




-
mysql有几种搜索引擎
MyISAM:非事务安全型,锁的粒度是表级,支持全文类型索引,效率高,MyISAM拥有较高的插入、查询速度,但不支持事物。
InnoDB(默认搜索引擎):事务安全型,支持行级锁定及外键,不支持全文索引,效率低,占用内存大,
meMory:数据量要求不大的时候memory是个不错的选择,它是将数据存到内存中,提供快速查询,
archive:如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive
-
-
sql优化
1.用具体的字段代替*,不要返回无用的字段
2.避免在where子句中使用!=和<>操作符,不要用or,in,not in,否则将放弃索引走全表扫描
3.分页查询
-
索引类型
全文索引:ALTER TABLE article ADD FULLTEXT index_content(content)
主键索引:建表的时候就会创建的主键索引
唯一索引:
CREATE UNIQUE INDEX indexName ON table(column(length))
ALTER TABLE table_name ADD INDEX index_name ON (column(length))普通索引:
CREATE INDEX index_name ON table(column(length))
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))组合索引:
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age); 索引失效:使用not in,<> , 使用like时候 如:"%xxx%"索引失效,但是可以"xxx%"
HashMap的扩容机制
名词:
- capacity 即容量,默认16。
- loadFactor 加载因子,默认是0.75
- threshold 阈值。阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容。
什么时候触发扩容?
一般情况下,当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的2倍。
HashMap的容量是有上限的,必须小于1<<30,即1073741824。如果容量超出了这个数,则不再增长,且阈值会被设置为Integer.MAX_VALUE( ![]() ,即永远不会超出阈值了)。
,即永远不会超出阈值了)。
JDK7中的扩容机制
JDK7的扩容机制相对简单,有以下特性:
- 空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。
- 有参构造函数:根据参数确定容量、负载因子、阈值等。
- 第一次put时会初始化数组,其容量变为不小于指定容量的2的幂数。然后根据负载因子确定阈值。
- 如果不是第一次扩容,则
 ,
, 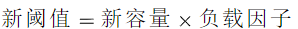 。
。
HashMap跟HashTable区别
HashMap:非线程安全,key可以为null,初始容量为16,自动扩容为原来2倍,HashMap继承了AbstractMap,
HashTable:线程安全的,因为它的方法是synchronize修饰的,保证了线程同步,key不能为null,初始容量为11,自动扩容为原来的2倍加1,继承了Dictionary抽象类,两者都实现了map接口
-
谈谈hashmap
HashMap:数组加链表,默认的存储大小为16,数组的HashMap为主体,链表主要是解决hash冲突而存在,在存贮数据时,当发生Hash冲突(存储元素的时候hash算法计算出来的位置上已经有元素了)并且size大于阈值的时候,数组会扩容为原来的两倍
总结:HashMap的实现原理:
- 利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
- 理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
-
arrayList跟linkedList区别
ArrayList:数组,尾部插入块,因为需要移动数组,中间插入和删除效率低,但是随机访问效率高
linkedList:双向链表,插入和删除效率高,因为它只需要移动指针,但是随机访问需要遍历链表,效率较低
-
linux常用命令
mkdir 创建文件
cat xxx.log 查看文件内容
tail -f xxx.log 实时查看文件内容
ps -ef|grup java 查看进程
kill 234 杀进程
rm -f 删除文件
vi 修改文件
:qw 保存文件并退出
-
线程实现方式
继承Thread类
public class MyThread extends Thread {
public void run() {
System.out.println("MyThread.run()");
}
}
实现Runnable接口
public class MyThread extends OtherClass implements Runnable {
public void run() {
System.out.println("MyThread.run()");
}
}
使用ExecutorService、Callable、Future实现有返回结果的多线程。其中前两种方式线程执行完后都没有返回值,只有最后一种是带返回值的。
-
线程生命周期
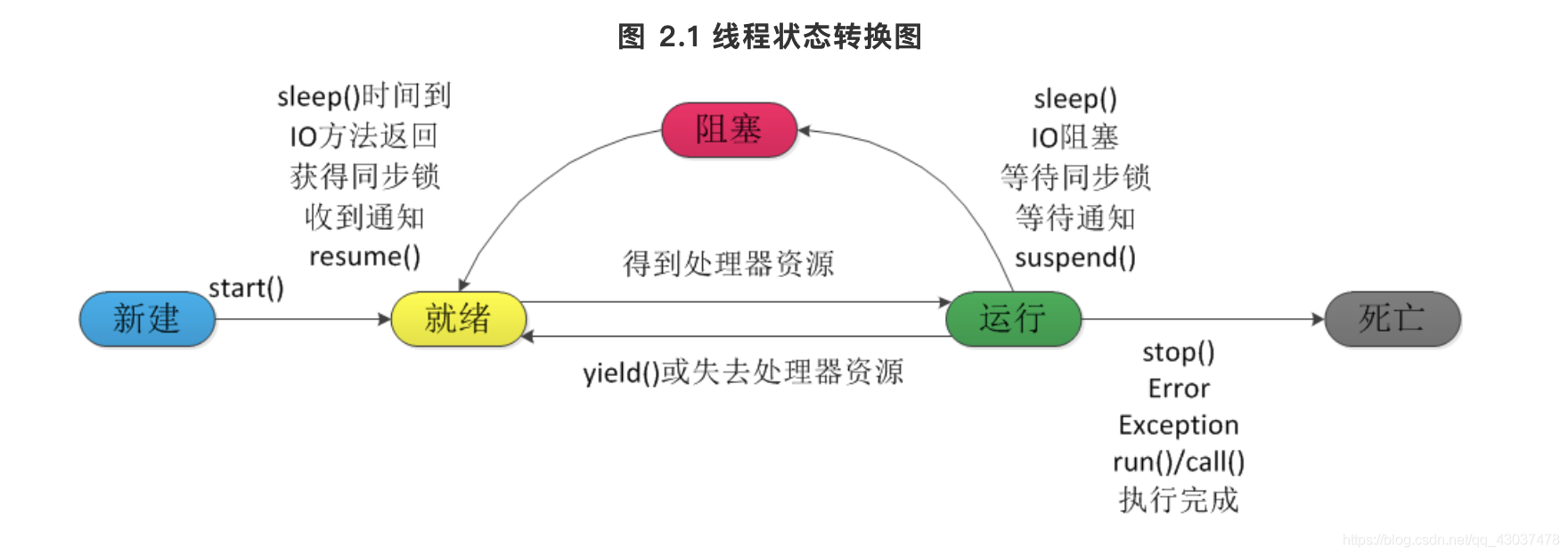
1. 新建状态,当程序使用new关键字创建了一个线程之后,该线程就处于新建状态,此时仅由JVM为其分配内存,并初始化其成员变量的值
2. 就绪状态,当线程对象调用了start()方法之后,该线程处于就绪状态。Java虚拟机会为其创建方法调用栈和程序计数器,等待调度运行
3. 运行状态,如果处于就绪状态的线程获得了CPU,开始执行run()方法的线程执行体,则该线程处于运行状态
4. 阻塞状态,当处于运行状态的线程失去所占用资源之后,便进入阻塞状态
5.死亡状态,run()或call()方法执行完成,线程正常结束。
ReentrantLock重入锁(互斥锁)的一些主要方法
1、lock() 获得锁
- 获得处于空闲的锁,
- 如果锁被其他线程持有,将禁用当前线程
2、unLock() 释放锁
- 当前线程将释放持有的锁。
- 锁只能由持有者释放。
- 如果线程并不持有锁,却执行了该方法,可能会导致异常的发生。
3、tryLock()
- 当获取空闲锁,如果所可用返回true,否则返回false
lock()和tryLock()区别:
lock():一定要获取锁,如果锁不可用就会一直等待,不会往下执行
tryLock():试图获取锁,如果锁不可用它会继续往下执行
Condition
Condition对象只能通过Lock类的newCondition()方法获取,因此一个Condition对象必然会有一个与其绑定的Lock锁
await()
将当前线程处于等待状态,并释放当前Condition对象锁绑定的锁
Signal()
唤醒一个在该Condition上挂起的线程,如果该对象存在多个线程等待,则随机选择一个线程
SignalAll()
唤醒所有在该Condition上的线程,所有线程会竞争与该Condition绑定的锁,
mybatis的一级、二级缓存
- 一级缓存:默认情况下mybatis使用的是一级缓存,一级缓存只是相对于一个sqlSession而言,所以在参数和sql完全一样的情况下,sql只会被执行一次,
生命周期:
mybatis在开启一个数据库会话的时候,会创建一个新的sqlsession对象,sql中有个Executor对象,Executor对象中有个PerpetualCache对象,会话结束会将SqlSession对象释放掉
如果sqlsession调用close()方法会释放一级缓存PerpetualCache对象,缓存不可用
如果sqlsession调用cleanCache(),会清空PerpetualCache对象的数据,缓存可用
sqlsession执行任何一个update操作(update,delete,insert)都会清空perpetualCache对象中的数据,缓存可用。
判断两次查询sql是相同查询?
1.statementId相同
2.参数相同,
3.sql语句相同
- 二级缓存:提高查询效率。默认是不开启的,二级缓存开启需要配置,在使用二级缓存的时候,mybatis要求返回的pojo需要实现序列化接口,
- mapper.xml配置:<cache eviction="LRU" flushInterval="100000" readOnly="true" size="1024"/>
- 或者在 mybatis-config.xml中开启二级缓存
<configuration>
<settings>
<!--这个配置使全局的映射器(二级缓存)启用或禁用缓存-->
<setting name="cacheEnabled" value="true" />
.....
</settings>
....
</configuration>生命周期:
映射语句文件中所有select语句都会缓存
映射语句文件中所有update操作(update,insert,delete)都会刷新缓存
缓存会使用默认LRU算法来回收
mybatis大于号小于号转译
大于:>
小于:< xml中不能用< (小于号)
#和$区别:
#:会对传入数据默认添加双引号,能防止sql注入
$: $将传入的数据直接显示生成在sql中,不能防止sql注入(注入实例:填用户名密码登录,用户名为:"'xiateng' or 1=1" 这样写的话只要用户名输对了就能登录成功)
为什么要用activeMQ,
不同语言集成,它支持很多种语言,如:c/c++,.net,php,python等,如果考虑不同平台不同语言下的应用集成的话,优势很大
解耦,降低应用程序之间的耦合度。
异步消息通讯,提高了处理效率
spring IOC
控制反转,将创建对象权交由Spring来管理,并由Spring(ioc)来保存创建的对象
spring设计模式
代理模式
工厂模式:隐藏复杂的逻辑,只关心结果
委派模式
策略模式:比较的方法,结果固定的
原型模式:克隆,深克隆:序列化跟反序列化生成新的对象,重新分配内存,浅克隆:复制对象的基本数据和String的数值。
模板模式:jdbc代码,
代理模式使用在哪
redis哪里用到了,集群,清理没用的内存机制,持久化机制
1.redis支持的数据类型:String(命令get、set、incr、decr),List(lpush,rpush,lpop,rpop),set(sadd,spop),Hash(hget,hset)
LRU算法,least RecentlyUsed,最近最少使用算法。也就是说默认删除最近最少使用的键。
redis的几种淘汰策略:maxmemory-policy noeviction 参数配置
volatile-lru:使用LRU算法随机删除一个键(key),注:只对设置了生存时间的键
allkeys-lru:使用LRU算法随机删除一个键(推荐)
volatile-random:随机删除一个键 , 注:只对设置了生存时间的键
allkeys-random:随机删除一个键
volatile-ttl:删除生存时间最近的一个键
noeviction(默认策略):不删除键,只返回错误
2、MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
redis内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
持久化机制:
AOF(append only file)原理是将Reids的操作日志以追加的方式写入文件
RDB 持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
AOF持久化配置
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
redis集群
随着数据量的增多,虽然redis速度还是非常可观的,但是只是在一个节点中存取速度也是会大打折扣的,所以我们应该在不同服务器上构建多个节点,将key分配到不同的节点上,实现高可用,这就是集群
方案 redis-cluster
原理:redis-cluster是采用的哈希槽(hash solt)方式来分配的,redis-cluster默认分配了16384个slot,当我们set一个key时,会使用CRC16算法来取模得到所属的slot,然后分配到哈希槽区间的节点上,具体算法CRC16(key) % 16384。读的时候根据一致性哈希算法获取到节点上的值。
注:会把数据存储到一个master节点,然后异步同步到slave,master挂了才会切到slave,必须最少三个节点,半数以上节点失效会导致集群不可用
jvm内存模型,
方法区:方法信息(类名,方法信息)、静态变量,常量,以及编译后的代码
堆:对象本身,集合
栈:
jvm工作原理:我们编写java代码,通过java编译器编译成.class文件,然后将字节码转入内存,一旦字节码进入虚拟机,就会被解释器解释执行
springboot介绍
1.什么是SpringBoot?
springboot是spring开源组织下的子项目,是spring组件的一站式解决方案,降低了spring的使用难度,减少了繁琐的配置,容易上手,
2.Springboot特点?
简化配置,
自动配置
独立打包,直接运行
内嵌服务器
上手容易
3.核心注解
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
@ComponentScan:Spring组件扫描。
Spring Boot可以通过@ PropertySource,@ Value,@ Environment,@ ConfigurationProperties来绑定变量
4.springboot可以另外建立三个配置文件《Spring Boot Profile 不同环境配置》。
applcation.properties
application-dev.properties
application-test.properties
application-prod.properties
然后在applcation.properties文件中指定当前的环境spring.profiles.active=test,这时候读取的就是application-test.properties文件。
Dubbo分布式服务框架
dubbo是个分布式服务框架,主要用于提高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
更多详细看这https://juejin.im/post/5ab09943f265da238f125ee8



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









