






软考程序语言设计板块知识点总结与习题
一、引言
在软考中,程序语言设计板块占据着重要的地位。无论是对于计算机专业的学生,还是想要在 IT 领域进一步提升自己能力的从业者,掌握好程序语言设计的相关知识,都是顺利通过软考的关键。本文将对软考中程序语言设计板块的知识点进行详细总结,并提供一些典型的习题,帮助大家更好地备考。
二、程序语言基础概念
(一)程序语言的分类
-
机器语言:计算机能够直接识别和执行的二进制代码语言,执行效率高,但编写和阅读难度极大。例如早期计算机直接使用的由 0 和 1 组成的指令序列。
-
汇编语言:使用助记符来表示机器指令,比机器语言易于理解和编写,但仍然依赖于特定的硬件平台。像用 ADD 表示加法运算等。
-
高级语言:与人类自然语言和数学表达式更接近,具有较高的抽象性和可移植性。如 C、C++、Java、Python 等。
(二)程序语言的基本成分
-
数据成分:用于描述程序所处理的数据对象。包括常量(如整数常量 1、字符串常量 “hello” 等)、变量(在程序执行过程中其值可以改变,如在 C 语言中 int num; 定义了一个整型变量 num)、数组(如 int arr [10]; 定义了一个包含 10 个元素的整型数组)、结构体(在 C 语言中,struct Student {int id; char name [20];}; 定义了一个学生结构体类型)等。
-
运算成分:规定了如何对数据进行运算。常见的运算有算术运算(如 +、-、*、/)、逻辑运算(如 &&、||、!)、关系运算(如 >、<、== )等。例如在 C 语言中,int a = 5, b = 3; int result = a + b; 这里进行了加法算术运算。
-
控制成分:用于控制程序的执行流程。主要有顺序结构(按照语句的先后顺序依次执行)、选择结构(如 if - else 语句,在 C 语言中 if (a> b) {printf (“a is greater”);} else {printf (“b is greater”);} )、循环结构(如 for 循环,for (int i = 0; i < 10; i++) { // 循环体 } )。
-
传输成分:负责数据的输入和输出。在 C 语言中,使用 scanf 和 printf 函数进行输入输出操作,如 scanf (“% d”, &num); printf (“The value of num is: % d”, num); 。
三、语法结构
(一)词法分析
-
词法单元:是程序中具有独立意义的最小语法单位。如标识符(由字母、数字、下划线组成,且不能以数字开头,如变量名 myVar )、关键字(如 C 语言中的 int、if、while 等,具有特定的含义和用途)、运算符(如 +、-、* 等)、界符(如逗号,、分号;等)。
-
词法分析器:它的作用是将源程序的字符流按照词法规则识别为一个个词法单元。例如对于源程序 “int num = 5;”,词法分析器会将其识别为 “int”(关键字)、“num”(标识符)、“=”(运算符)、“5”(常量)、“;”(界符)。
(二)语法分析
-
语法规则:定义了如何将词法单元组合成合法的语法结构。例如在 C 语言中,一个合法的赋值语句语法规则是 “变量 = 表达式;” 。
-
语法分析器:根据语法规则对词法单元序列进行分析,构建出对应的语法树。例如对于语句 “int a = 3 + 2;” ,语法分析器会构建出一棵表示该语句结构的语法树,树根可能是赋值操作,左子树是变量 “a”,右子树是加法表达式 “3 + 2”。
四、数据类型
(一)基本数据类型
-
整型:不同的编程语言中整型的表示范围和占用字节数有所不同。例如在 C 语言中,有 short int(通常占用 2 个字节)、int(通常占用 4 个字节)、long int(通常占用 4 或 8 个字节) ,它们用于表示整数数值。
-
浮点型:包括单精度浮点型(如 C 语言中的 float,通常占用 4 个字节)和双精度浮点型(如 C 语言中的 double,通常占用 8 个字节),用于表示带小数部分的数值。由于浮点型在计算机中采用二进制近似表示,所以在进行浮点数运算时可能会存在精度问题,如 0.1 + 0.2 在计算机中计算的结果可能并不精确等于 0.3。
-
字符型:用于表示单个字符,在 C 语言中用 char 类型表示,占用 1 个字节,每个字符都有对应的 ASCII 码值,如字符 ‘A’ 的 ASCII 码值为 65。
(二)构造数据类型
-
数组:是一组相同类型数据元素的集合。数组的下标从 0 开始,例如在 C 语言中,int arr [5] = {1, 2, 3, 4, 5}; 定义了一个包含 5 个元素的整型数组,访问数组元素时可以使用 arr [0] (值为 1)、arr [1] (值为 2)等。
-
结构体:是用户自定义的数据类型,它可以将不同类型的数据组合在一起。如前面提到的学生结构体,struct Student {int id; char name [20];}; 可以通过定义结构体变量来使用,如 struct Student stu1; stu1.id = 1; strcpy (stu1.name, “Tom”); 。
-
联合体:也是用户自定义的数据类型,联合体中的所有成员共享同一块内存空间,其大小取决于最大成员的大小。例如在 C 语言中,union Data {int num; char ch; float f;}; union Data data1; 这里 data1 的大小取决于 float 类型的大小(通常 4 个字节)。
五、运算符与表达式
(一)运算符的优先级与结合性
-
优先级:不同运算符具有不同的优先级,优先级高的运算符先进行运算。例如在表达式 “3 + 4 * 2” 中,乘法运算符 “*” 的优先级高于加法运算符 “+”,所以先计算 4 * 2,结果为 8,再计算 3 + 8,最终结果为 11。
-
结合性:当一个表达式中有多个优先级相同的运算符时,结合性决定了运算的顺序。例如在表达式 “10 - 5 - 3” 中,减法运算符 “-” 是左结合性,所以先计算 10 - 5,结果为 5,再计算 5 - 3,最终结果为 2。
(二)常见表达式
-
算术表达式:由算术运算符和操作数组成,如 “(3 + 5) * 2 - 1” 。
-
逻辑表达式:由逻辑运算符和关系表达式组成,用于判断条件的真假,如 “(a> 5) && (b < 10)” 。
-
关系表达式:由关系运算符连接两个操作数组成,结果为真或假,如 “a == 3” 。
六、函数与过程
(一)函数的定义与调用
-
定义:在 C 语言中,函数定义的一般形式为 “返回值类型 函数名 (参数列表) { 函数体;}” 。例如 “int add (int a, int b) { return a + b; }” 定义了一个名为 add 的函数,它接受两个整型参数,返回两个参数的和。
-
调用:通过函数名和实际参数来调用函数,如 “int result = add (3, 5);” 调用了 add 函数,并将返回值赋给变量 result。
(二)函数参数传递
-
值传递:将实际参数的值复制一份传递给函数的形式参数,在函数内部对形式参数的修改不会影响实际参数。例如在 C 语言中,void func (int num) { num = num + 1; } int a = 5; func (a); 这里调用 func 函数后,变量 a 的值仍然是 5。
-
引用传递:在 C++ 等语言中支持引用传递,将实际参数的引用传递给函数的形式参数,在函数内部对形式参数的修改会影响实际参数。例如在 C++ 中,void func (int& num) { num = num + 1; } int a = 5; func (a); 调用 func 函数后,变量 a 的值变为 6。
(三)递归函数
- 概念:递归函数是指在函数的定义中调用自身的函数。例如计算阶乘的递归函数:
int factorial(int n) {
if (n == 0 || n == 1) {
return 1;
} else {
return n * factorial(n - 1);
}
}
- 递归的终止条件:为了避免无限递归,递归函数必须有一个终止条件。在上述阶乘函数中,n == 0 || n == 1 就是递归的终止条件。
七 n == 0 || n == 1 就是递归的终止条件。
七、习题与解析
(一)选择题
- 以下属于高级程序语言的是( )
A. 机器语言 B. 汇编语言 C. Python D. 以上都不是
答案:C
解析:机器语言和汇编语言不属于高级语言,Python 是高级语言,所以选 C。
- 在 C 语言中,定义一个包含 10 个元素的整型数组,正确的是( )
A. int arr {10}; B. int arr [10]; C. int arr (10); D. int arr = 10;
答案:B
解析:在 C 语言中,定义数组的正确形式是类型 数组名 [元素个数],所以选 B。
- 以下表达式中,运算结果为真的是( )
A. 3 > 5 && 2 <4 B. 5 == 3 || 4> 2 C.!(3 < 5) D. 2 + 3 == 4
答案:B
解析:A 选项中 3 > 5 为假,逻辑与运算只要有一个为假则结果为假;B 选项中 5 == 3 为假,但 4 > 2 为真,逻辑或运算只要有一个为真则结果为真;C 选项中 3 < 5 为真,取反后为假;D 选项中 2 + 3 = 5 不等于 4,结果为假。所以选 B。
(二)编程题
- 编写一个 C 语言函数,计算两个整数的乘积。
int multiply(int a, int b) {
return a * b;
}
- 编写一个 Python 函数,判断一个数是否为偶数。
def is_even(num):
return num % 2 == 0
文章目录
一、 程序设计语
1. 程序设计语言的基本概念
(1)低级语言和高级语言
计算机硬件只能识别由
组成的机器指令序列,即机器指令程序,因此机器指令是最基本的计算机语言。缺点:用机器语言进行程序设计时效率很低,程序的可读性很差,也难以修改和维护。
低级语言:机器语言和汇编语言【汇编指令【用符号表示的指令】的集合】。
高级语言:功能更强、抽象级别更高的语言以支持程序设计,面向各类应用的程序设计语言,与人类使用的自然语言比较接近。常见的有:Java、C、C++、PHP、Python、Delphi、PASCAL等,提高了程序设计的效率。
(2)编译程序和解释程序
语言之间的翻译形式有多种,基本方式为汇编、解释和编译。用某种高级语言或汇编语言编写的程序称为源程序,源程序不能直接在计算机上执行。
解释程序(解释器):将高级语言翻译成计算机硬件认可的机器语言加以执行,它或者直接解释执行源程序,或者将源程序翻译成某种中间代码后再加以执行,翻译源程序时不生成独立的目标程序,可以逐条解释执行,用于调试模式,可以控制源程序,因为还需要控制程序,因此执行速度慢,效率低。
编译程序(编译器):将高级语言翻译成计算机硬件认可的机器语言加以执行,翻译成目标语言程序,生成独立的可执行文件,直接运行,运行时无法控制源程序,效率高。
(3)程序设计语言的定义
语法:程序设计语言的语法可用形式语言进行描述。
语义:程序设计语言中按语法规则构成的各个语法成分的含义,可分为静态语义和动态语
义。
语用:表示了构成语言的各个记号和使用者的关系,涉及符号的来源、使用和影响。
语言的实现则有语境【理解和实现程序设计语言的环境,包括编译环境和运行环境】问题。
(4)程序设计语言的分类
若一种程序设计语言不依赖于机器硬件,则称为高级语言;若程序设计语言能够应用于范围广泛的问题求解过程中,则称为通用的程序设计语言。
① 程序设计语言发展概述
- Fortran(Formula Translation):第一个被广泛用来进行科学和工程计算的高级语言,
科学计算,执行效率高。 - ALGOL(ALGOrithmic Language):诞生于晶体管计算机流行的年代,是程序设计语言发展史上的一个里程碑,为后来软件自动化及软件可靠性的发展奠定了基础。
- PASCAL:一种过程式、结构化程序设计语言,
为教学而开发的,表达能力强。 - C语言:一种通用程序设计语言,在系统级应用和实时处理应用开发中成为主要语言。
指针操作能力强,高效。 - C++:在C语言的基础上发展起来的,与C兼容,但是比C多了封装和抽象,增加的类机制使C++成为一种
面向对象的程序设计语言,高效。 - C#(CSharp):由Microsoft公司所开发的一种
面向对象的、运行于.NET Framework的高级程序设计语言,相对于C++,这个语言在许多方面进行了限制和增强,高效。 - Objective-C:C语言所衍生出来的语言,继承了C语言的特性,是扩充C的面向对象编程语言,其与流行的编程语言风格差异较大。
- LISP:一种通用高级计算机程序语言,作为应用
人工智能而设计的语言,是第一个声明式系内函数式程序设计语言,采用抽象数据列表与递归作符号演算来衍生人工智能。 - Java:初始用途是开发网络浏览器的小应用程序,但是作为一种通用的程序设计语言,Java得到非常广泛的应用。
面向对象,中间代码,跨平台。 - Ruby(Yukihiro Matsumoto,常称为Matz):一种解释性、面向对象、动态类型的脚本语言。
- PHP(Hypertext Preprocessor):一种在服务器端执行的、嵌入HTML文档的脚本语言,其语言风格类似于C语言,由网站编程人员广泛运用。
- Python:一种面向对象的解释型程序设计语言,可以用于编写独立程序、快速脚本和复杂应用的原型,也是一种脚本语言,
- JavaScript是一种脚本语言,被广泛用于Web应用开发,常用来为网页添加各式各样的动态功能,为用户提供更流畅美观的浏览效果。
- Delphi:一种可视化开发工具,基于窗体和面向对象的方法、高速的编译器、强大的数据库支持。
- Visual Basic.NET:基于微软.NET Framework的面向对象的编程语言。
- Prolog(Programming in logic):一种面向演绎推理的
逻辑型程序设计语言,语法结构简单,但描述能力很强。
② 程序设计语言分类
- 命令式和结构化程序设计语言:基于动作的语言,在这种语言中,计算被看成是动作的序列。通常所称的结构化程序设计语言属于命令式语言类,结构化程序的结构简单清晰、模块化强,描述方式接近人们习惯的推理式思维方式,因此可读性强,在软件重用性、软件维护等方面都有所进步,在大型软件开发中曾发挥过重要的作用。
- 面向对象的程序设计语言
- 函数式程序设计语言:一类以
2. 程序设计语言的基本成
(1)程序设计语言的数据成分
指一种程序设计语言的数据类型。
- 常量和变量
- 全局量和局部量
- 数据类型:按照数据组织形式的不同可将数据分为基本类型、用户定义类型、构造类型及其他类型
(2)程序设计语言的运算成分
- 数据成分:指一种程序设计语言数据和数据类型,数据分为常量【程序运行时不可改变】,变量【程序运行可以改变】,全局变量【存储空间在静态数据区分配】,局部变量【存储空间在堆栈区分配】,数据类型【整型,字符型,双精度浮点型,单精度浮点型,布尔型等】。
- 运算成分:指明允许使用的运算符号及运算规则。包括算术运算,逻辑运算,关系运算,位运算等。
- 控制成分:指明语言允许表述的控制结构。包括顺序结构,选择结构,循环结构,
- 传输成分:指明语言允许的数据传输方式。如赋值处理,数据的输入输出等。
(3)程序设计语言的控制成分
- 顺序结构
- 选择结构
- 循环结构
- C(C++)语言提供的控制语句:复合语句、if语句和switch语句、循环语句
(4)序设计语言的传输成分
指明语言允许的数据传输方式,如赋值处理、数据的输入和输出等。
(5)函数
函数是程序模块的主要成分,它是一段具有独立功能的程序。
- 函数定义:函数首部和函数体,函数的定义描述了函数做什么和怎么做。
- 函数声明:函数应该先声明后引用。
- 函数调用:当在一个函数(称为调用函数)中需要使用另一个函数(称为被调用函数)实现的功能时,便以名字进行调用。
二、 语言处理程序基础
一类系统软件的总称,主要作用是将高级语言或汇编语言编写的程序翻译成某种机器语言程序,使程序可在计算机上运行。
1. 汇编程序基本原理
(1)汇编语言
为特定的计算机设计的面向机器的符号化的程序设计语言。用汇编语言编写的程序称为汇编语言源程序。
- 指令语句:又称为机器指令语句,分为:传送指令、算术运算指令、逻辑运算指令、移位指令、转移指令和处理机控制指令等类型。
- 伪指令语句:指示汇编程序在汇编源程序时完成某些工作,伪指令语句与指令语句的区别是:伪指令语句经汇编后不产生机器代码,而指令语句经汇编后要产生相应的机器代码;伪指令语句所指示的操作是在源程序被汇编时完成的,而指令语句的操作必须在程序运行时完成。
- 宏指令语句:允许用户将多次重复使用的程序段定义为宏。宏的定义必须按照相应的规定进行,每个宏都有相应的宏名,宏指令语句就是宏的引用。
(2)汇编程序
功能是将用汇编语言编写的源程序翻译成机器指令程序。汇编程序的基本工作包括将每一条可执行汇编语句转换成对应的机器指令,处理源程序中出现的伪指令。由于汇编指令中形成操作数地址的部分可能出现后面才会定义的符号,所以汇编程序一般需要两次扫描源程序才能完成翻译过程。
2. 编译程序基本原理
(1)编译过程概述
编译程序的功能是把某高级语言书写的源程序翻译成与之等价的目标程序(汇编语言或机
器语言)。编译程序的工作过程可以分为6 源程序 个阶段,在实际的编译器词法分析中可能会将其中的某些阶段结合在一起进行处理。
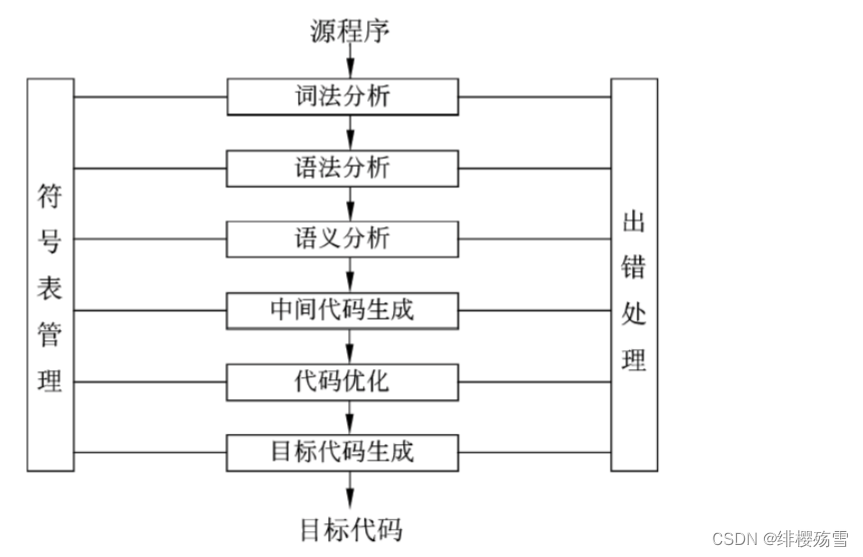
- 词法分析:任务是对源程序从前到后(从左到右)逐个字符地扫描,从中识别出一个个“单词”符号【程序设计语言的基本语法单位】。词法分析程序输出的“单词”常以二元组的方式输出,即单词种别和单词自身的值。词法分析过程依据的是语言的词法规则,即描述“单词”结构的规则。
- 语法分析:任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位,语法规则就是各类语法单位的构成规则。
- 语义分析:任务是分析各语法结构的含义,检查源程序是否包含静态语义错误,并收集类型信息供后面的代码生成阶段使用。只有语法和语义都正确的源程序才能翻译成正确的目标代码。语义分析的一个主要工作是进行类型分析和检查。
- 中间代码生成:工作是根据语义分析的输出生成中间代码。“中间代码”是一种简单且含义明确的记号系统,可以有若干种形式,它们的共同特征是与具体的机器无关。
- 代码优化:优化过程可以在中间代码生成阶段进行,也可以在目标代码生成阶段进行。
- 目标代码生成:是编译器工作的最后一个阶段。这一阶段的任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码,这个阶段的工作与具体的机器密切相关。
- 符号表管理:作用是记录源程序中各个符号的必要信息,以辅助语义的正确性检查和代码生成,在编译过程中需要对符号表进行快速有效地查找、插入、修改和删除等操作。符号表的建立可以始于词法分析阶段,也可以放到语法分析和语义分析阶段,但符号表的使用有时会延续到目标代码的运行阶段。
- 出错处理:动态错误也称动态语义错误,它们发生在程序运行时;静态错误是指编译阶段发现的程序错误,可分为语法错误和静态语义错误。
(2)文法和语言的形式描述
- 字母表、字符串、字符串集合及运算

- 文法和语言的形式描述:法的定义【描述语言语法结构的规则称为文法】;文法的分类【
- 正规表达式和正规集

- 有限自动机:确定的有限自动机(Deterministic Finite Automata,DFA)
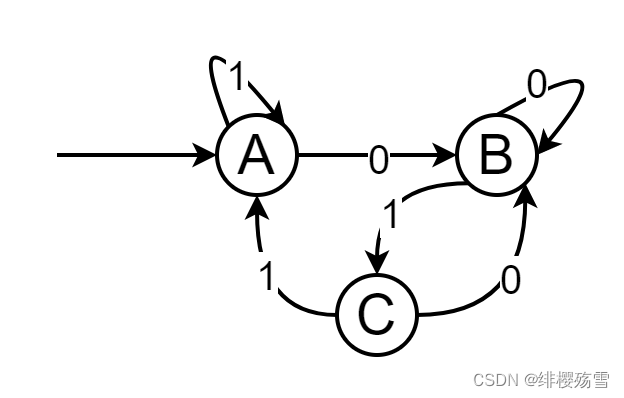
下图所示为一个有限自动机(A是初态、C是终态),该自动机所识别的字符串的特点是:C
A. 必须以 11 结尾的 0、1 串 B. 必须以 00 结尾的 0、1 串
C. 必须以 01 结尾的 0、1 串 D. 必须以 10 结尾的 0、1 串
有限自动机识别的是从初态到终态的字符串,也即从 A 到 C 的字符串,题目中考察以什么字符串结尾,因此只需要查看终态的输入即可,C 只能输入 1,因此最后一个字符必然是 1,在此基础上,反推到 B,只能输入 0,因此倒数第二个必然为 0,可知以 01 结尾的 0、1 串。
- 不确定的有限自动机(Nondeterministic Finite Automata,NFA)
- DFA到DFA的转换
(4)正规式与有限自动机之间的转换
- 有限自动机转换为正规式
- 正规式转换为有限自动机
(5)词法分析器的构造
词法分析器的一般步骤:
- 用正规式描述语言中的单词构成规则。
- 为每个正规式构造一个NFA,它识别正规式所表示的正规集。
- 将构造出的NFA转换成等价的DFA。
- 对DFA进行最小化处理,使其最简。
- 从DFA构造词法分析器。
(6)语法分析
任务是根据语言的语法规则分析单词串是否构成短语和句子,同时检查和处理程序中的语法错误。
- 上下文无关文法:属于乔姆斯基定义的
被广泛地用于表示各种程序设计语言的语
法规则,程序设计语言的绝大多数语法规则可以采用上下文无关文法进行描述。
- 顶向下语法分析方法:基本思想是对于给定的输入串,从文法的开始符号S出发进行最左推导,直到得到一个合法的句子或者发现一个非法结构。在推导的过程中试图用一切可能的方法,自上而下、从左到右地为输入串建立语法树。整个分析过程是一个试探的过程,是反复使用不同产生式谋求与输入序列匹配的过程。若输入串是给定文法的句子,则必能成功,反之必然出错。
- 自底向上语法分析方法:也称移进-归约分析法,其基本思想是对输入序列w自左向右进行扫描,并将输入符号逐个移进一个栈中,边移进边分析,一旦栈顶符号串形成某个句型的可归约串,就重复这一过程,直至栈中只剩下文法的开始符号且输入串也被扫描完时为止,确认输入串 是文法的句子,表明分析成功;否则,进行出错处理。
-
(7)语法制导翻译和中间代码生成
- 中间代码:将源程序首先翻译成中间代码表示形式,以利于进行与机器无关的优化处理。使用中间代码也有助于提高编译程序的可移植性。常用的中间代码有后缀式、三元式、四元式和树等形式。
- 常见语法结构的翻译:常见的语法结构主要有算术表达式、布尔表达式、赋值语句和控制语句(if、while)等。不同结构需要不同的处理方法,但翻译程序的构造原理是相似的。
- 动态存储分配和过程调用的翻译:是程序中一种常见的语言结构,绝大多数语言都含有这方面的内容。过程说明和调用语句的翻译有赖于形参与实参的结合方式以及数据空间的分配方式。
(8)中间代码优化和目标代码生成
优化:对程序进行等价变换,使得从变换后的程序能生成更有效的目标代码。
等价:指不改变程序的运行结果;
有效:指目标代码的运行时间较短,占用的存储空间较少。
优化可在编译的各个阶段进行。最主要的优化是在目标代码生成以前对中间代码进行的,这类优化不依赖于具体的计算机。目标代码的生成由代码生成器实现。代码生成器以经过语义分析或优化后的中间代码为输入,以特定的机器语言或汇编代码为输出。- 中间代码形式:有多种形式,其中树与后缀表示形式适用于解释器,而编译器多采用与机器指令格式较接近的四元式形式。
- 目标代码形式:分为【汇编语言形式】和【机器指令形式】。
- 寄存器的分配。访问寄存器的速度远远快于访问内存单元的速度,单寄存器的个数是有限的。因此,如何分配及使用寄存器是目标代码生成时需要着重考虑的。
- 计算次序的选择:代码执行的效率会随计算次序的不同有较大的差别。在生成正确目标代码的前提下适当地安排计算次序并优化代码序列,也是生成目标代码时要考虑的重要因素之一。
3. 解释程序基本原理
是另一种语言处理程序,在词法、语法和语义分析方面与编译程序的工作原理基本相同,但是在运行用户程序时,它直接执行源程序或源程序的中间表示形式。因此,解释程序不产生源程序的目标程序,这是它和编译程序的主要区别。
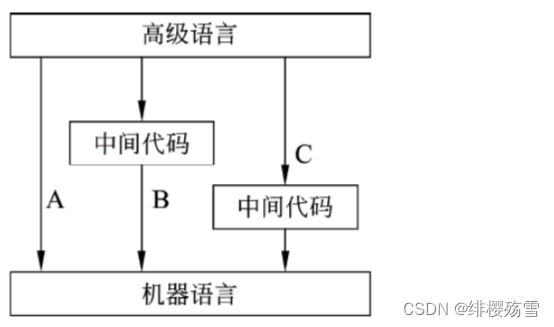
解释程序也可以先将源程序翻译成某种中间代码形式,然后对中间代码进行解释来实现用户程序的运行。通常,在中间代码和高级语言的语句间存在一一对应的关系。(1)解释程序的基本结构
- 分析部分:包括通常的词法分析、语法分析和语义分析程序,经语义分析后把源程序翻译成中间代码,中间代码常采用逆波兰表示形式。
- 解释部分:用来对第一部分产生的中间代码进行解释执行。
(2)高级语言编译与解释方式的比较
- 效率:编译比解释方式可能取得更高的效率。
一般情况下,在解释方式下运行程序时,解释程序可能需要反复扫描源程序。
在编译方式下,编译程序除了对源程序进行语法和语义分析外,还要生成源程序的目标代码并进行优化,所以这个过程比解释方式需要更多的时间。 - 灵活性:由于解释程序需要反复检查源程序,这也使得解释方式能够比编译方式更灵活。当解释器直接运行源程序时,“在运行中”修改程序就成为可能。另外,当解释器直接在源程序上工作时,它可以对错误进行更精确地定位。
- 可移植性:解释器一般也是用某种程序设计语言编写的,因此只要对解释器进行重新编译,就可以使解释器运行在不同的环境中。由于编译和解释的方法各有特点,因此现有的一些编译系统既提供编译的方式,也提供解释的方式,甚至将两种方式进行结合。
4. 表达式
前缀表达式 中缀表达式 后缀表达式 + 2 4 2 + 4 2 4 + + 2 * 4 6 2 + 4 * 6 2 4 6 * + + 2 * - 6 4 8 2 + (6 - 4)* 8 2 6 4 - 8 * + (1)前缀表达式【波兰式】
是一种没有括号的算术表达式,与中缀表达式不同的是,其将运算符写在前面,操作数写在后面。
① 中缀表达式 → 前缀表达式
- 方法一:直接转换法
中缀表达式:
1.主要内容

2.编译过程
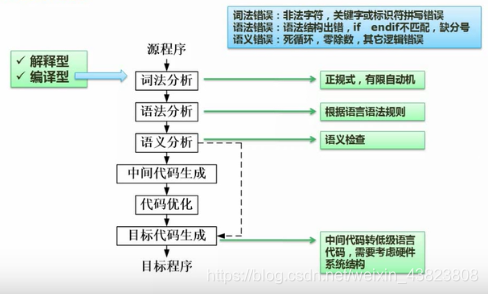
2.1 编译过程概述
编译程序的功能是把某高级语言书写的源程序翻译成与之等价的目标程序(汇编语言或机器语言)。
2.2 词法分析
词法分析阶段是编译过程的第一个阶段,这个阶段的任务是对源程序从前到后(从左到右)逐个字符地扫描,从中识别出一个个“单词” 符号。
“单词”符号是程序设计语言的基本语法单位,如关键字(或称保留字)、标识符、常数、运算符和分隔符(如标点符号、左右符号)等。词法分析程序输出的“单词”常以二元组的方式输出,即单词种别和单词自身的值。
2.3 语法分析
语法分析的任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位,如“表达式”、“语句”和“程序”等。词法分析和语法分析在本质上都是对源程序的结构进行分析。
2.4 语义分析
语义分析阶段分析各语法结构的含义,检查源程序是否包含静态语义错误,并收集类型信息供后面的代码生成阶段使用。
只有语法和语义分析都正确的源程序才能翻译成正确的目标代码。
2.5 中间代码生成
中间代码生成阶段的工作是根据语义分析的输出生成中间代码。“中间代码”是一种简单且含义明确的记号系统,可以有若干种形式,它们的共同特征是与具体的机器无关。
最常用的一种中间代码是与汇编语言的指令非常相似的三地址码。
2.6 代码优化
由于编译器将源程序翻译成中间代码的工作是机械的、按固定模式进行的,因此,生成的中间代码往往在时间上和空间上有较大的浪费。当需要生成高效的目标代码时,必须进行优化。
优化过程可以在中间代码生成阶段进行,也可以在目标代码生成阶段进行。
2.7 目标代码生成
目标代码生成阶段是编译器工作的最后一个阶段。这一阶段的任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码。这个阶段的工作与具体的机器密切相关。
3.文法定义

3.1 文法类型

3.2 语法推导树
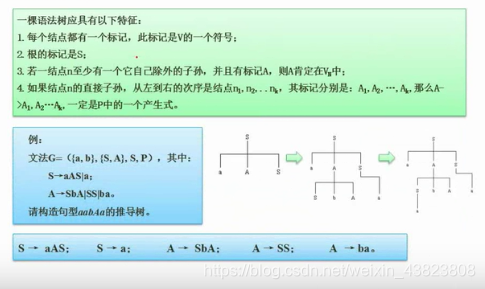
3.3 有限自动机
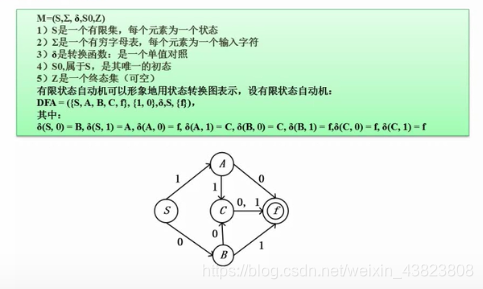
3.3.1 有限自动机例题
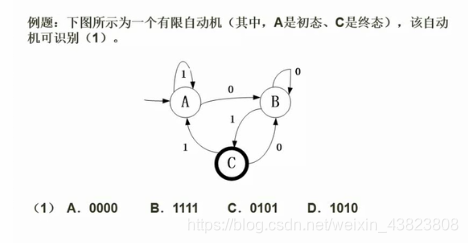
这类题相对于正规式的题要简单的多,没有什么技巧,直接按照四个选项给出的表达式去一步一步的推就可以了!!!
由于A是初态,C是终态,我们代入验证四个选项中哪一个可以由初态走到终态,即为正确答案。
A选项:0000,从A开始,由0到达B;再由0,仍然到达B(因为在B这里,0只能是以自身循环),所以0000无法识别。
B选项:1111,从A开始,由1到达A;再由1,仍然到达A(因为在A这里,1只能是以自身循环),所以1111无法识别。
C选项:0101,从A开始,由0到达B;再由1,到达C;再由0,到达B;最后由1,到达终态C,所以0101可以识别。
D选项:1010,从A开始,由1到达A;再由0,到达B;再由1,到达C;最后由0,到达B,所以1010无法识别。
3.4 正规式

3.4.1 正规式例题

上面这道例题,其中的丨表示“或”,*表示重复 [0,+∞)次。那么对于文法G[S]的分析如下:👇👇👇
第一空:👇👇👇
A选项:首先S→aA丨bB,可以推出aA;根据A→bS丨b,可以推出abS;根据S→aA丨bB,可以推出abaA;根据A→bS丨b,可以推出ababS;可以发现这样的正规式是一个以ab循环多次的字符串,即可以推出ababab。
B选项:首先S→aA丨bB,可以推出bB;根据B→aS丨a,可以推出baS;根据S→aA丨bB,可以推出babB;根据B→aS丨a,可以推出babaS;可以发现这样的正规式是一个以ba循环多次的字符串,即可以推出bababa。
C选项:首先S→aA丨bB,可以推出aA;根据A→bS丨b,可以推出abS;根据S→aA丨bB,可以推出abbB;根据B→aS丨a,可以推出abbaS;根据S→aA丨bB,可以推出abbaaA;根据A→bS丨b,可以推出abbaab。
D选项:首先S→aA丨bB,可以推出bB;根据B→aS丨a,可以推出baS;根据S→aA丨bB,可以推出babB;此时根据B→aS丨a,无法推出babb,因为B要么是aS、要么是a,不可能出现b这种情况,所以D选项是错误的!!!
第二空:意思是说这四个选项中哪一个可以将第一空中文法G[S]可以识别的三个选项都表示出来:👇👇👇
A选项:(a丨b)*,它可以将由a或b组成的任意串表达出来,也就是这样:a、ab、baa、babba这些都可以。那么它所表达的范围已经超出了文法G[S]可以识别的范围,它无法与文法G[S]保持等价,所以排除A选项。
B选项:(ab)*,它可以将由ab组成的串循环表示 [0,+∞) 次,也就是这样:ab、abab、abababab这些都可以。但是它无法表达第一空的B、C两个选项,因为它全部是以ab这样的形式表达的。所以排除B选项。
C选项:(ab丨ba)*,它可以生成任意数量的ab串或ba串,也就是这样:ababab、bababa或者abbaab这些都可以,它所表达的范围与文法G[S]完全等价!!!
D选项:(ab)*(ba)*,它的意思是:先来若干个ab串、再来若干个ba串,也就是这样:ababab、bababa、ababbaba这些都可以,但是它无法表示第一空的C选项。所以排除D选项。
4.表达式
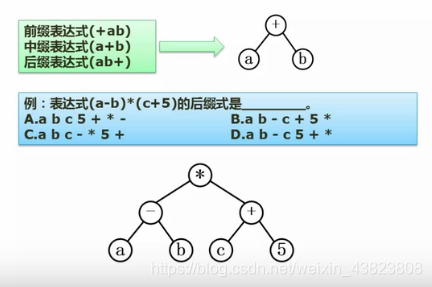
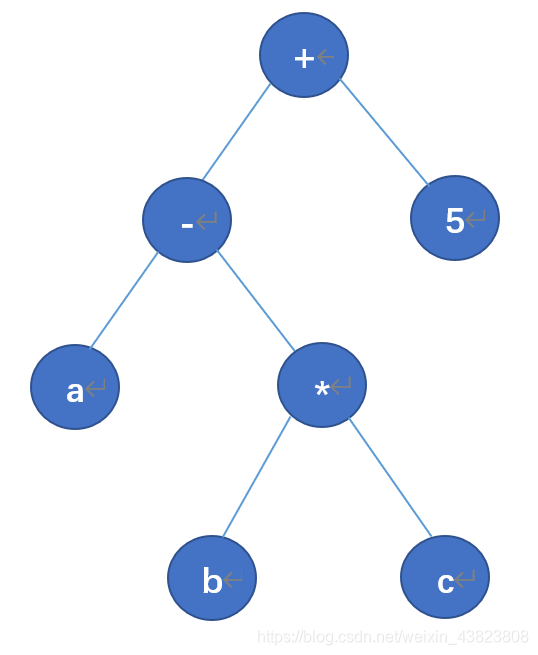
将表达式(a-b)*(c+5)构造成树的步骤为:括号不能出现在树中;按照表达式的计算顺序来依次构造!!!
第一步肯定是要计算(a-b),之后再计算(c+5),最后将这两者的结果相乘,所构造的树即为上图这种形式:👆👆👆
那么将树构造出来之后,对于前缀、中缀、后缀,无非就是二叉树的的前序、中序、后序遍历的过程:a b - c 5 + *。
如果说这里将表达式中的括号去掉:a - b * c + 5,那么所构造的树就不一样了,应该是下图所示的形式:👇👇👇
5.函数调用——传值与传址
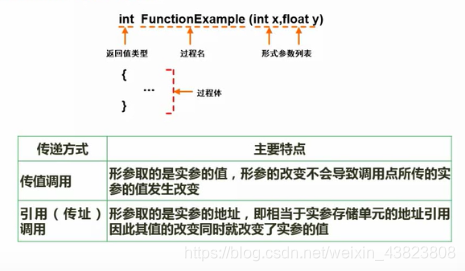
5.1 传值调用
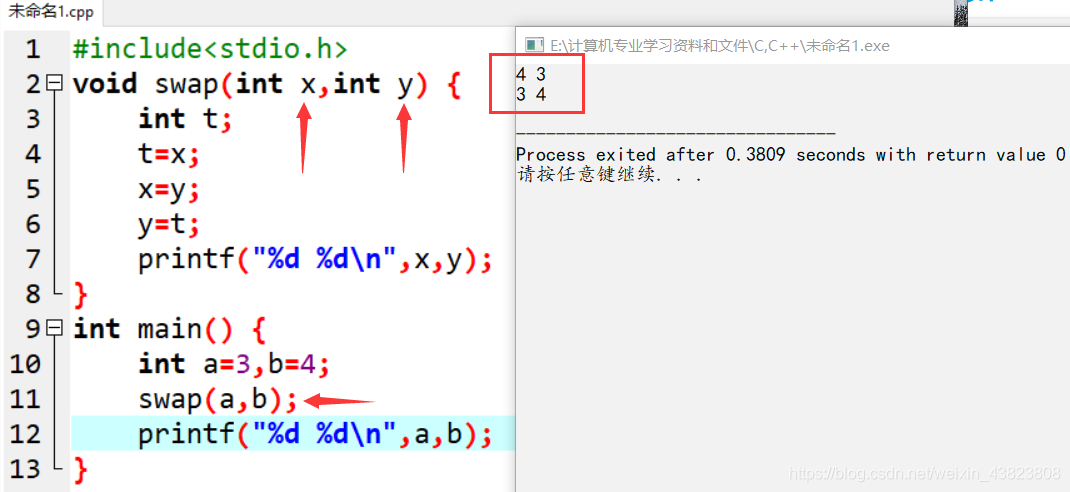
采用传值调用方式时,形参取的是实参的值,修改了形参并不会改变实参的具体值。对于上面这段代码,调用swap函数的语句swap(a,b),进入函数体void swap(int x,int y)的传值调用,虽然函数体内x和y的值进行了交换,第一行打印x和y的值分别为4、3,回到主函数之后,这里因为是传值调用并未改变实参a、b的值,所以a仍然为3,b仍然为4。
5.2 引用调用(传址调用)
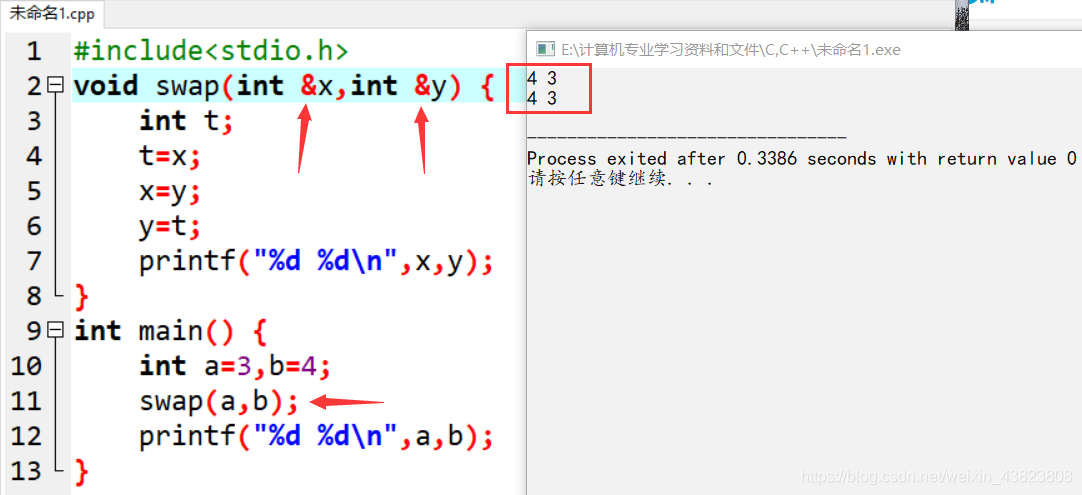
采用引用调用方式时,形参取的是实参的地址,即修改了形参实际上也就修改了实参(换句话说,形参与实参在这里是一样的)。对于上面这段代码,调用swap函数的语句swap(a,b),进入函数体void swap(int &x,int &y)的引用调用,函数体内x和y的值进行了交换,第一行打印x和y的值分别为4、3,回到主函数之后,这里因为是引用调用,修改了形参x、y的值,实际上也就修改了实参a、b的值,所以a为4,b为3。
6.各种程序语言特点

6.1 主要特点
①C:指针操作能力强,高效。
②C++:面向对象,高效。
③C#:面向对象,中间代码,.Net。
④Java:面向对象,中间代码,跨平台。
⑤Python:解释型,面向对象,胶水语言。
⑥Fortran:科学计算,执行效率高。
⑦Pascal:为教学而开发的,表达能力强,Delphi。
⑧Lisp:函数式程序语言,符号处理,人工智能。
⑨Prolog:逻辑推理,简洁性,表达能力,数据库和专家系统。
6.2 语言分类
①编译型:逐段编译,生成可执行程序exe等,执行效率高。
②解释型:逐句,解释器,跨平台,执行效率低。
7.数据类型与程序控制结构


















 2589
2589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









