



 本文深入探讨了链式存储结构的特点,包括单向链表、循环链表和双向链表的组成、基本操作及其实现代码。同时,文章还讨论了链表在数据访问和存储上的优势与不足。
本文深入探讨了链式存储结构的特点,包括单向链表、循环链表和双向链表的组成、基本操作及其实现代码。同时,文章还讨论了链表在数据访问和存储上的优势与不足。
引言
链式存储结构指用一组任意的存储单元(可以连续,也可以不连续)存储线性表中的数据元素,而数据元素之间的逻辑关系由存储结点的指针域来确定。
特点
1、 线性表中的数据元素在存储单元中的存放顺序与逻辑顺序不一定一致;
2、 访问数据元素时,只能由头指针进入链表,并通过结点的指针域向后扫描其余结点,这样访问不同数据元素所花的时间是不相等的,具有这种特点的存取方式被称为顺序存取方式。
单向链表
组成
- 链表的元素——结点

- 单向链表的组成
链表(link):由结点组成的表。
头指针(head):指向链表中第一个结点的指针。
头结点:为了方便操作,在头指针和头节点之间设置的结点
首元结点:第一个节点(头结点后第一个节点)。 - 存储示意图
线性表

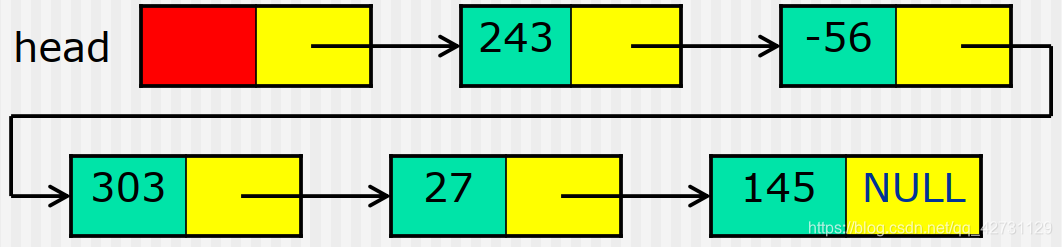
描述
结点类型
typedef struct llnode {
ElemType data; //对应上图的数据域
struct llnode *next; //对应上图的指针域
} llnode;
链表类型
typedef struct LinkedList{
llnode* head; //头指针
} LinkedList;
基本操作
- 链式线性表初始化
int initiate(LinkedList LL) {
//为头结点分配存储单元
LL.head=(*llnode)malloc(sizeof(llnode));
if (LL.head) {
LL.head->next=null;
return OK;
} else {
return ERROR ;
}
}
- 销毁链式线性表
void destroy(LinkedList LL) {
// 为头结点分配存储单元
llnode* p=LL.head;
// 依次删除链表中的所有结点
while(p) {
LL.head=p->next;
free(p);
p=LL.head;
}
}
- 求链式线性表LL的长度
int length(LinkedList LL) {
int len=0;
// 指向链表中的第一个元素
llnode* p=LL.head->next;
while(p) {
len++;
p=p->next;
}
return(len);
}
- 返回线性链表LL中第idx个数据元素的值
ElemType get(LinkedList LL, int idx) {
int j=0;
// 指向链表中的第一个元素
llnode* p=LL.head->next;
while(p && j<idx) {
p=p->next;
j++;
}
if(!p||j>idx)
return ERROR //第idx个元素不存在
return p->data;
}
- 在链式线性表中检索值为elem的数据元素
llnode* locate(LinkedList LL, ElemType elem) {
llnode* p=LL.head->next;
// 寻找满足条件的结点
while(p && p->data!=elem){
p=p->next;
}
if(p && p->data==elem)
return p;
else return NULL;
}
- 返回链表LL中结点elem的直接前驱结点
llnode* prior(LinkedList LL, ElemType elem) {
llnode* p=LL.head->next;
llnode* q=LL.head;
// 第一个结点无前驱
if (p->data==elem)
return NULL;
while(p && p->data!=elem){
q=p;
p=p->next;
}
if (p&&p->data==elem)
return q;
else return NULL;
}
- 插入操作
插入数据元素372后的线性表
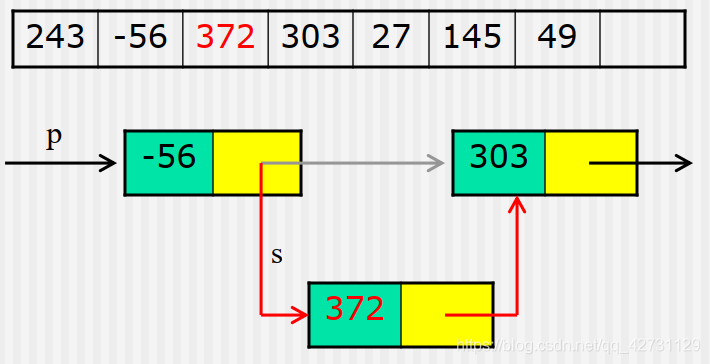
在链表LL中第idx个数据元素之前插入数据元素elem
int insert(LinkedList LL, int idx, ElemType elem){
llnode* p, s;
int j;
// 开辟新结点空间
s=(llnode*)malloc(sizeof(llnode));
if (s==NULL) return ERROR;
s->data=elem;
if (idx<0 || i>length(LL)) return ERROR;
// 寻找第i-1个结点
for (p=LL.head,j=0;p&&j<idx-1;p=p->next,j++);
//将新结点插入到链表中
s->next=p->next; p->next=s;
return OK;
}
- 删除操作
删除数据元素303后的线性表
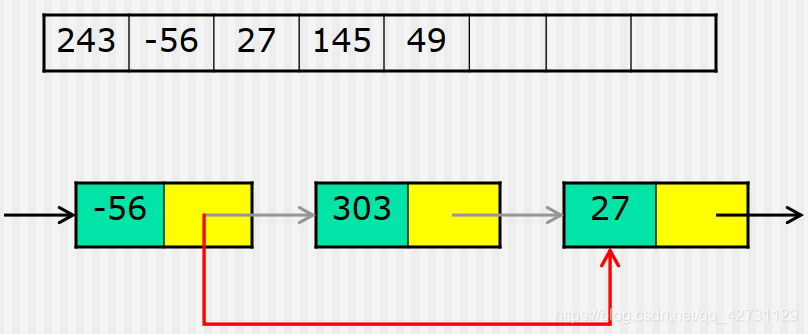
删除链表LL中的第idx个数据元素,并返回其值
ElemType delete(LinkedList LL, int idx) {
llnode* p, s;
int j;
if (idx<0 || idx>length(LL)) return ERROR;
// 寻找第i-1个结点
for(p=LL.head,j=0;p && j<idx-1;p=p->next,j++);
// 用s指向将要删除的结点
s=p->next;
ElemType elem=s->data;
p->next=s->next;
free(s);
return elem;
}
单链表的不足
- 链式存储结构空间利用率不高;
- 单链表只能顺时针方向由链头向链尾方向扫描存储和查找元素;
- 对单链表来书,查找前驱点比较困难;
循环链表
结构
- 将链表中最后一个结点的next域指向头结点;
- 实现循环链表的类型定义与单链表完全相同,它的所有操作也都与单链表类似,只是判断链表结束的条件有所不同;
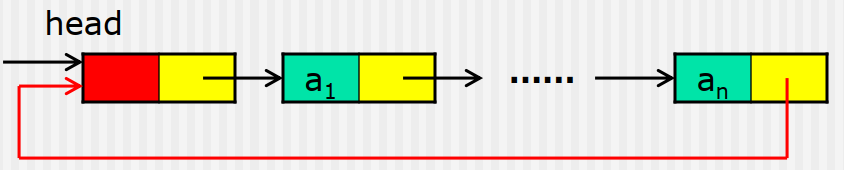
循环链表检索
在循环链表CL中检索值为elem的数据元素
node* locate(LinkedList CL, ElemType elem) {
llnode* p;
p=CL.head->next;
// 在循环链表中顺序检索
while(p!=CL.head && p->data!=elem)
p=p->next;
if (p!=CL.head)
return p;
else return NULL ;
}
双向链表
结构
双向链表中,每个结点有两个指针域:一个指向后继结点,另一个指向前驱结点;
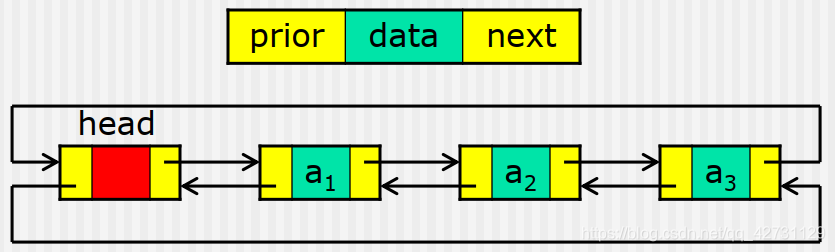
描述
结点类型
typedef struct dpnode {
ElemType data;
struct dpnode* prior, next;
} dpnode;
链表类型
typedef struct {
dpnode* head;
} DPLinkedList;

















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









