






QueryParser 的基本作用是将一个满足特定语法的字符串转换成相应的查询对象。我们可以不再需要使用组合对象的方式来手动构造复合逻辑查询,而是通过一个单行字符串就可以完成原先需要数行代码才能完成的查询功能。
范围查询
Lucence 对于整数范围和字符串范围是不一样的处理方式,它有 NumericRangeQuery 和 TermRangeQuery,但是默认的 QueryParser 表达式仅支持 TermRangeQuery,使用下面的范围表达式解析出来的结果将会是 TermRangeQuery。如果对整形的 article_id 字段进行字符串的范围查询,那么结果将会是空集。
var parser = new QueryParser("article_id", analyser);
var query = parser.parse("[400000 TO 450000]");
System.out.println(query);
System.out.println(query.getClass());
// 那我们能不能让 QueryParser 支持 NumbericRangeQuery 呢?办法是有的,但是会比较麻烦一些,
// 需要我们使用代码来手动修改 QueryParser 的默认行为 —— 编写一个子类,
// 覆盖掉默认的 getRangeQuery 方法。
static class MyQueryParser extends QueryParser {
public MyQueryParser(String f, Analyzer a) {
super(f, a);
}
@Override
protected Query getRangeQuery(String field, String low, String high, boolean startInclusive, boolean endInclusive) throws ParseException {
if(this.field.equals(field)) {
return IntPoint.newRangeQuery(field, Integer.parseInt(low), Integer.parseInt(high));
}
return super.getRangeQuery(field, low, high, startInclusive, endInclusive);
}
}
---------------
article_id:[400000 TO 450000]
class org.apache.lucene.search.TermRangeQuery
我们注意到 IntPoint.newRangeQuery 似乎没有提供边界参数,它默认是不包含边界的。如果期望处理边界参数,那就需要对参数进行 +1 和 -1 的微调,下限 -1,上限 +1。如果是浮点数,那就需要使用 FloatPoint.nextUp/nextDown 方法给浮点参数进行微调。下面我们使用上面自定义的 QueryParser 看看结果如何。
var analyser = new HanLPAnalyzer();
var parser = new MyQueryParser("article_id", analyser);
var query = parser.parse("[400000 TO 450000]");
System.out.println(query);
System.out.println(query.getClass());
var hits = searcher.search(query, 10).scoreDocs;
System.out.println(hits.length);
--------------
article_id:[400000 TO 450000]
class org.apache.lucene.document.IntPoint$1
10
前缀查询 PrefixQuery 和通配符查询 WildcardQuery
这两个查询都是有效利用了关键词树 FST 的前缀属性来扫描出匹配的关键词集合。PrefixQuery 可以理解为 WildcardQuery 的子集。通配符查询的 QueryParser 语法比较简单,还是使用 * 号和 ? 号。
var parser = new QueryParser("content", analyser);
var query = parser.parse("北京*");
System.out.println(query);
System.out.println(query.getClass());
--------
content:北京*
class org.apache.lucene.search.PrefixQuery
为了避免性能问题,QueryParser 默认禁止首字符带 * 号的查询,在调用 parse 方法时会直接抛异常。
关于首字符带 * 号,QueryParser 还有一个例外情况,它内置了一个非常特殊的通配符 : ,它表示匹配所有的内容,也就是全文遍历 MatchAllDocsQuery。
var parser = new QueryParser("content", analyser);
var query = parser.parse("*:*");
System.out.println(query);
System.out.println(query.getClass());
------------
*:*
class org.apache.lucene.search.MatchAllDocsQuery
短语查询 PhraseQuery
QueryParser 使用双引号来表示短语查询,默认的 slop 是零。
var parser = new QueryParser("content", analyser);
var query = parser.parse("\"动物世界\"");
System.out.println(query);
System.out.println(query.getClass());
-------------
content:"动物 世界"
class org.apache.lucene.search.PhraseQuery
但是如果将「动物世界」换成「北京大学」,结果却变成了简单的关键词查询 TermQuery。
var parser = new QueryParser("content", analyser);
var query = parser.parse("\"动物世界\"");
System.out.println(query);
System.out.println(query.getClass());
------------
content:北京大学
class org.apache.lucene.search.TermQuery
这是因为分词器会对双引号中的内容进行分词,如果它是原子的就是 TermQuery,否则就是短语查询。那如何给短语设置我们期望的 slop 参数呢?答案是使用波浪号 ~。
var query = parser.parse("\"动物世界\"~5");
----------
content:"动物 世界"~5
模糊查询 FuzzyQuery
模糊查询也使用波浪号,但是不需要双引号了,如果希望设定模糊相似度(模糊因子),可以在波浪号后面增加一个浮点数,默认的模糊因子我也不知道是多少,但是我从代码中了解到默认的编辑距离是 2。如果设置了模糊因子 factor,编辑距离将会是 min((1-factor)*Length, 2),无论如何编辑距离也不会超过 2。
var parser = new QueryParser("title", analyser);
var query = parser.parse("动物世界~0.5");
System.out.println(query);
System.out.println(query.getClass());
-----------
title:动物世界~2
class org.apache.lucene.search.FuzzyQuery
括号与 AND、OR
为了支持更加复杂的组合逻辑,ParseQuery 提供了括号、AND、OR、NOT 这样的组合操作符,适当使用它们可以使得查询表达式逻辑更加清晰。
var parser = new QueryParser("content", analyser);
var query = parser.parse("(北京* OR 清华) AND 大学");
System.out.println(query);
-------------
+(title:北京* title:清华) +title:大学
var analyser = new HanLPAnalyzer();
var parser = new QueryParser("content", analyser);
var query = parser.parse("(北京* OR 清华) AND NOT 小学");
System.out.println(query);
-----------
+(content:北京 content:清华) -content:小学
字段选择
我们在构造 QueryParser 时会传入一个目标字段名称,其实这个字段名称只是默认字段名称,如果表达式中没有指定字段名称,那么就会使用这个默认字段名称。如果不想使用默认字段名称,可以在表达式中使用字段限定符。
var parser = new QueryParser("content", analyser);
var query = parser.parse("(title:北京* OR title:清华) AND 大学");
System.out.println(query);
----------
+(title:北京* title:清华) +content:大学
如此该查询匹配的就是个混合字段,会使用到多个倒排索引联合匹配、评分和排序。
字段加权
如果我希望在标题出现「北京大学」或者内容出现「北京大学」都可以,但是希望标题中出现的评分排序要靠前,那么可以对个别字段进行加权。下面我们来对比一下加权前后的效果
var parser = new QueryParser("content", analyser);
var query = parser.parse("title:科幻 OR 科幻");
var parser = new QueryParser("content", analyser);
var query = parser.parse("title:科幻^5.0 OR 科幻");
先看加权前
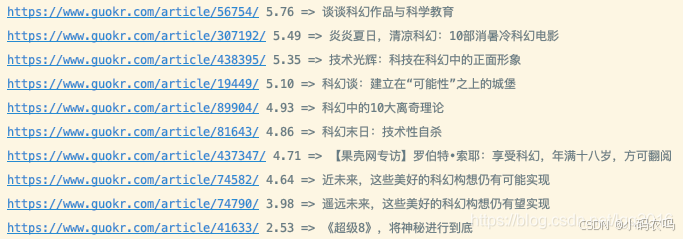
再看加权后
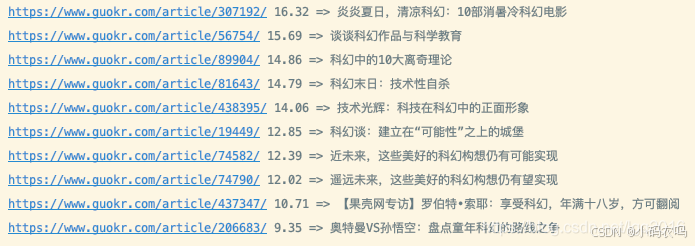
- 转载于https://blog.youkuaiyun.com/lgq2016/article/details/106223210



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









