




 本文深入解析大数据的核心技术,包括Hadoop的分布式存储与计算框架、HBase的列存数据库、MapReduce的分布式计算模型以及Hive的数据仓库解决方案。探讨了Zookeeper在分布式环境下的数据管理作用,介绍了Pig、Sqoop、Flume等数据处理工具的功能。
本文深入解析大数据的核心技术,包括Hadoop的分布式存储与计算框架、HBase的列存数据库、MapReduce的分布式计算模型以及Hive的数据仓库解决方案。探讨了Zookeeper在分布式环境下的数据管理作用,介绍了Pig、Sqoop、Flume等数据处理工具的功能。
什么是大数据? 什么是数据?为何称之为大数据?
二十年前,我们生活在物质极具匮乏的时代,日常的生活没有抖音,没有游戏,更没有QQ,微信,Msn(及时通讯类app)....有人说,二十年前的社会的数据产物是当代的十分之一都不到,可想而知这个世界发展之快..我们现在所拥有的毫无疑问,它都是透明的...
-------微观
大数据的定义:在短时间内产生的极具价值的数据…
大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换而言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。
**谈何数据?**数据可以是文本数据,多媒体数据,图形数据.你的博客,你的成绩,包括你的年龄性别身高都是数据…
数据的单位 最小的基本单位是bit,按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
在这里不得不提到 谷歌的三篇论文
HDFS书籍
http://blog.bizcloudsoft.com/wp-content/uploads/Google-File-System中文版_1.0.pdf
BIg-table书籍
http://blog.bizcloudsoft.com/wp-content/uploads/Google-Bigtable中文版_1.0.pdf
MapReduce书籍
http://blog.bizcloudsoft.com/wp-content/uploads/Google-MapReduce中文版_1.0.pdf
从而标志的数据时代的到来…
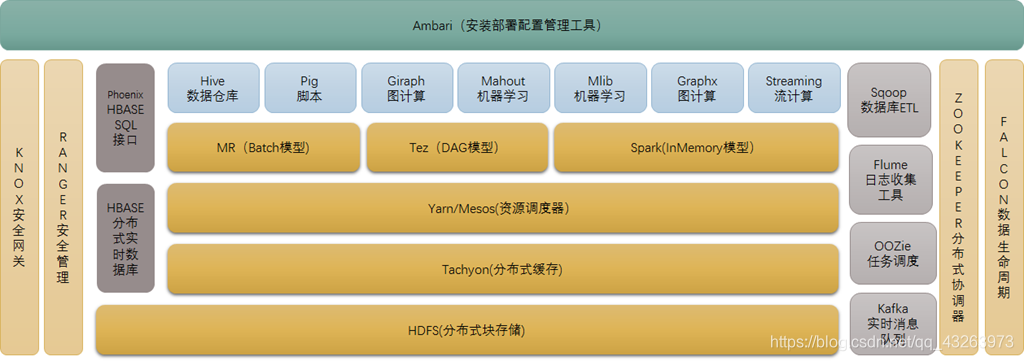
HADOOP生态圈介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
具有可靠、高效、可伸缩的特点。
Hadoop的核心是YARN,HDFS和Mapreduce
下图是hadoop生态系统,集成spark生态圈。在未来一段时间内,hadoop将于spark共存,hadoop与spark
都能部署在yarn、mesos的资源管理系统之上
 (侵删- - *)
(侵删- - *)
2 HDFS
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。
HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
HDFS 漫解: 如果我有一个特别大的文件 我需要发放下去?那么我该如何去接受它?分派任务的场景......
设定角色 老板 秘书 员工 Namenode 老板
- 1.管理文件的权限
1.1 管理DN的数据
1.2 元数据:描述数据的数据
1.3 源数据:数据(直接存放的数据)
2.接受秘书的请求(完成文件的读写操作)
3.与DN之间进行相应的通信 - 2 DataNode 员工
1.存储数据
2.描述自己
3.接受请求
(糙图呈现)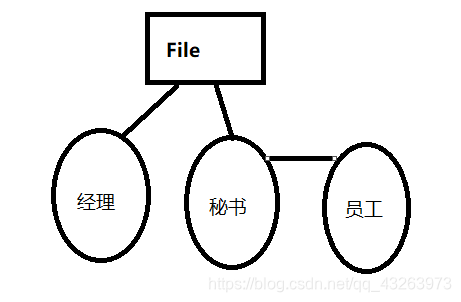
读与写
场景模拟:有一个文件需要分发给员工…
一、写
1 大文件
2 client会将大文件进行切块 (固定值 128M 256M)
切块的公式: 文件的大小/128M(固定)=block/块数
3 向NN(老板)发起请求
3.1 块数
3.2 文件的大小
3.3 文件的权限(秘书角色是没有权限的)
3.4 文件的属主(秘书进行分配的文件块是分配给谁的)
3.5 给定文件上传的时间
重复动作
- 4 client切下一块 128M --相当于秘书手上已经有了一份任务需要找人来完成它
5 client会去向NN申请资源----秘书:我手上有任务我需要人来完成它 需要向NN获取员工的数据 完成资源的调度
6 NN会返回一些负载不高的DN给client -------请求得到相应 允许资源的放行
7client会向DN里面发送block并且做好备份-------文件发放给员工的同时,防止意外的发生做好相应文件的备份
8 DN存放block块之后向NN汇报情况 -----分门别类我具体存放的是什么样类型的文件
二、读
场景模拟:领导想要去看某一个文件…
1 NN会向client发送一个请求,client接受到请求之后,会去向NN申请节点信息(blockid----每一块文件上都有一个对应的id(对应下文不可混))
1.1领导想要去查看某一个员工身上的文件
1.2告诉秘书我要查看谁谁谁的信息
1.3秘书知道后我就会去想老板获取这个得知员工信息的权限
2.NN会向client发送一些节点(DN)信息
2.1 已经获取到员工(DN)的信息
2.2汇报老板
3.client获取到节点信息之后DN上获取数据(就近原则-----获取离NN最近的一个节点)
3.1老板的得知到秘书反馈的信息
3.2老板找到最近员工查看具体信息
Block
文件线性切割成块(block) 在同一个文件的block大小要保持一致
如果不在同一个文件那么文件的block块大小是可以不一致的。
版本:
1.x版本 64M
2.x版本128M
外延:如果我说我上传文件,每个block块以128M划分,假设我剩余10M怎么办? 如果下一个文件上传的时候也有剩余我可以混合在一起吗?
1.1 首先想象去倒入饮料,假设我已经装满了五杯,那么我此刻剩余一点,这个时候我也要拿出一个空杯子进行饮料的倒入
2.2 如果我的下一个文件上传的时候也有剩余是不能和上一个被子放在一起的
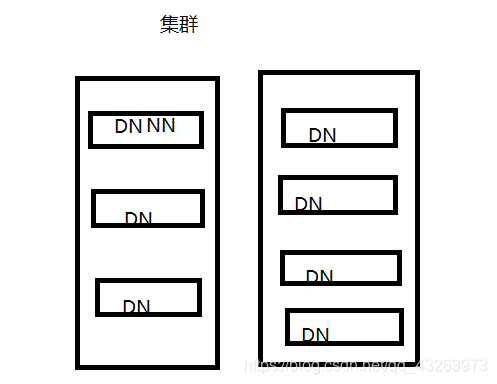
1.集群内提交
1.1 如下
主节点直接提交给DN节点
-
2. Block可以设置副本数,副本数分散在不同的节点 副本数不要超过节点数量
2.1 我在分发文件block的同时我可以进行文件的拷贝。
2.1.1 从安全性考虑我可以去拷贝文件的多份,避免服务器停电的情况和文件的丢失,避免意外!
2.1.2 如果我只有两个节点那么有必要拷贝三个文件吗?这是肯定不用的,我只有两个节点他两个一人一个就可以了。2.集群外提交
-
1.选择一个负载不高的节点进行存放
2.放置在与第一个备份不同机架的任意节点上 为何放置在与第一个备份不同机架的任意节点上?首先如果放在跟主节点的同一个机架上那么如果出现停电的原因?会导致数据的丢失,备份的数据也会丢失这个时候我们可以选在与第一个机架不同的节点上。 3.放置在第二个机架的不同节点上
piepeline管道
一次写入多次读写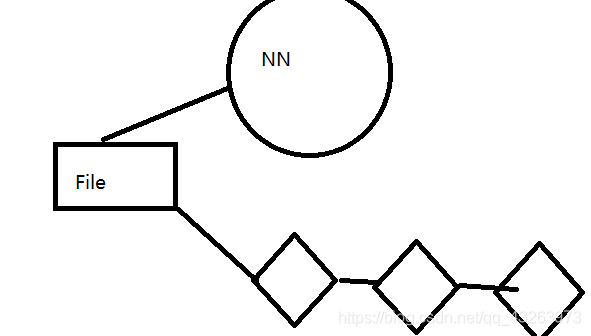
-
- NN在返回给client一些DN的信息后会形成一个管道
2 . 之前的block文件怎么传输?他们会把block切割成为一个个的ackPackage,每个大概64k左右,如同管道流水一样。之前面对的是一个个块状的文件,进入管道传输时比较费时费力的。
3. DN会从管道拿去相应的数据进行存储
4. 存储完成后,DN会向NN进行汇报
- NN在返回给client一些DN的信息后会形成一个管道
3、Mapreduce(分布式计算框架)
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种分布式计算模型,用以进行大数据量的计算。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分,
其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
- HBASE(分布式列存数据库)
源自Google的Bigtable论文,发表于2006年11月,HBase是Google Bigtable克隆版
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
- Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
- HIVE(数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
7.Pig(ad-hoc脚本)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具
Pig定义了一种数据流语言—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
其编译器将Pig Latin翻译成MapReduce程序序列将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
8.Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
9.Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。当然也可以用于收集其他类型数据

参考文献: Hadoop生态系统介绍 http://blog.youkuaiyun.com/qa962839575/article/details/44256769?ref=myread

















 5318
5318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









