




 本文介绍了Python语音识别的基本原理和实践,包括选择语音识别包、处理音频文件、应对噪音问题以及使用麦克风进行实时识别。重点讲解了SpeechRecognition库与Google Web Speech API的结合使用,以及如何通过adjust_for_ambient_noise函数优化识别效果。
本文介绍了Python语音识别的基本原理和实践,包括选择语音识别包、处理音频文件、应对噪音问题以及使用麦克风进行实时识别。重点讲解了SpeechRecognition库与Google Web Speech API的结合使用,以及如何通过adjust_for_ambient_noise函数优化识别效果。


▌语言识别工作原理概述
语音识别源于 20 世纪 50 年代早期在贝尔实验室所做的研究。早期语音识别系统仅能识别单个讲话者以及只有约十几个单词的词汇量。现代语音识别系统已经取得了很大进步,可以识别多个讲话者,并且拥有识别多种语言的庞大词汇表。

▌选择 Python 语音识别包
PyPI中有一些现成的语音识别软件包。其中包括:
apiai
google-cloud-speech
pocketsphinx
SpeechRcognition
watson-developer-cloud
wit

$ pip install SpeechRecognition
安装完成后请打开解释器窗口并输入以下内容来验证安装:
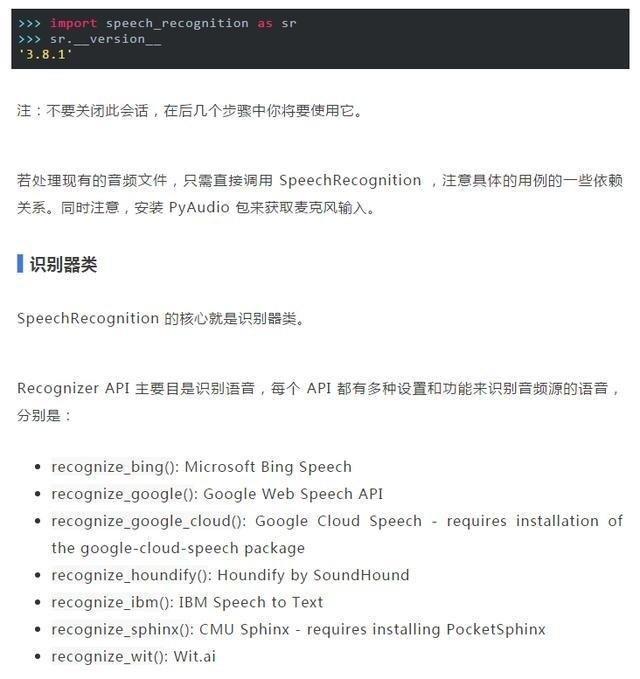
以上七个中只有 recognition_
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1907
1907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









