



flume理论
flume官网:使用指导
查看文件大小指令:du -h --max-depth=1*
1、安装包
链接:https://pan.baidu.com/s/1XBnqxB6Rdm4r6I2lIgGU0A
提取码:9xvp
2、文件配置
export JAVA_HOME=/opt/jdk1.8.0_221
#java工作环境,给与的内存
export JAVA_OPTS="-Xms2048m -Xmx2048m -Dcom.sun.management.jmxremote"
可以选择配置环境变量,如果不配置,在启动时需要在bin目录下启动。
vi /etc/profile
#配置变量
export FLUME_HOME=/opt/flume
export PATH=$PATH:$FLUME_HOME/bin
#保存退出后
source /etc/profile
3、下载安装包
yum install -y nc
yum list telnet*
yum install -y telnet-server.*
yum install -y telnet.*
4、测试
server端
7777是自定义的,可以自己指定
nv -lk 7777
client端
telnet localhost 7777
此时在server端输入数据,client端同步输出
5、
netcat-flume-logger.conf文件
vi netcat-flume-logger.conf
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=7777
a1.channels.c1.type=memory
#The maximum number of events stored in the channel
a1.channels.c1.capacity=1000
#The maximum number of events the channel will take from a source or give to a sink per transaction
a1.channels.c1.transactionCapacity=1000
#logger表示控制台输出
a1.sinks.k1.type=logger
a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1
启动
-Dflume.root.logger=INFO,console:显示运行信息到控制台,实际生产中可以不写
./bin/flume-ng agent --name a1 --conf ./conf/ --conf-file ./conf/jobkb09/netcat-flume-logger.conf \
-Dflume.root.logger=INFO,console
telnet localhost 7777
client端输入,同步输出
file-flume-logger.conf文件
vi file-flume-logger.conf
实时更新
a2.sources=r1
a2.channels=c1
a2.sinks=k1
a2.sources.r1.type=exec
a2.sources.r1.command=tail -f /opt/flume/conf/jobkb09/tmp/tmp.txt
a2.channels.c1.type=memory
a2.channels.c1.capacity=1000
a2.channels.c1.transactionCapacity=1000
a2.sinks.k1.type=logger
a2.sources.r1.channles=c1
a2.sinks.k1.channel=c1
启动
./bin/flume-ng agent --name a2 --conf ./conf/ --conf-file ./conf/jobkb09/file-flume-logger.conf -Dflume.root.logger=INFO,console
往文件中插入数据,同步更新。
tmp.txt
hello
haahah
world
#覆盖数据:
echo ssss > tmp/tmp.txt
#追加数据
echo spark >> tmp/tmp.txt
events-flume-logger.conf文件
实时更新
events.sources=eventsSource events.channels=eventsChannel events.sinks=eventsSink
events.sources.eventsSource.type=spooldir
events.sources.eventsSource.spoolDir=/opt/flume/conf/job/dataSourceFile/events
events.sources.eventsSource.deserializer=LINE
#如果不赋值maxLineLength的值,当文件字段很长时,会自动截取为一行 ,单位是字节
events.sources.eventsSource.deserializer.maxLineLength=10000
模式匹配 events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.channels.eventsChannel.type=file
events.channels.eventsChannel.checkpointDir=/opt/flume/conf/job/checkpointFile/events
events.channels.eventsChannel.dataDirs=/opt/flume/conf/job/dataChannelFile/events
events.sinks.eventsSink.type=logger
events.sources.eventsSource.channels=eventsChannel
events.sinks.eventsSink.channel=eventsChannel
创建相应文件:mkdir -p checkpointFile/events等等。
统计行数: wc -l events.csv
统计列数:wc -L events.csv
./bin/flume-ng agent --name events --conf ./conf/ --conf-file ./conf/jobkb09/events-flume-logger.conf -Dflume.root.logger=INFO,console
把文件拷贝到dataSourceFile/events文件下,另一个会同步读取
cp events.csv ../dataSourceFile/events/events_2020-11-30.csv
上传到HDFS
可以先把文件放到指定目录,也可以稍后在复制进去
cp events.csv ../dataSourceFile/users/
vi test1.conf
events.sources=f1
events.channels=c1
events.sinks=s1
#source的实现方式
events.sources.f1.type=spooldir
#收集端的文件路径
events.sources.f1.spoolDir=/data/flume/dataSourceFile/users
#反序列化
events.sources.f1.deserializer=LINE
#Max line length per event body (in bytes),如果不赋值,当文件字段很长时,会自动截取为一行
events.sources.f1.deserializer.maxLineLength=320000
#模式匹配相应的文件。events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.sources.f1.includePattern=events.csv
events.channels.c1.type=file
events.channels.c1.checkpointDir=/data/flume/checkpoint/users
events.channels.c1.dataDirs=/data/flume/channelFile/users
events.sinks.s1.type=hdfs
events.sinks.s1.hdfs.fileType=DataStream
#前缀
events.sinks.s1.hdfs.filePrefix=events
#后缀
events.sinks.s1.hdfs.fileSuffix=.csv
events.sinks.s1.hdfs.path=hdfs://hadoop01:9000/spark/events/%Y-%m-%d
#使用本地时间戳
events.sinks.s1.hdfs.useLocalTimeStamp=true
#每批events大小。number of events written to file before it is flushed to HDFS
events.sinks.s1.hdfs.batchSize=640
#滚动间隙(seconds)Number of seconds to wait before rolling current file (0 = never roll based on time interval)
events.sinks.s1.hdfs.rollInterval=20
#Number of events written to file before it rolled (0 = never roll based on number of events)
events.sinks.s1.hdfs.rollCount=0
#File size to trigger roll, in bytes (0: never roll based on file size)
events.sinks.s1.hdfs.rollSize=1200000000
events.sources.f1.channels=c1
events.sinks.s1.channel=c1
创建相应路径:
mkdir /data/flume/dataSourceFile/users
mkdir /data/flume/checkpoint/users
mkdir /data/flume/channelFile/users
开始执行:
./bin/flume-ng agent --events user_friend --conf ./conf/ --conf-file ./conf/confFile/test7.conf -Dflume.root.logger=INFO,console
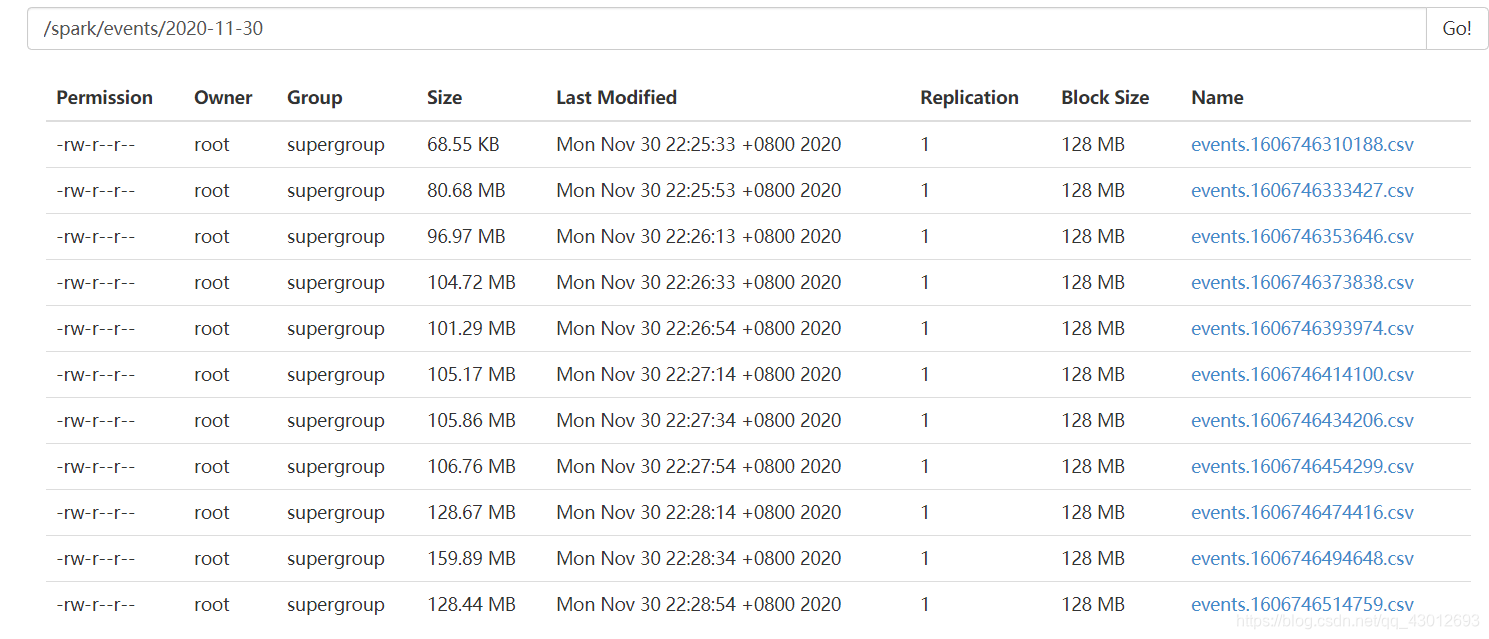
筛选掉头后上传
tests.sources=testsource
tests.channels=testChannel
tests.sinks=testsink
tests.sources.testsource.type=spooldir
tests.sources.testsource.spoolDir=/opt/flume/conf/jobkb09/dataSourceFile/user
tests.sources.testsource.includePattern=test_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
tests.sources.testsource.deserializer=LINE
tests.sources.testsource.deserializer.maxLineLength=10000
tests.sources.testsource.interceptors=head_filter
#The component type name has to be regex_extractor
tests.sources.testsource.interceptors.head_filter.type=regex_filter
#Regular expression for matching against events.^表示开头。
tests.sources.testsource.interceptors.head_filter.regex=^user*
#If true, regex determines events to exclude, otherwise regex determines events to include.
tests.sources.testsource.interceptors.head_filter.excludeEvents=true
tests.channels.testChannel.type=file
tests.channels.testChannel.checkpointDir=/opt/flume/conf/jobkb09/checkPointFile/user
tests.channels.testChannel.dataDirs=/opt/flume/conf/jobkb09/dataChannelFile/user
tests.sinks.testsink.type=hdfs
tests.sinks.testsink.hdfs.fileType=DataStream
tests.sinks.testsink.hdfs.filePrefix=tests
tests.sinks.testsink.hdfs.fileSuffix=.csv
tests.sinks.testsink.hdfs.path=hdfs://hadoop01:9000/kb09file/user/tests/%Y-%m-%d
tests.sinks.testsink.hdfs.useLocalTimeStamp=true
tests.sinks.testsink.hdfs.batchSize=640
tests.sinks.testsink.hdfs.rollInterval=20
tests.sinks.testsink.hdfs.rollCount=0
tests.sinks.testsink.hdfs.rollSize=120000000
tests.sources.testsource.channels=testChannel
tests.sinks.testsink.channel=testChannel
flume-ng agent --name tests --conf /opt/flume/conf/ \
--conf-file /opt/flume/conf/jobkb09/test.conf \
-Dflume.root.logger=INFO,console
#或者
flume-ng agent --n tests -c /opt/flume/conf/ -f /opt/flume/conf/jobkb09/test.conf -Dflume.root.logger=INFO,console
自定义interceptor
导入依赖包:
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.6.0</version>
</dependency>
java:
public class InterceptorDemo implements Interceptor {
private List<Event> addHeaderEvents;
@Override
public void initialize() {
addHeaderEvents = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
Map<String, String> headers = event.getHeaders();
String bodyStr = new String(body);
if(bodyStr.startsWith("gree")){
headers.put("type", "gree");
}else{
headers.put("type", "sam");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
//清空,否则会留存上一步的信息
addHeaderEvents.clear();
for (Event event : events) {
addHeaderEvents.add(intercept(event));
}
return addHeaderEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new InterceptorDemo();
}
@Override
public void configure(Context context) {
}
}
}
打完jar包上传到flume下的lib文件中
shell:
ictdemo.sources=ictSource
ictdemo.channels=ictChannel1 ictChannel2
ictdemo.sinks=ictSink1 ictSink2
ictdemo.sources.ictSource.type=netcat
ictdemo.sources.ictSource.bind=localhost
ictdemo.sources.ictSource.port=7777
ictdemo.sources.ictSource.interceptors=iterceptor1
#jar包方法的路径
ictdemo.sources.ictSource.interceptors.iterceptor1.type=test.InterceptorDemo$Builder
ictdemo.sources.ictSource.selector.type=multiplexing
ictdemo.sources.ictSource.selector.header=type
ictdemo.sources.ictSource.selector.mapping.gree=ictChannel1
ictdemo.sources.ictSource.selector.mapping.sam=ictChannel2
ictdemo.channels.ictChannel1.type=memory
ictdemo.channels.ictChannel1.capacity=1000
ictdemo.channels.ictChannel1.transactionCapacity=1000
ictdemo.channels.ictChannel2.type=memory
ictdemo.channels.ictChannel2.capacity=1000
ictdemo.channels.ictChannel2.transacitonCapacity=1000
ictdemo.sinks.ictSink1.type=hdfs
ictdemo.sinks.ictSink1.hdfs.fileType=DataStream
ictdemo.sinks.ictSink1.hdfs.filePrefix=gree
ictdemo.sinks.ictSink1.hdfs.fileSuffix=.csv
ictdemo.sinks.ictSink1.hdfs.path=hdfs://hadoop01:9000/test/user/gree/%Y-%m-%d
ictdemo.sinks.ictSink1.hdfs.useLocalTimeStamp=true
ictdemo.sinks.ictSink1.hdfs.batchSize=640
ictdemo.sinks.ictSink1.hdfs.rollCount=0
ictdemo.sinks.ictSink1.hdfs.rollSize=10000
ictdemo.sinks.ictSink1.hdfs.rollInterval=3
ictdemo.sinks.ictSink2.type=hdfs
ictdemo.sinks.ictSink2.hdfs.fileType=DataStream
ictdemo.sinks.ictSink2.hdfs.filePrefix=sam
ictdemo.sinks.ictSink2.hdfs.fileSuffix=.csv
ictdemo.sinks.ictSink2.hdfs.path=hdfs://hadoop01:9000/test/user/sam/%Y-%m-%d
ictdemo.sinks.ictSink2.hdfs.useLocalTimeStamp=true
ictdemo.sinks.ictSink2.hdfs.batchSize=640
ictdemo.sinks.ictSink2.hdfs.rollCount=0
ictdemo.sinks.ictSink2.hdfs.rollSize=10000
ictdemo.sinks.ictSink2.hdfs.rollInterval=3
ictdemo.sources.ictSource.channels=ictChannel1 ictChannel2
ictdemo.sinks.ictSink1.channel=ictChannel1
ictdemo.sinks.ictSink2.channel=ictChannel2
启动:
flume-ng agent --name ictdemo --conf /opt/flume/conf/ --conf-file /opt/flume/conf/jobkb09/netcat-flume-interceptor-hdfs.conf -Dflume.root.logger=INFO,console
从控制台输入:
telnet localhost 7777
再一个例子:
筛选包含某一个的:
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class DefinInter implements Interceptor {
private List<Event> header;
@Override
public void initialize() {
header = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
Map<String, String> headers = event.getHeaders();
String s = new String(body);
if (s.contains("zhangsan")) {
headers.put("type", "zhangsan");
} else {
headers.put("type", "lisi");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
header.clear();
for (Event event : events) {
header.add(intercept(event));
}
return header;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new DefinInter();
}
@Override
public void configure(Context context) {
}
}
}
names.sources=nameSource
names.channels=nameChannel1 nameChannel2
names.sinks=nameSink1 nameSink2
names.sources.nameSource.type=spooldir
names.sources.nameSource.spoolDir=/data/flume/dataSourceFile/test
names.sources.nameSource.includePattern=name.txt
names.sources.nameSource.deserializer=LINE
names.sources.nameSource.deserializer.maxLineLength=1000
names.sources.nameSource.interceptors=personName
names.sources.nameSource.interceptors.personName.type=flume.DefinInter$Builder
names.sources.nameSource.selector.type=multiplexing
names.sources.nameSource.selector.header=type
names.sources.nameSource.selector.mapping.zhangsan=nameChannel1
names.sources.nameSource.selector.mapping.lisi=nameChannel2
names.channels.nameChannel1.type=file
names.channels.nameChannel1.checkpointDir=/data/flume/checkpoint/test1
names.channels.nameChannel1.dataDirs=/data/flume/channelFile/test1
names.channels.nameChannel2.type=file
names.channels.nameChannel2.checkpointDir=/data/flume/checkpoint/test2
names.channels.nameChannel2.dataDirs=/data/flume/channelFile/test2
names.sinks.nameSink1.type=hdfs
names.sinks.nameSink1.hdfs.fileType=DataStream
names.sinks.nameSink1.hdfs.filePrefix=zs
names.sinks.nameSink1.hdfs.fileSuffix=.txt
names.sinks.nameSink1.hdfs.path=hdfs://192.168.136.30:9000/spark/user/zs/%Y-%m-%d
names.sinks.nameSink1.hdfs.useLocalTimeStamp=true
names.sinks.nameSink1.hdfs.batchSize=640
names.sinks.nameSink1.hdfs.rollInterval=3
names.sinks.nameSink1.hdfs.rollCount=0
names.sinks.nameSink1.hdfs.rollSize=1200000
names.sinks.nameSink2.type=hdfs
names.sinks.nameSink2.hdfs.fileType=DataStream
names.sinks.nameSink2.hdfs.filePrefix=ls
names.sinks.nameSink2.hdfs.fileSuffix=.txt
names.sinks.nameSink2.hdfs.path=hdfs://192.168.136.30:9000/spark/user/ls/%Y-%m-%d
names.sinks.nameSink2.hdfs.useLocalTimeStamp=true
names.sinks.nameSink2.hdfs.batchSize=640
names.sinks.nameSink2.hdfs.rollInterval=3
names.sinks.nameSink2.hdfs.rollCount=0
names.sinks.nameSink2.hdfs.rollSize=1200000
names.sources.nameSource.channels=nameChannel1 nameChannel2
names.sinks.nameSink1.channel=nameChannel1
names.sinks.nameSink2.channel=nameChannel2


















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









