



1,hadoop安装
参考:https://blog.youkuaiyun.com/pucao_cug/article/details/71773665
本博主的所有大数据相关都不是原创,都是参考别人的,再这里只是做一笔记;
2,mysql安装
hive需要mysql,自己安装;mysql安装可以参考:
https://blog.youkuaiyun.com/qq_43338182/article/details/85163712
3,hive安装
转自:https://blog.youkuaiyun.com/pucao_cug/article/details/71773665
1.首先就是下载hive;
我的是:apache-hive-2.3.4-bin
在这里下载: http://mirror.bit.edu.cn/apache/hive/
stable :稳定的
2.解压配置环境变量
vim /etc/profile
加上
export HIVE_HOME=/opt/hive/apache-hive-2.3.4-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=:${HIVE_HOME}/bin:$PATH
3,进入hive目录,更改hive环境配置文件
cd /opt/hive/apache-hive-2.3.4-bin/conf
cp hive-env.sh.template hive-env.sh
hive自己的环境变量
vim hive-env.sh
在后面添加
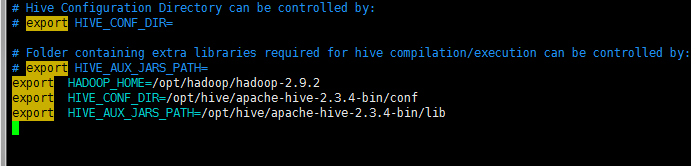
4.更改hive-site.xml
vim hive-site.xml
把文件中所有的 ${system:java.io.tmpdir} 都改成 /opt/hive/tmp
把文件中所有的 ${system:user.name} 都改成 /root
hive-site.xml 文件中有这样的配置:

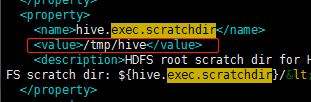
所以你需要在hadoop中创建这两个文件夹
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /tmp/hive/
赋予最高权限
hdfs dfs -chmod 777 /user/hive/warehouse
hdfs dfs -chmod 777 /tmp/hive/
可以使用:hdfs dfs -ls / 来查看是否有文件夹存在;
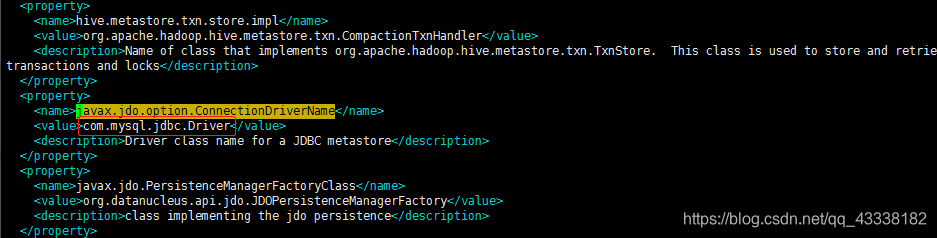
修改这个:写你自己的mysql url
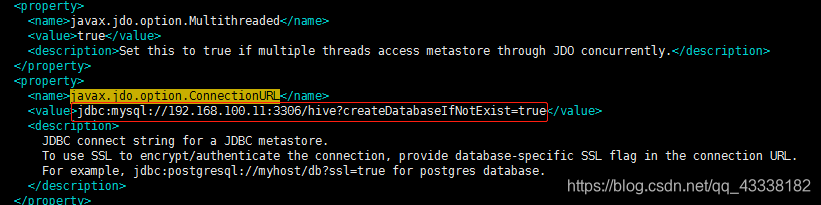
在这里需要注意:url后面如果还想写(characterEncoding=UTF-8)应该
&;useUnicode=true &;characterEncoding=UTF-8
由于编辑器问题,他会自动转译;所以我这里的 “分号” 是中文,用的时候换成英文 “分号”
怕有和我一样的无知少年出错,再截个图

在xml中 & 需要使用 &; 来代替


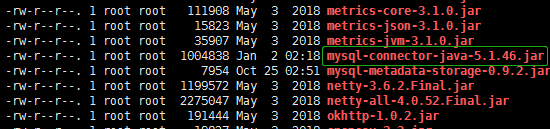
5.在lib目录下加入mysql驱动jar包
4.启动,测试
1,对数据库进行初始化
cd /opt/hive/apache-hive-2.3.4-bin/bin
schematool -initSchema -dbType mysql
出现schematool completed;那就成功了;
在windows连接看看:
2,启动
./hive
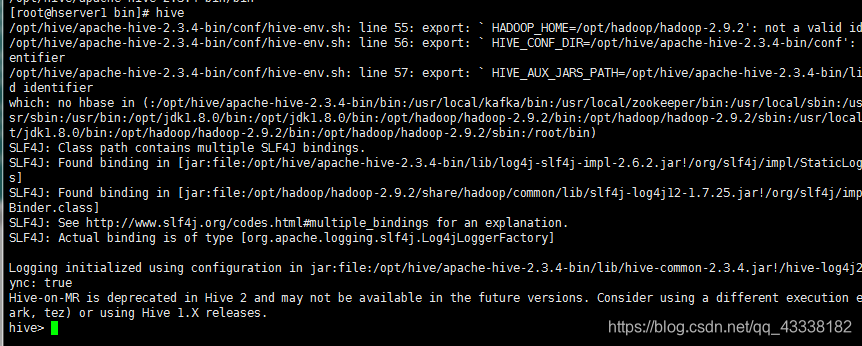
这样就成功了;
show functions;
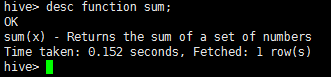
查看sum函数的详细信息的命令:
desc function sum;
3.建表,导入数据
create database db_hive_edu;
use db_hive_edu;
# 创建表,tab 键 来区分字段
create table student(id int,name string) row format delimited fields terminated by '\t';
# 新建文件写入内容:
touch /opt/hive/student.txt
001 zhangsan
002 lisi
003 wangwu
004 zhaoliu
005 chenqi
中间是 Tab 键,自己改一下
load data local inpath '/opt/hive/student.txt' into table db_hive_edu.student;
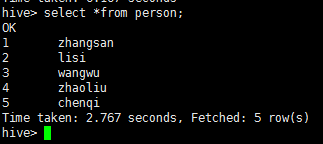
select * from student; 或 select * from db_hive_edu.student;
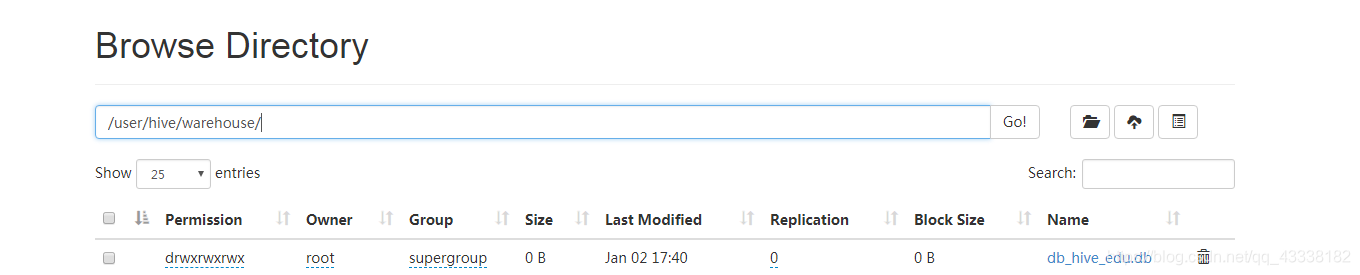
查看hadoop中是否有这个
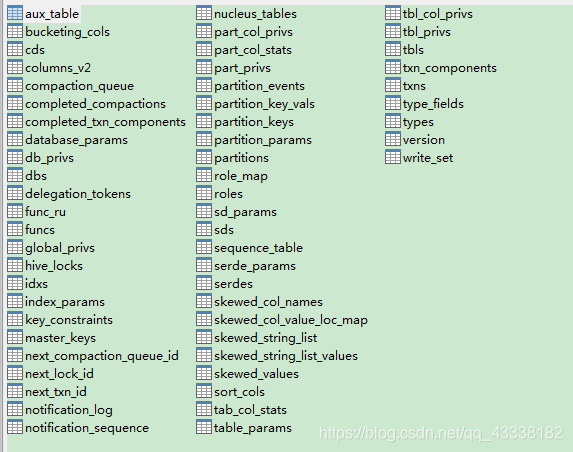
最后,看看数据库:
select * from hive.tbls;


















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









