




 本文深入探讨了iSCSI技术如何实现SAN网络,提高磁盘空间利用率。介绍了iSCSI服务器与客户端的工作原理,包括红帽企业版Linux(RHCE)环境下iSCSI的配置与使用。此外,文章还涵盖了系统调用、用户空间与内核空间的交互,以及不同编程语言在系统级应用和应用程序开发中的角色。
本文深入探讨了iSCSI技术如何实现SAN网络,提高磁盘空间利用率。介绍了iSCSI服务器与客户端的工作原理,包括红帽企业版Linux(RHCE)环境下iSCSI的配置与使用。此外,文章还涵盖了系统调用、用户空间与内核空间的交互,以及不同编程语言在系统级应用和应用程序开发中的角色。
1byte=8bit
san
iscsi 网络实现 san
iscsi服务器,提高磁盘空间
iscsi 客户端:
rhce 红帽

app1 App2
library 软件模块. lib
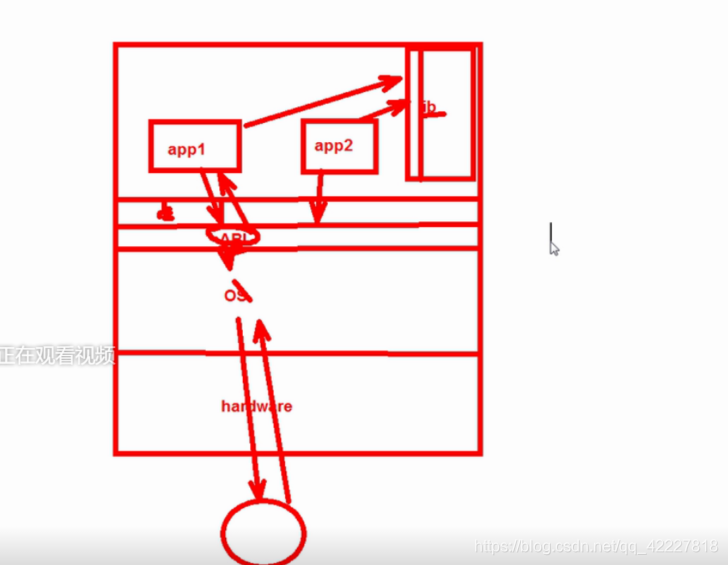
posix
strace 可以查看 system call
ltrace library 这两个软件是查看软件执行某部分异常(需要懂开发)
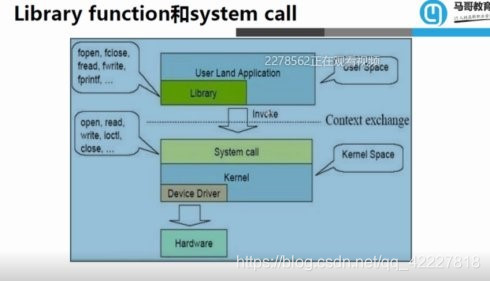
user land application:用户土地应用程序
library
user space 用户空
invoke 调用
system call 系统调用
kernel 内核
device driver 设备驱动程序
contact exchange 上下交换
hardware 硬件
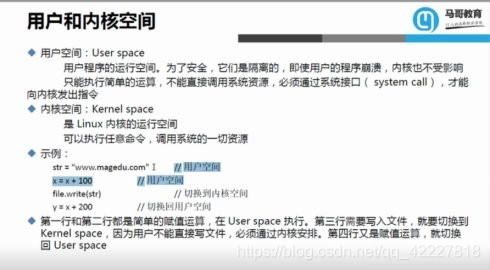
用户和内核空间
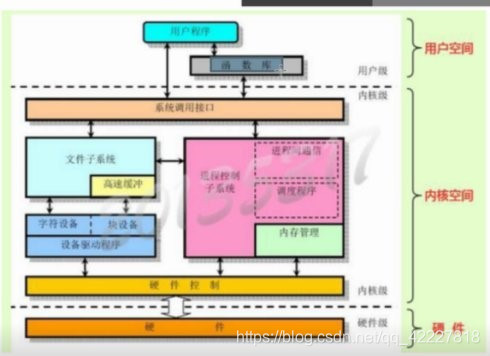
编程语言
低级语言
机器语言:0和1
汇编语言:和机器语言--对应,与硬件相关 的特有代码,驱动程序开发
中级语言:c
系统级应用,驱动程序
高级语言:java,object-c,c#,python,php,go
应用程序开发


















 89
89

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









