



点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者丨Ocean@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/9630622286
编辑丨极市平台
极市导读
本文提出了一个利用大型语言模型(LLM)根据文章的标题和摘要来预测其未来学术影响力的新方法,该方法可以帮助自动科研系统以及个人研究者从海量新发表论文中筛选潜在高质量论文。
题目:《From Words to Worth: Newborn Article Impact Prediction with LLM》
作者:赵鹏海, 邢清画, 窦楷然, 田晋宇, 邰颖, 杨健, 程明明, 李翔*
机构:南开大学VCIP实验室、南京大学
数据集代码主页地址
https://sway.cloud.microsoft/KOH09sPR21Ubojbc
arXiv原文
https://arxiv.org/abs/2408.03934
HuggingFace在线Demo (免费)
https://huggingface.co/spaces/ssocean/Newborn_Article_Impact_Predict
TLDR;我们发现微调LLM并引导它来根据题目和摘要预测一个0-1之间的文献计量学指标是很有应用前景的。实验结果表明,微调后的LLM可以准确发现潜在高影响力的论文(NDCG@20>0.9)。我们的方法可以帮助自动科研系统以及个人研究者从海量新发表论文中筛选潜在高质量论文。
大家可能对“文章影响力预测”任务比较陌生,但是想必各位对“学术成果评定”都再熟悉不过了。学术成果评定主要依赖的是一篇文章历史的统计数据,从影响力、潜在的社会或经济贡献等方面评定一篇学术论文的价值。与成果评定评估已经存在的事实相反,论文影响力预测专注于预测一篇论文未来的学术影响力。
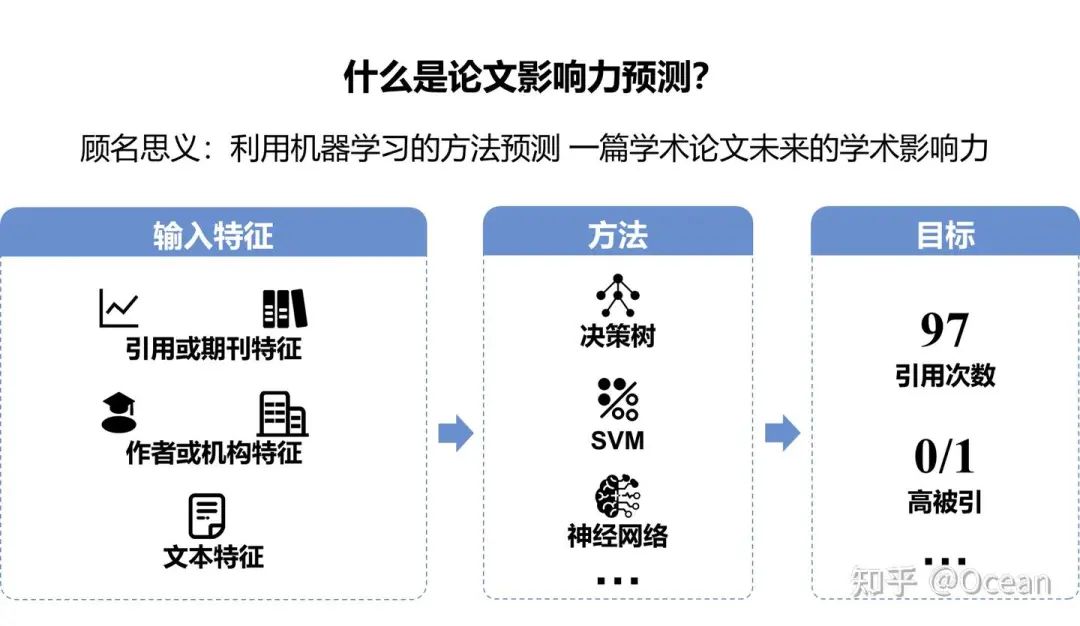
自论文影响力预测任务诞生的那一刻起,它就成为了大型学术机构的“专利”。这些大型机构可能会用它来进行调拨科研经费、资助人才等等我们想象不到的事。在以前,这件事确实和普通科研人不能说唇齿相依,只能说毫不相干!但随着科研论文发文量的爆炸式增长以及各种新兴的LLM+应用的诞生(如AI4S、自动综述系统、自动科研系统等等),能够用于鉴别重要文献的影响力预测任务变得愈发重要。
这就像以前视频直播是电视台的专利,但随着移动互联网和短视频平台进入千家万户,现在想当主播的普通人也要开始学习布置机位、搭建绿布、调节补光等专业技能。

既然文章影响力预测任务变得愈发重要,以往的方法能否派上用场呢?很遗憾,不太行。
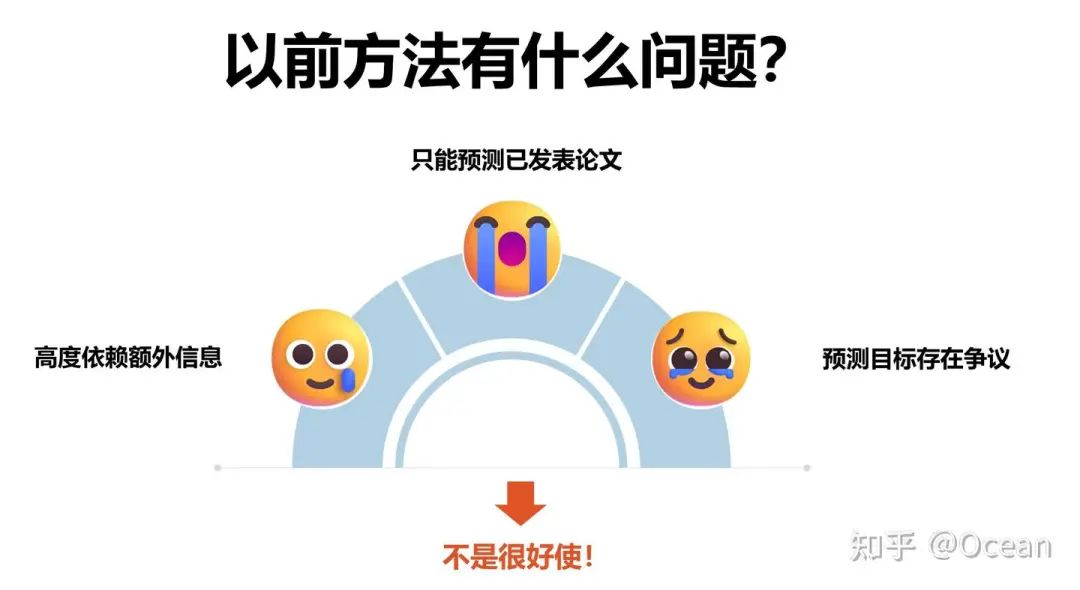
图1谈到了以往的大多数方法高度依赖文章的外部历史信息,但这些信息其实对个人研究者甚至是机构来说,都是很难获取的(比如如何准确获取一篇文章第一个月被引的次数?如何拿到双盲论文的作者信息和发文机构? 这是能说的么)。另外,有些信息会导致预测任务存在信息泄露的风险。比如,期刊影响因子其实就是一本期刊的平均引用次数。拿期刊影响因子作为输入,去预测一篇被该期刊收录的某篇文章未来的引用次数存在一定的信息泄露可能。更别提有些工作想要预测未来三年的引用情况,要先拿到过往十年的引用数据。过度依赖外部信息导致了以往方法大多只能预测已经发表了一段时间、甚至是已经被收录的文章影响力,而对那些刚刚新发表的论文影响力预测几乎是束手无策。
除了高度依赖外部信息及只能预测已发表论文,这些预测目标本身也存在争议。大家知道,引用次数随领域波动是很大的。就拿图4为例,AI领域顶刊TPAMI的影响因子26.7,不到Nature的1/2,医学顶刊CA的10/1。大领域是如此,小领域也存在类似的现象:专注于通用目标检测的论文,势必会比深耕甲骨文OCR的收获更多的注意(引用次数)。这就导致对领域贡献相同的论文(粗浅的认为质量完全一样的论文),可能就因为领域的不同,引用次数有数倍甚至数十倍的差异。这样巨大的差异导致算法模型在学习过程中也会产生较大的困惑,在多领域联合训练时梯度波动较大(因此,也有方法一个小领域训一个模型,最后在推理时根据领域选择对应的模型)。

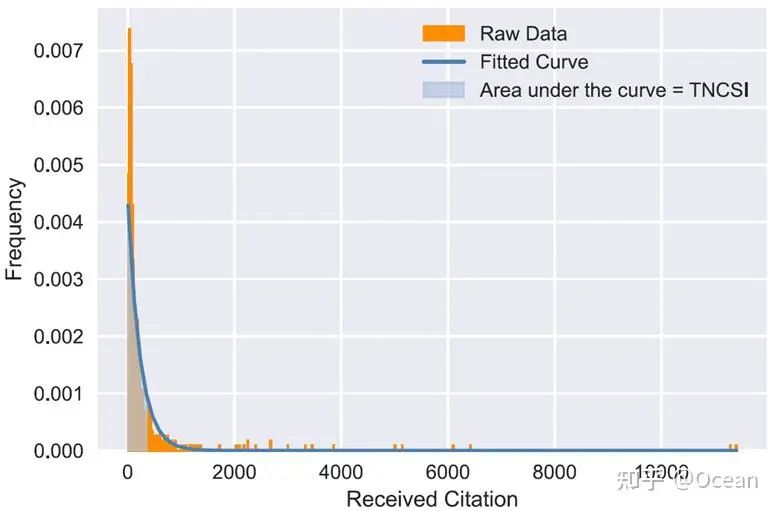
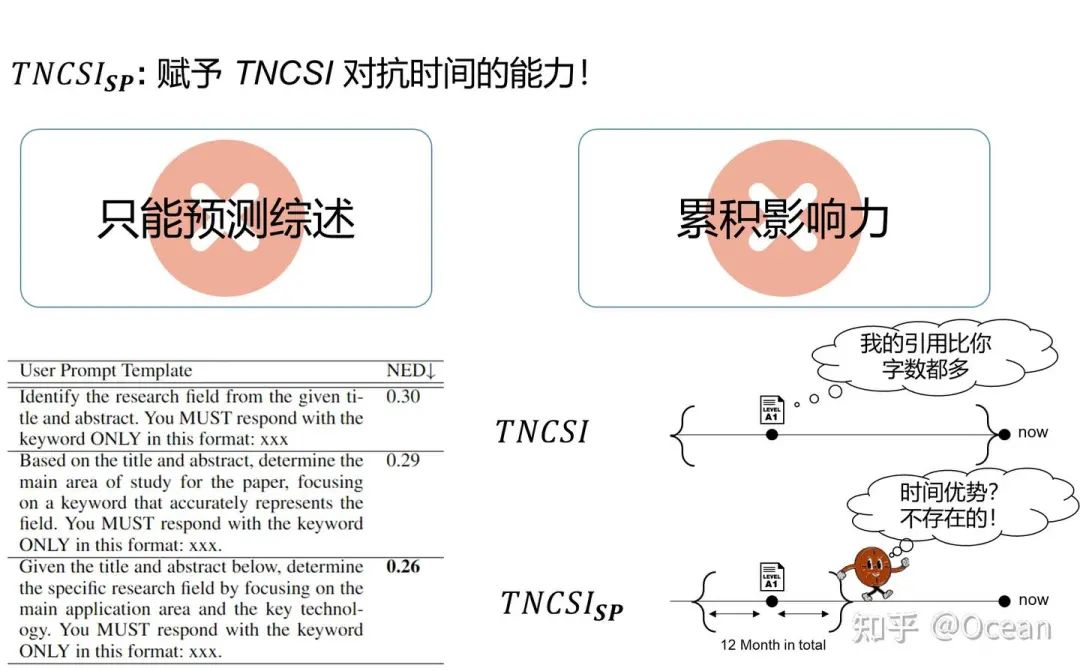
那既然引用次数用不成了,有没有什么能支持跨领域对比的指标呢,而且最好还带有神经网络最喜欢的数值归一化性质的?这样就能解决引用次数随领域波动导致训练不稳定的问题了。还真有,那就是带有超越指数性质的TNCSI!好的,我不装了,这是我们之前的一个工作,但当时该指标是用来评价文献综述的累积影响力的。简单来说,它是由LLM确定的“同领域”内1000篇论文引用分布拟合出的概率密度函数的积分所得出的(跨领域对比的问题解决了!)。如图5所示,TNCSI就是蓝色曲线下方指定区间上的面积。由于是概率密度函数的积分,TNCSI的取值范围天然位于0-1之间(神经网络最喜欢的数值归一化也来了!)。
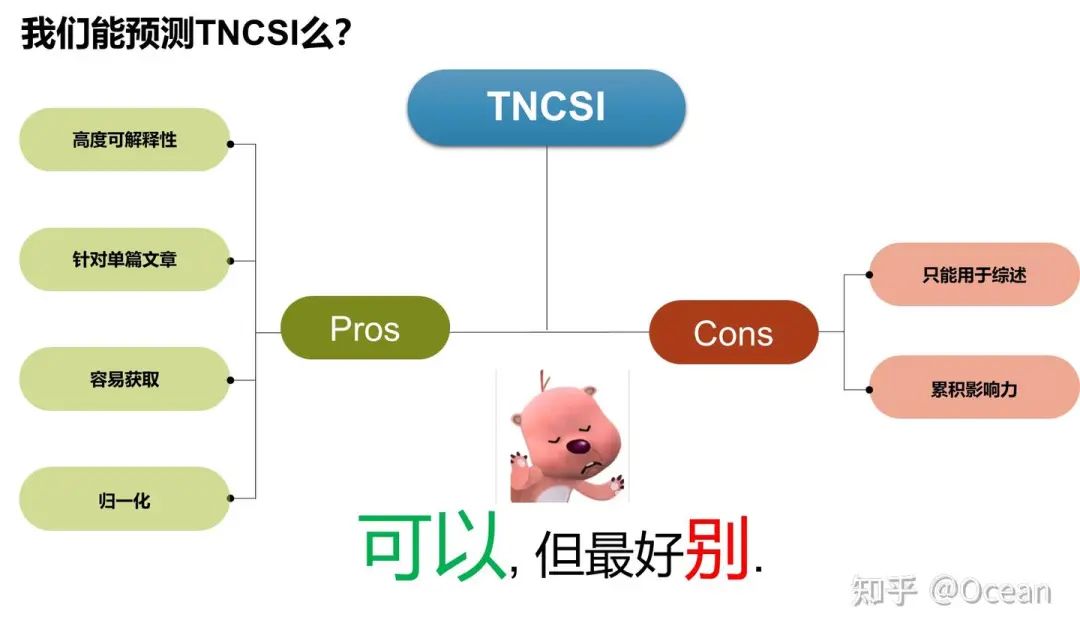
既然跨领域和归一化的问题都解决了,我们用TNCSI来进行预测如何?我们要先分析下TNCSI的优缺点。首先,TNCSI是一个高度可解释的、数值归一化的指标,它是一篇论文的引用次数超过同领域其它论文的概率。另外,与引用次数相同,TNCSI是一个可以评价单篇文章的指标(莱顿宣言明确指出,不应使用期刊级别的评价指标例如影响因子来评价单篇文章)。这些性质对回归任务来说真的是非常诱人!但是,由于TNCSI服务对象不同(我们那篇是针对综述设计的),它不能直接判断普通文章的研究领域。此外,TNCSI在设计之处旨在对齐引用次数,着重考虑的是累积影响力。但对文章影响力预测任务来说,使用累计影响力会导致较早发表文献由于时间优势积累更大的影响力,对新发表论文造成“倚老卖老”的不利局面。
遇山开路,遇水架桥!我们先咔咔改了早先提取综述研究领域的prompt,使其现在可以判断普通论文的领域关键字(从而检索相关的1000篇文章)。随后,作者团队又去时间管理局里转了一圈,让Loki把TNCSI踢出神圣时间线,赋予其抵御时间的能力(❌)。随后,我们将TNCSI统计全时间段论文的引用次数分布改为了仅统计该论文发表前后半年共计一年内论文的引用分布情况,从而赋予其抵御时间的能力(✔️)。
好,GT的计算方式已经非常明确(如图8所示)。事不宜迟,我们哐哐造了12000+条数据,每一条数据大概是这样-->(题目,摘要,TNCSI_SP)。这12000条数据来自所arXiv的cs.AI cs.CL cs.CV三大领域,横跨2020、2021、2022三年,整体数据分布是均匀的(每一个区间上的样本量基本相同)。

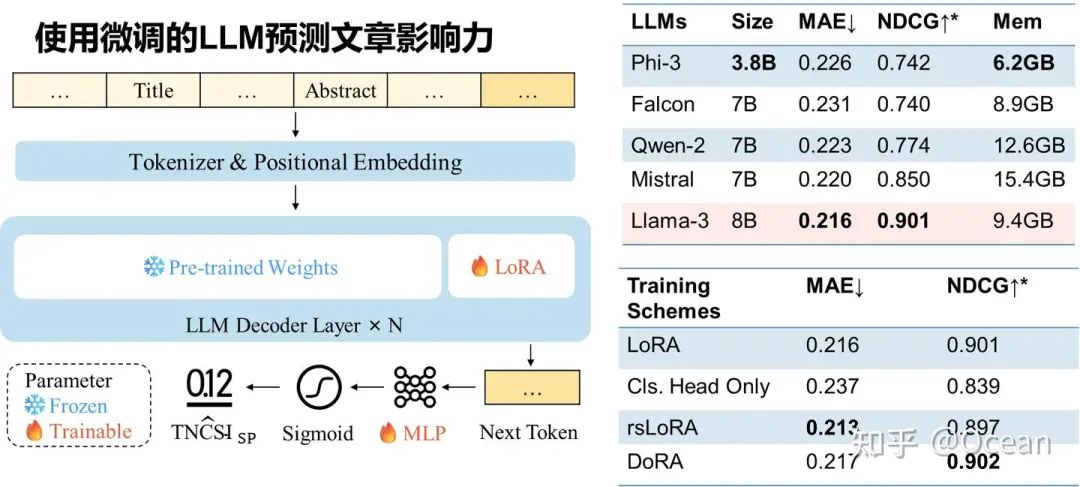
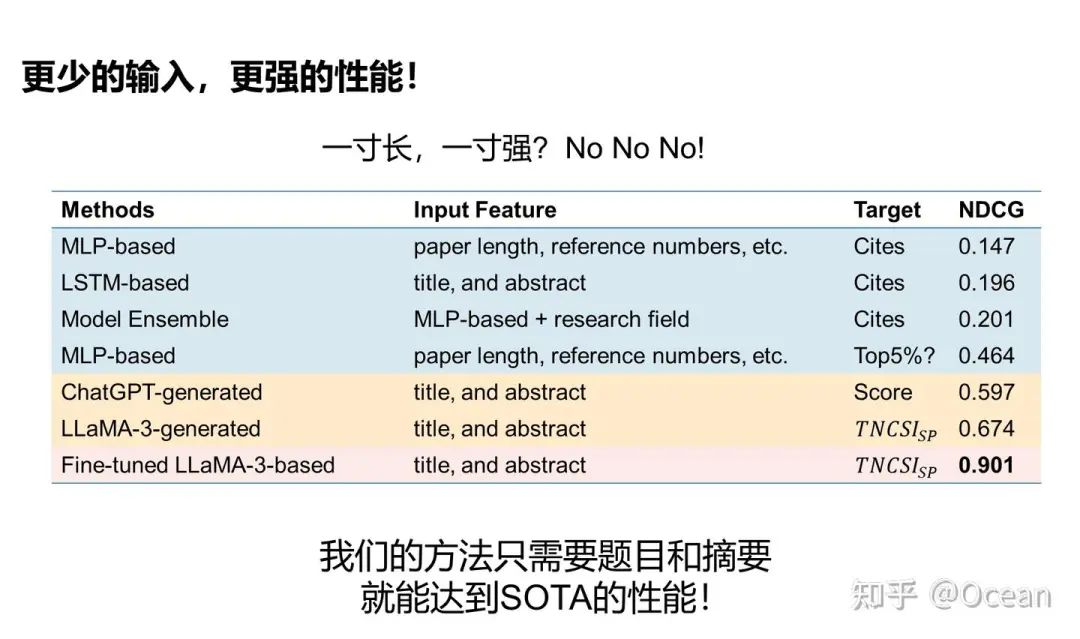
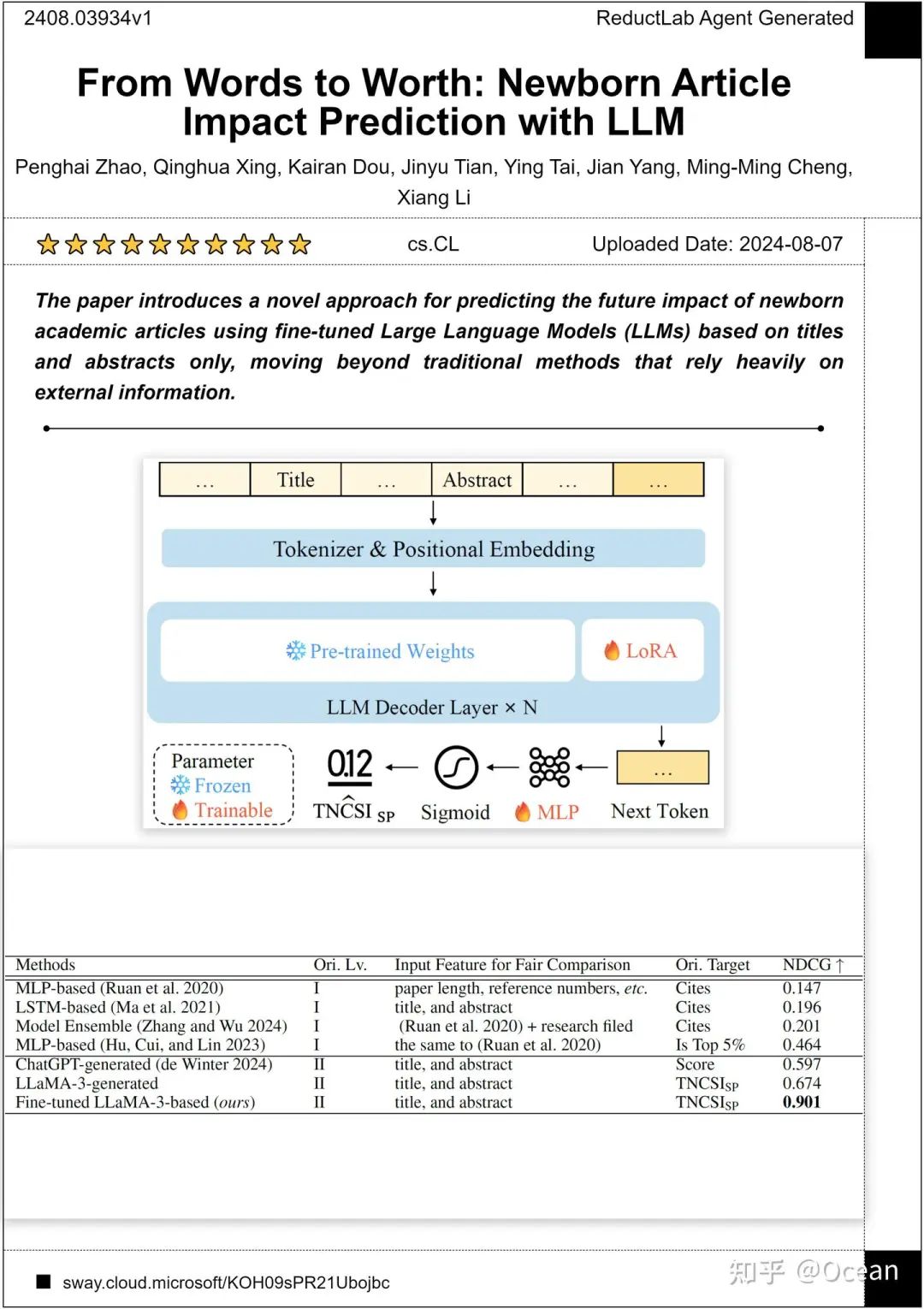
有了数据集,现在终于到正头戏了——使用LLM来预测文章影响力!! 长话短说,我们魔改了下LLM的工作方式(如图9所示),把原本逐token逐token生成的范式改为了只生成第一个token,随后把这个token送入MLP并将输出的logits进行sigmoid归一化(闭环了闭环了!)。我们发现LLaMA-3的效果最好,在一个预测0-1之间的数值回归任务中,MAE仅为0.216,NDCG更是干到了0.901!(NDCG\in[0,1] 越接近1表明发现高影响力论文的能力越强)。与早先方法的对比(图10)表明我们的方法在仅依靠题目和摘要的情况下,还能有着遥(cou)遥(huo)领(neng)先(yong)的性能表现!
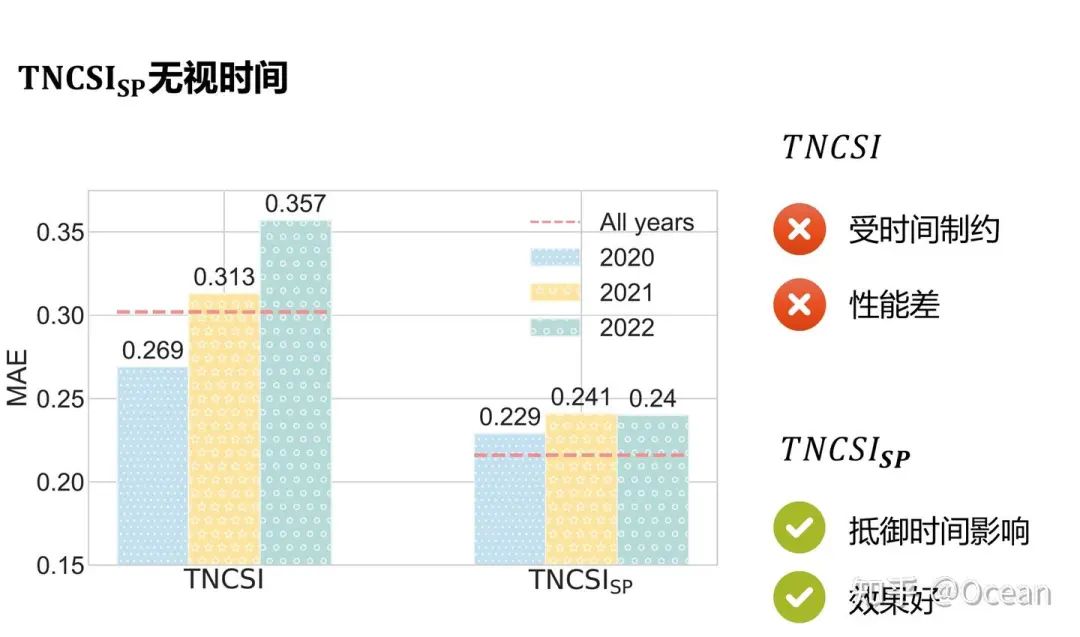
我们还设计了一个有趣的小实验,即分别使用不同年份的数据进行训练。如图11所示,我们发现在使用TNCSI作为回归指标时,不同年份之间的MAE方差很大,导致最终预测效果较差。而使用TNCSI_SP作为预测指标时,不同年份之间的MAE波动很小,整体预测性能也更好。
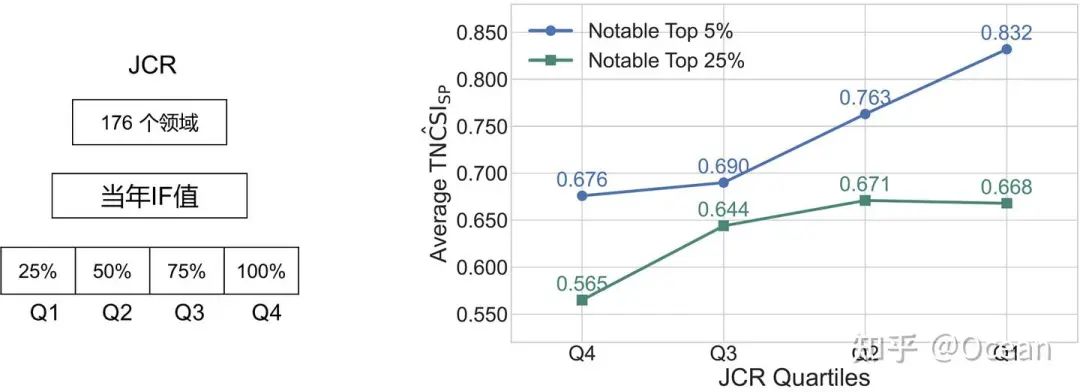
最后,为了验证我们方法在真实应用中的有效性,我们找了500+篇2024.1.1后年新发表的且已被不同JCR分区期刊收录的文章(这些文章极大概率不在LLaMA-3的预训练语料中,不存在信息泄露风险),并使用所提出的方法预测其影响力。实验结果表明,等级更高的分区,往往有着更高的Top5% & Top25%预测影响力,符合常识认知。
最后我们还是想说一下,不要试图通过虚假声称性能(比如没有达到SOTA但是声称SOTA)等方式来试图提高指标预测分数,让我们共同维护一个良好的学术环境!
不过呢,我们也确实清楚,预测指标肯定会被用来作为indicator,来引导题目和摘要的撰写。对于这种情况,我们的建议是:(1)不要被指标牵着鼻子走,不建议为了“刷分”,把原版题目、摘要改的面目全非。(2)理想区间是在0.60-0.85之间(3)尽量不要优化题目,只针对摘要进行优化。摘要优化时,只进行语义上的优化(换词、优化表达等);(4)当摘要优化到第一次分数下降时,就停止“分数导向的优化”(意思就是不要再看分来优化了)。如果分数不管怎么优化都不高于0.60,或许你应当完全重写摘要(纯理论分析型论文除外!)。

最后,插播一个推广,如果大家有追踪每日最新arXiv文章的需求(目前仅限CV领域),不妨关注我们的arXiv每日推广项目(B站、微信公众号、小红书同名):
"减论"系统目前就使用了这样的技术,它可以每天从上百篇最新arXiv论文中层层筛选,并利用Agent、RAG、OCR等多种技术,为您呈现当天的甄选文献,助力您保持学术长青!
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









