




 本文深入探讨了Pandas中函数应用和映射的高级用法,包括使用apply方法对DataFrame进行操作,以及如何利用sort_index和sort_values进行高效的数据排序。此外,还介绍了如何对数据进行排名。
本文深入探讨了Pandas中函数应用和映射的高级用法,包括使用apply方法对DataFrame进行操作,以及如何利用sort_index和sort_values进行高效的数据排序。此外,还介绍了如何对数据进行排名。
函数应用和映射
NumPy的ufuncs(元素级数组方法)可用于操作pandas对象

=====================================
另一个常见的操作是,将函数应用到由各列或行所形成的一维数组上。DataFrame 的apply方法即可实现此功能。函数f,计算了一个Series的最大值和最小值的差,在frame的每列都执行了一次。结果是一个Series,使用frame的列作为索引。

=====================================
如果传递axis='columns’到apply,这个函数会在每行执行。许多最为常见的数组统计功能都被实现成DataFrame的方法(如sum和mean),因此无需使用apply方法

=====================================
传递到apply的函数不是必须返回一个标量,还可以返回由多个值组成的Series

=====================================
元素级的Python函数也是可以用的
想得到frame中各个浮点值的格式化字符串,使用applymap即可

=====================================
叫做applymap,是因为Series有一个用于应用元素级函数的map方法

排序和排名
根据条件对数据集排序(sorting)也是一种重要的内置运算
要对行或列索引进行排序(按字典顺序),可使用sort_index方法,它将返回一个已排序的新对象
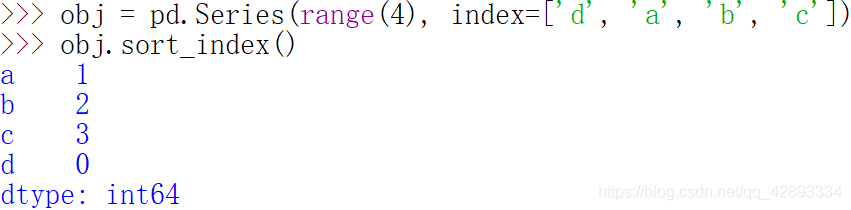
=====================================
对于DataFrame,则可以根据任意一个轴上的索引进行排序

=====================================
数据默认是按升序排序的,但也可以降序排序
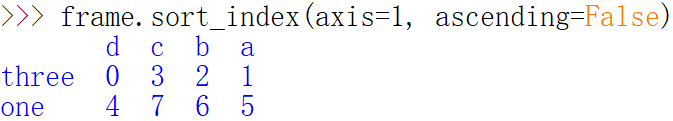
=====================================
若要按值对Series进行排序,可使用其sort_values方法

=====================================
在排序时,任何缺失值默认都会被放到Series的末尾

=====================================
当排序一个DataFrame时,你可能希望根据一个或多个列中的值进行排序。将一个 或多个列的名字传递给sort_values的by选项即可达到该目的

=====================================
根据多个列进行排序,传入名称的列表即可
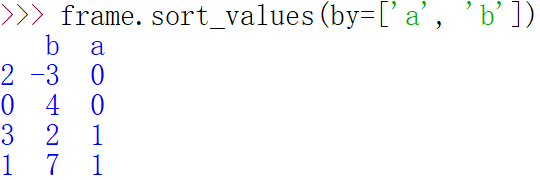
=====================================
排名会从1开始一直到数组中有效数据的数量。
默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系

=====================================
根据值在原数据中出现的顺序给出排名

=====================================
按降序进行排名

=====================================
DataFrame可以在行或列上计算排名

++++++++++++++++++++++++++++++++++++


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









