



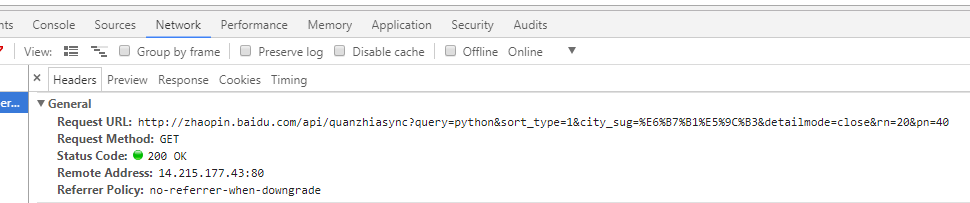
百度招聘用的是ajax来动态加载不同页面,需要我们去查找消息头来找到其实际发起请求的url
# -*- coding: utf-8 -*-
"""
Created on Wed May 30 17:35:31 2018
@author: phl
"""
import requests
import json
def crawl_one_page(url, headers, f):
response = requests.get(url, headers)
#print(type(response.text))
result = (json.loads(response.text))
for each in result['data']['main']["data"]['disp_data']:
commonname = each.get('commonname', '')
description = each.get('description', '')
ori_experience = each.get('ori_experience', '')
salary = each.get('salary', '')
ori_jobfirstclass = each.get('ori_jobfirstclass', '')
data = "公司名:" + commonname + '\n'
data += "职位要求:" + description + '\n'
data += "工作经验:" + ori_experience + '\n'
data += "工资" + salary + '\n'
data += "工作类型:" + ori_jobfirstclass + '\n'
data += '====================================================\n'
f.write(data)
f = open('baiduzhaopin.txt', 'w', encoding='utf-8' )
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"X-Requested-With":"XMLHttpRequest", # 可以处理Ajax
"Accept":"application/json, text/javascript, */*; q=0.01",# 可以接收json数据
}
for i in range(38):
url = 'http://zhaopin.baidu.com/api/quanzhiasync?query=python&sort_type=1&city_sug=广州&detailmode=close&rn=20&pn=' + str(i*20)
crawl_one_page(url, headers, f)
f.close()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









