




Hadoop的来源
- 03年Google将海量数据的存储和计算的解决方案以三篇论文的形式发表出来:GFS(google文件系统,解决海量数据存储)、MapReduce(解决海量数据的计算问题)、BigTable(解决海量数据查询问题)。
- Hadoop之父Doug Cutting将这三篇论文用java实现并开源:
GFS------HDFS hadoop的分布式文件系统
MapReduce-------MapReduce
BigTable------Hbase - 这个项目在他的Nutch项目中,之后进行分离出来,成为独立项目Hadoop,HDFS+MapReduce=Hadoop、Hbase
之后贡献给Apache基金会 - yahoo挖走了doug cutting
Hadoop是什么
- Hadoop是Apache旗下的一套开源软件平台
- Hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理。
- Apache™Hadoop®项目提供了高可靠(不间断的提供服务),高可扩展(横向扩展能力)的分布式计算的开源软件。
- Apache Hadoop软件库是一个框架,允许使用简单的编程模型(mapreduce)跨计算机集群分布式处理大型数据集。它旨在从单个服务器扩展到数千台计算机,依赖每台计算机都提供本地计算和存储。本身不是依靠硬件来提供高可用性,而是设计用于检测和处理应用程序层的故障,从而在计算机集群之上提供高可用性服务,每个计算机都可能容易出现故障。
hadoop中将硬件错误看做一个常态
Hadoop的模块
Hadoop1.0
Hdfs+MapReduce
Hadoop2.0
Hadoop的核心组件:
- Common:基础功能组件(工具包,RPC框架)
- Hdfs:Hadoop Distributed File System分布式文件系统
- Yarn:Yet Another Resources Negotiator运算资源调度系统
- MapReduce:Map、Reduce分布式运算编程框架
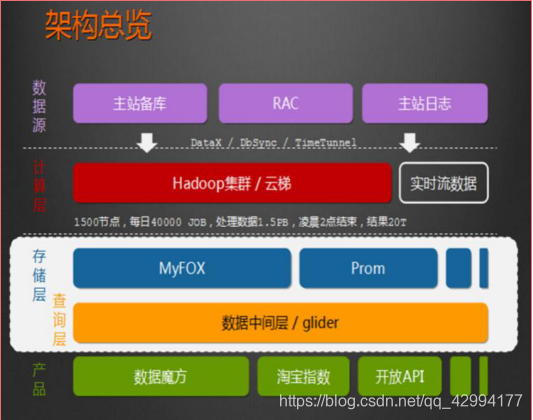
Hadoop技术应用架构概览
Hadoop应用于数据服务基础平台建设
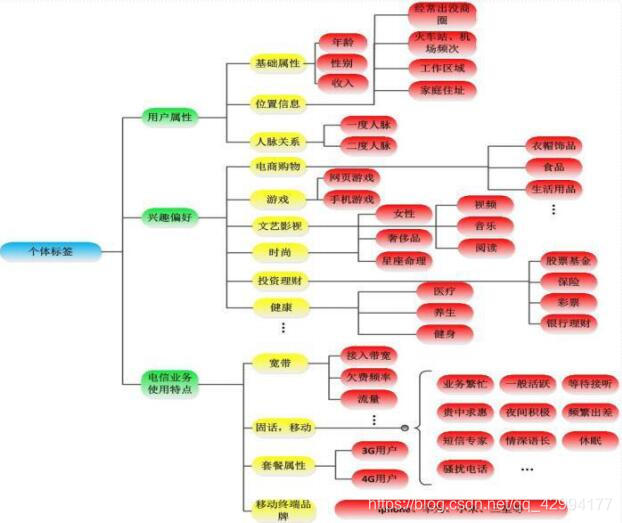
Hadoop用于用户画像
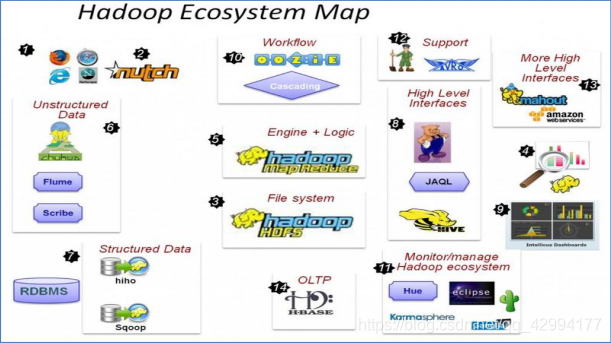
Hadoop生态圈以及各组成部分的简介
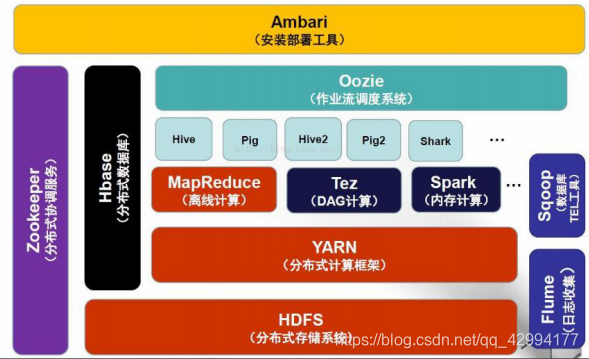
重点组件:
- HDFS:Hadoop的分布式文件存储系统
- MapReduce:Hadoop的分布式计算框架,也可叫一种编程模型
- Hive:基于Hadoop的类SQL数据仓库工具
- HBase:基于Hadoop的列式分布式NoSQL数据库
- ZooKeeper:分布式协调服务组件
- Mahout:基于MapReduce/Flink/Spark等分布式运算框架的机器学习算法库
- Oozie/Azkaban:工作流调度引擎
- Sqoop:数据迁入迁出工具
- Flume:日志采集工具
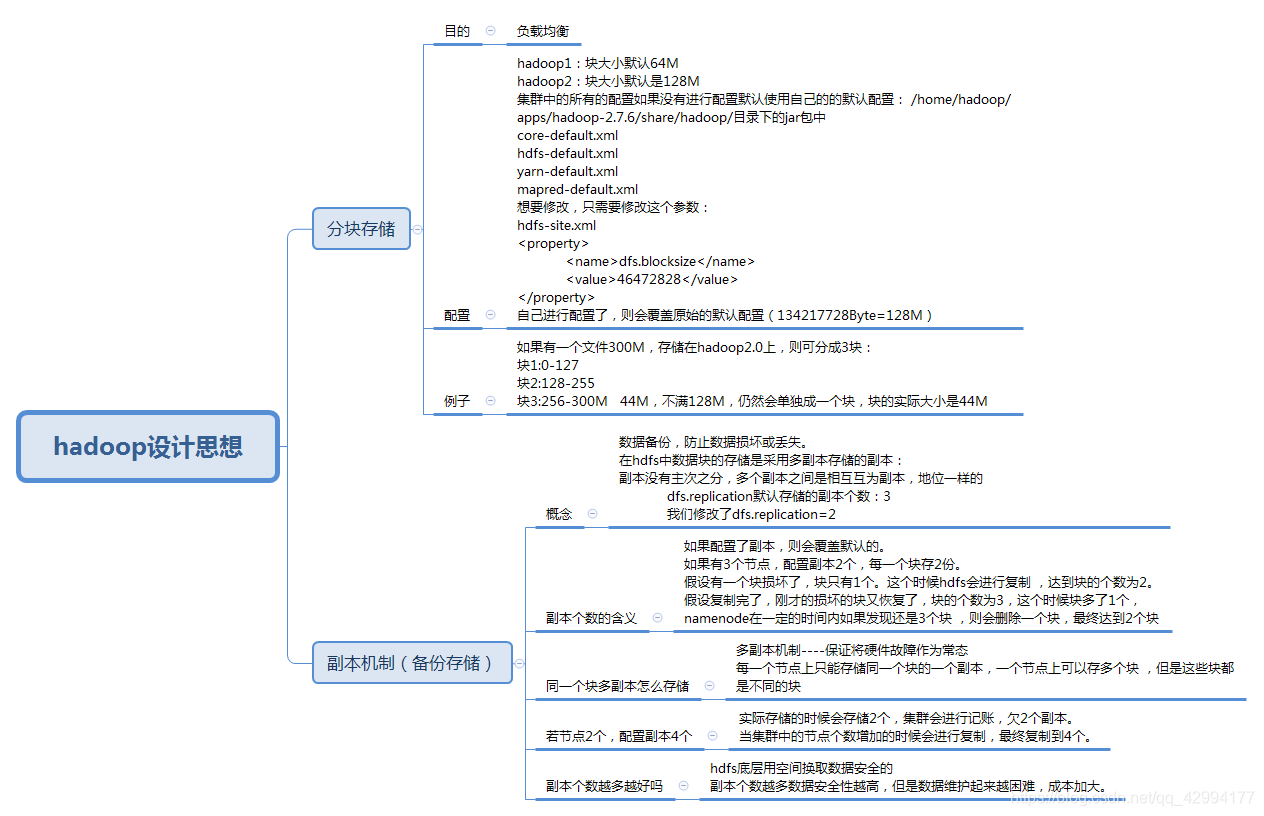
Hadoop的设计思想

















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









