






 本文通过生成具有不同均值和协方差的高斯分布数据点,演示了如何使用K-Means聚类算法进行数据聚类。首先,我们生成了三组数据点,分别围绕(0,0),(10,10)和(10,0)的中心分布。然后,使用K-Means++初始化策略和K-Means算法对这些数据点进行了聚类,并展示了聚类结果。
本文通过生成具有不同均值和协方差的高斯分布数据点,演示了如何使用K-Means聚类算法进行数据聚类。首先,我们生成了三组数据点,分别围绕(0,0),(10,10)和(10,0)的中心分布。然后,使用K-Means++初始化策略和K-Means算法对这些数据点进行了聚类,并展示了聚类结果。
版权声明:本文为转载文章
原文链接:https://blog.youkuaiyun.com/itnerd/article/details/83420139
首先生成原始数据点:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
def gen_clusters():
mean1 = [0,0]
cov1 = [[1,0],[0,10]]
data = np.random.multivariate_normal(mean1,cov1,100)
mean2 = [10,10]
cov2 = [[10,0],[0,1]]
data = np.append(data,
np.random.multivariate_normal(mean2,cov2,100),
0)
mean3 = [10,0]
cov3 = [[3,0],[0,4]]
data = np.append(data,
np.random.multivariate_normal(mean3,cov3,100),
0)
return np.round(data,4)
def show_scatter(data,colors):
x,y = data.T
plt.scatter(x,y,c=colors)
plt.axis()
plt.title(“scatter”)
plt.xlabel(“x”)
plt.ylabel(“y”)
plt.show()
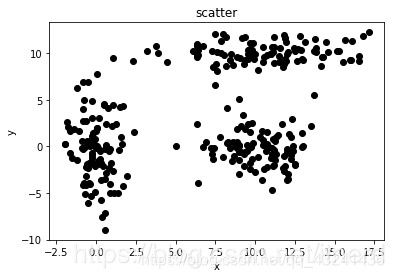
data = gen_clusters()
show_scatter(data,‘k’)
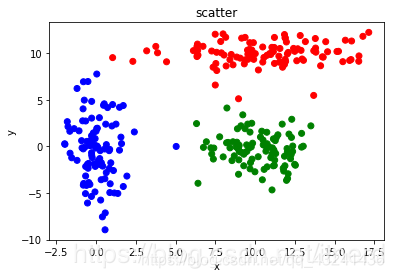
使用 K-Means 方法聚类:
// 初始化参数为 k-means++
estimator = KMeans(init=‘k-means++’, n_clusters=3, n_init=3)
estimator.fit(data)
label2color = [‘r’,‘g’,‘b’]
colors = [label2color[i] for i in estimator.labels_]
show_scatter(data,colors)
初始化参数为 k-means++
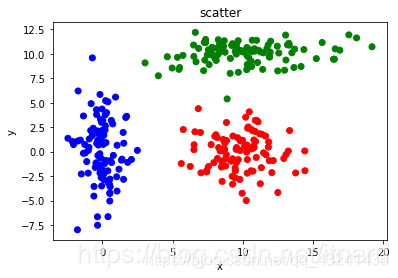
初始化参数为 random
聚类中心:
centroids = estimator.cluster_centers_
print(centroids)
#高斯中心
[[ 9.8040697 -0.01635758] ==>(10,0)
[ 10.16384455 10.03000693] ==>(10,10)
[ -0.038093 0.13642 ]] ==>(0,0)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









