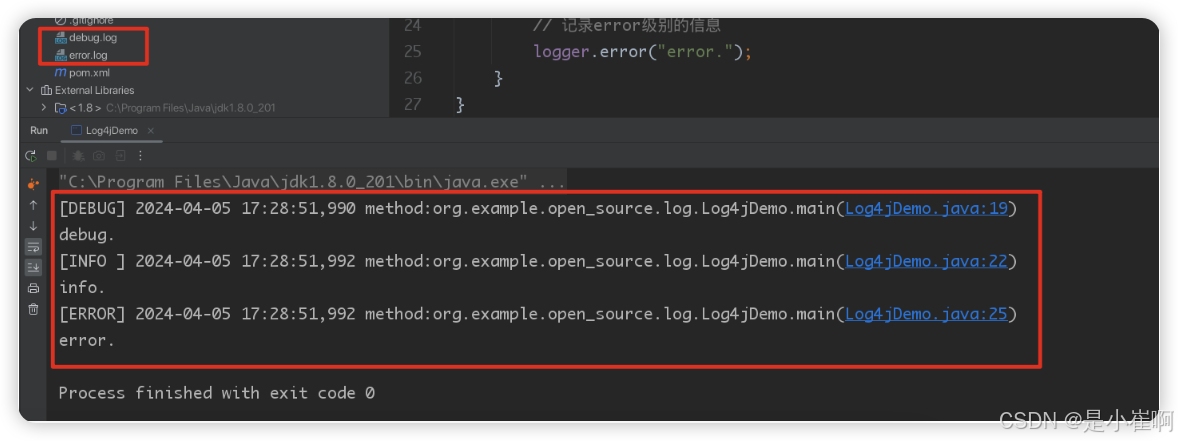
method:com.itwanger.Log4jDemo.main(Log4jDemo.java:14)
package org.example.open_source.log;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
/**
* <p>
* 功能描述:
* </p>
*
* @author cui haida
* @date 2024/04/05/17:27
*/
public class Log4jDemo {
// 获取logger对象
private static final Logger logger = LogManager.getLogger(Log4jDemo.class);
public static void main(String[] args) {
// 记录debug级别的信息
logger.debug("debug.");
// 记录info级别的信息
logger.info("info.");
// 记录error级别的信息
logger.error("error.");
}
}
5:打印日志的8个小技巧
- 在打印 DEBUG 级别的日志时,切记要使用
isDebugEnabled() - 慎重选择日志信息的打印级别,因为这太重要了!如果只能通过日志查看程序发生了什么问题,那必要的信息是必须要打印的,但打印得太多,又会影响到程序的性能。
- 使用 Log4j 而不是
System.out、System.err或者e.printStackTrace()来打印日志 - 使用 log4j.properties 文件来配置日志,尽管它不是必须项,使用该文件会让程序变得更灵活,有一种我的地盘我做主的味道
- 不要忘记在打印日志的时候带上类的全名和线程名,在多线程环境下,这点尤为重要,否则定位问题的时候就太难了。
- 打印日志信息的时候尽量要完整,不要太过于缺省,尤其是在遇到异常或者错误的时候:
- 信息要保留两类:案发现场信息和异常堆栈信息,如果不做处理,通过 throws 关键字往上抛
- 要对日志信息加以区分,把某一类的日志信息在输出的时候加上前缀
- 比如说所有数据库级别的日志里添加
DB_LOG,这样的日志非常大的时候可以通过grep这样的 Linux 命令快速定位
- 比如说所有数据库级别的日志里添加
- 不要在日志文件中打印密码、银行账号等敏感信息。
下面着重解释下第一个:在打印 DEBUG 级别的日志时,切记要使用
isDebugEnabled()
为什么要这样做呢?先来看一下 isDebugEnabled() 方法的源码:
public boolean isDebugEnabled() {
return this.repository.isDisabled(10000) ?
false : Level.DEBUG.isGreaterOrEqual(this.getEffectiveLevel());
}
内部使用了 isDisabled() 方法进行了日志级别的判断,如果 DEBUG 是禁用的话,就 return false 了
再来看一下 debug() 方法的源码:
public void debug(Object message) {
if (!this.repository.isDisabled(10000)) {
if (Level.DEBUG.isGreaterOrEqual(this.getEffectiveLevel())) {
this.forcedLog(FQCN, Level.DEBUG, message, (Throwable)null);
}
}
}
不是也用 isDisabled() 方法判断吗?难道使用 isDebugEnabled()不是画蛇添足吗?直接用 logger.debug() 不香吗?
如果我们在打印日志信息的时候需要附带一个方法去获取参数值,就像下面这样:
logger.debug("用户名是:" + getName());
假如 getName() 方法需要耗费的时间长达 6 秒,那完了!尽管配置文件里的日志级别定义的是 INFO,getName() 方法仍然会倔强地执行 6 秒,完事后再 debug(),这就很崩了!
明明 INFO 的时候 debug() 是不执行的,意味着 getName() 也不需要执行的,偏偏就执行了 6 秒,是不是很傻?
if(logger.isDebugEnabled()) {
logger.debug("用户名是:" + getName());
}
换成上面这种方式,那确定此时 getName() 是不执行的
为了程序性能上的考量,isDebugEnabled() 就变得很有必要了!假如说 debug() 的时候没有传参,确实是不需要判断 DEBUG 是否启用的。
Log4j2:Log4j的升级版本
Log4j、SLF4J、Logback 是一个爹——Ceki Gulcu,但 Log4j 2 却是例外,它是 Apache 基金会的产品。
1:Log4j2 强在哪
- 在多线程场景下,Log4j 2 的吞吐量比 Logback 高出了 10 倍,延迟降低了几个数量级:
- Log4j 2 的异步 Logger 使用的是无锁数据结构,而 Logback 和 Log4j 的异步 Logger 使用的是 ArrayBlockingQueue。
- 对于阻塞队列,多线程应用程序在尝试使日志事件入队时通常会遇到锁争用。
- 性能方面是 Log4j 2 的最大亮点,至于其他方面的一些优势,比如说下面这些,可以忽略不计
- Log4j 2 可以减少垃圾收集器的压力。
- 支持 Lambda 表达式。
- 支持自动重载配置
2:简单使用
这个 artifactId 还是 log4j,没有体现出来 2,而在 version 中体现,多少叫人误以为是 log4j
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.5</version>
</dependency>
然后来一个最简单的测试用例
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Demo {
private static final Logger logger = LogManager.getLogger(Demo.class);
public static void main(String[] args) {
logger.debug("log4j2");
}
}
Log4j 2 竟然没有在控制台打印“ log4j2”,还抱怨我们没有为它指定配置文件。
这对于新手来说,很不友好,因为新手在遇到这种情况的时候,往往不知所措
通过源码,你可以看得到,Log4j 2 会去寻找 4 种类型的配置文件,后缀分别是 properties、yaml、json 和 xml。前缀是 log4j2-test 或者 log4j2。
知道了这个之后,在 resource 目录下增加 log4j2-test.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<!-- 输出到控制台的信息 -->
<Console name="Console" target="SYSTEM_OUT">
<!-- 10:14:04.657 [main] DEBUG com.study.Demo - log4j2 -->
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<!-- 指定 Root 的日志级别,并且指定具体启用哪一个 Appenders。 -->
<Loggers>
<Root level="DEBUG">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
Log4j 2 的配置文件格式和 Logback 有点相似
- 基本的结构为
< Configuration>元素,包含 0 或多个< Appenders>元素 - 其后跟 0 或多个
< Loggers>元素,里面再跟最多只能存在一个的< Root>元素。
配置 appender
也就是配置日志的输出目的地。
有 Console,典型的控制台配置信息,我来简单解释一下里面 pattern 的格式:
%d{HH:mm:ss.SSS}表示输出到毫秒的时间%t输出当前线程名称%-5level输出日志级别,-5 表示左对齐并且固定输出 5 个字符,如果不足在右边补空格%logger输出 logger 名称,最多 36 个字符%msg日志文本%n换行
顺带补充一下其他常用的占位符:
%F输出所在的类文件名,如 Demo.java%L输出行号%M输出所在方法名%l输出语句所在的行数, 包括类名、方法名、文件名、行数%p输出日志级别%c输出包名,如果后面跟有{length.}参数,比如说%c{1.},它将输出报名的第一个字符,如com.itwanger的实际报名将只输出c.i
配置loggers
指定 Root 的日志级别,并且指定具体启用哪一个 Appenders。
自动装载配置
Logback 支持自动重载配置,Log4j 2 也支持,那想要启用这个功能也非常简单,只需要在 Configuration 元素上添加 monitorInterval 属性即可。
<Configuration monitorInterval="30">
...
</Configuration>
注意值要设置成非零,上例中的意思是至少 30 秒后检查配置文件中的更改。最小间隔为 5 秒。
3:Async 示例
除了 Console,还有 Async,可以配合文件的方式来异步写入,典型的配置信息如下所示:
<Configuration>
<Appenders>
<File name="DebugFile" fileName="debug.log">
<PatternLayout>
<Pattern>%d %p %c [%t] %m%n</Pattern>
</PatternLayout>
</File>
<!-- async -->
<Async name="Async">
<AppenderRef ref="DebugFile"/>
</Async>
</Appenders>
<Loggers>
<Root level="debug">
<AppenderRef ref="Async"/>
</Root>
</Loggers>
</Configuration>
4:RollingFile 示例
RollingFile 会根据 Triggering(触发)策略和 Rollover(过渡)策略来进行日志文件滚动。
如果没有配置 Rollover,则使用 DefaultRolloverStrategy 来作为 RollingFile 的默认配置。
触发策略包含有:
- 基于 cron 表达式的 CronTriggeringPolicy;
- 基于文件大小的 SizeBasedTriggeringPolicy;
- 基于时间的 TimeBasedTriggeringPolicy。
过渡策略包含有:
- 默认的过渡策略 DefaultRolloverStrategy
- 直接写入的 DirectWriteRolloverStrategy。
一般情况下,采用默认的过渡策略即可,它已经足够强大。
来看第一个基于 SizeBasedTriggeringPolicy 和 TimeBasedTriggeringPolicy 策略,以及缺省 DefaultRolloverStrategy 策略的配置示例:
<Configuration>
<Appenders>
<RollingFile name="RollingFile" fileName="rolling.log"
filePattern="rolling-%d{yyyy-MM-dd}-%i.log"> <!-- 滚动创建的文件名 -->
<PatternLayout>
<Pattern>%d %p %c{1.} [%t] %m%n</Pattern>
</PatternLayout>
<Policies>
<SizeBasedTriggeringPolicy size="1 KB"/> <!-- 1kb滚动 -->
</Policies>
</RollingFile>
</Appenders>
<Loggers>
<Root level="debug">
<AppenderRef ref="RollingFile"/>
</Root>
</Loggers>
</Configuration>
为了验证文件的滚动策略,我们调整一下 Demo 类,让它多打印点日志:
for (int i = 0; i < 10; i++) {
log.debug("haha_{}", i)
}
再次运行 Demo 类,可以看到根目录下多了 3 个日志文件:

结合日志文件名,再来看 RollingFile 的配置,就很容易理解了。
1)fileName 用来指定文件名。
2)filePattern 用来指定文件名的模式,它取决于过渡策略。
由于配置文件中没有显式指定过渡策略,因此 RollingFile 会启用默认的 DefaultRolloverStrategy。
先来看一下 DefaultRolloverStrategy 的属性:
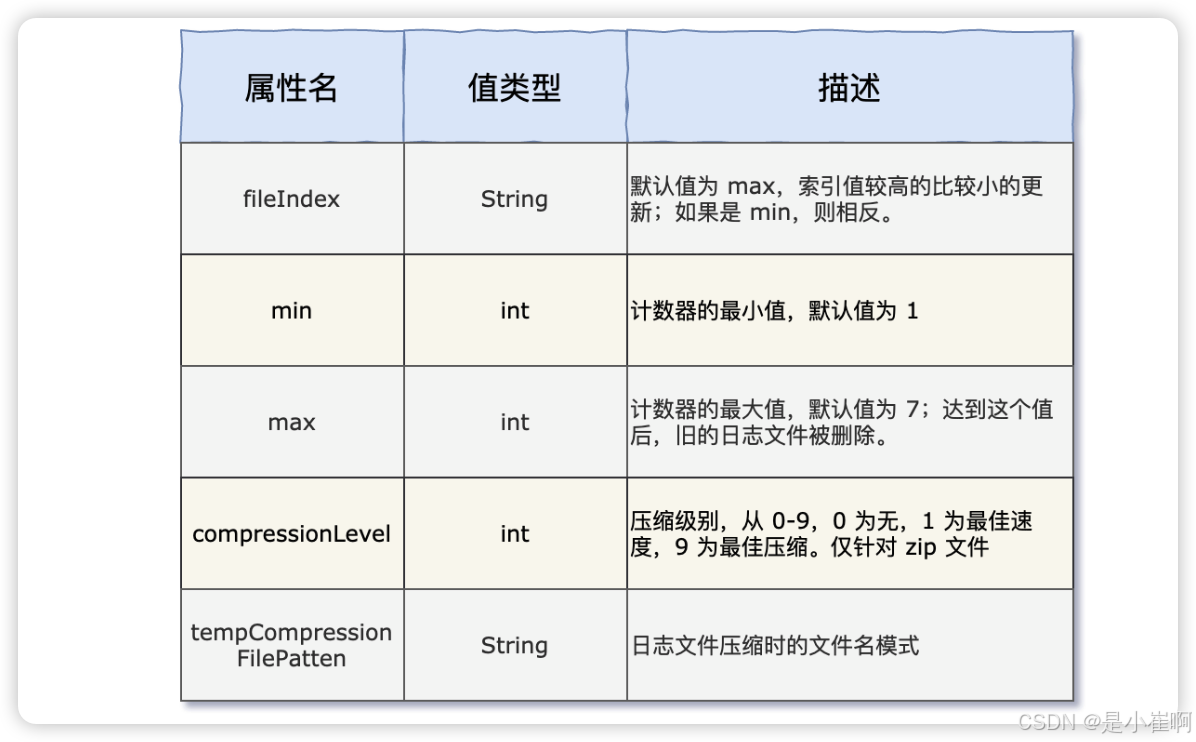
再来看 filePattern 的值 rolling-%d{yyyy-MM-dd}-%i.log,其中 %d{yyyy-MM-dd} 很好理解,就是年月日;其中 %i 是什么意思呢?
第一个日志文件名为 rolling.log(最近的日志放在这个里面),第二个文件名除去日期为 rolling-1.log,第二个文件名除去日期为 rolling-2.log,根据这些信息,你能猜到其中的规律吗?
其实和 DefaultRolloverStrategy 中的 max 属性有关,目前使用的默认值,也就是 7,那就当 rolling-8.log 要生成的时候,删除 rolling-1.log。可以调整 Demo 中的日志输出量来进行验证。
3)SizeBasedTriggeringPolicy,基于日志文件大小的时间策略,大小以字节为单位,后缀可以是 KB,MB 或 GB,例如 20 MB。
再来看一个日志文件压缩的示例,来看配置:
<RollingFile name="RollingFileGZ" fileName="gz/rolling.log"
filePattern="gz/%d{yyyy-MM-dd-HH}-%i.rolling.gz">
<PatternLayout>
<Pattern>%d %p %c{1.} [%t] %m%n</Pattern>
</PatternLayout>
<Policies>
<SizeBasedTriggeringPolicy size="1 KB"/>
</Policies>
</RollingFile>
- fileName 的属性值中包含了一个目录 gz,也就是说日志文件都将放在这个目录下。
- filePattern 的属性值中增加了一个 gz 的后缀,这就表明日志文件要进行压缩了,还可以是 zip 格式。

















 3346
3346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









