




 本文通过Python的正则表达式和urllib库,详细介绍了如何从郑州大学官网爬取特定信息,包括超链接、标签及关于校长刘炯天的相关资讯。并展示了如何进一步爬取二级页面内容。
本文通过Python的正则表达式和urllib库,详细介绍了如何从郑州大学官网爬取特定信息,包括超链接、标签及关于校长刘炯天的相关资讯。并展示了如何进一步爬取二级页面内容。
题目描述

用到的知识点:正则表达式,爬虫相关的简单知识.
python代码
import urllib.request
import re
#入口网址
url = 'http://www.zzu.edu.cn/'
#进入链接地址进行读取
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
start = data.find(r'<div class="zzj_5a_2b1" id="z_tt1">')#开始位置
end = data.find(r'<div class="zzj_9" id="banner8">')#结束位置
#捕获的内容
content=data[start:end]
#爬取超链接标签
pattern = re.compile(r'<a href=(.*?)>(.*?)</a>')
links = re.findall(pattern,content)
print(len(links))
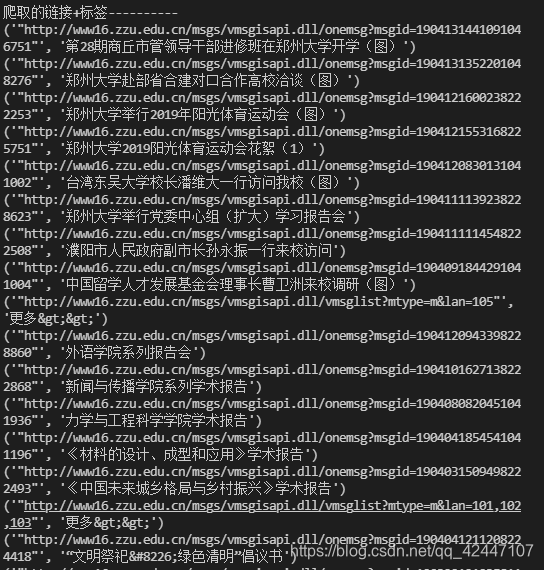
print("爬取的链接+标签----------")
for link in links:
'''打印出爬取的超链接'''
print(link)
#在郑州大学官网上爬取有关亲爱的刘炯天校长的有关信息 可以指定关键字,修改即可
pattern1=re.compile('.*?刘炯天.*?')
presidents = re.findall(pattern1,content)
print(len(presidents))
print("爬取的关于刘炯天的信息----------")
for president in presidents:
'''打印筛选出关键字‘刘炯天’的信息'''
print(president)
#匹配筛选出关键字后的超链接标签
pattern2=re.compile(r'.*?href="(.*)".*?')
url_2=re.findall(pattern2,presidents[1])[0]
#刚刚获取的第二层入口地址,url_2
print("URL="+url_2)
url1 = url_2
#进入链接地址进行读取
data1 = urllib.request.urlopen(url1).read()
data1 = data1.decode('UTF-8')
start1 = data1.find(r'<div class="zzj_5">')#开始位置
end1 = data1.find(r'<div class="zzj_6">')#结束位置
#捕获的内容
content1 = data1[start1:end1]
print("爬取的关于刘炯天的新闻内容----------")
print(content1)
运行结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









