



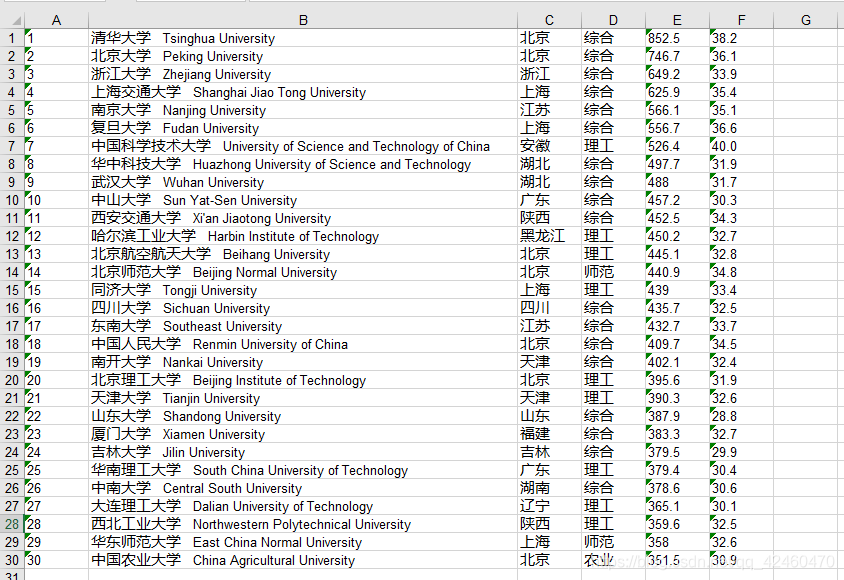
爬一个大学排行。首先获取页面代码,转换为bs4格式,获取td标签文本,遍历出来再写入excel(向下取整,追加excel)
import requests
from bs4 import BeautifulSoup
import xlwt
import math
import xlrd
from xlutils.copy import copy
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
url='https://www.shanghairanking.cn/rankings/bcur/2020'
html = requests.get(url, headers=headers)
html.encoding='utf-8'
html=html.text
soup = BeautifulSoup(html, 'html.parser')
tdTag=soup.find_all('td')
for i in range(len(tdTag)):
print(tdTag[i].get_text().strip(),end=' ')
xls=xlrd.open_workbook(r'Excel_test.xls',formatting_info=True)
xlsc=copy(xls)
shtc=xlsc.get_sheet(0)
a=i/6
a=math.floor(a)
b=i%6
shtc.write(a, b, tdTag[i].get_text().strip())
xlsc.save(r'Excel_test.xls')
if (i+1)%6==0:
print('\r')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









