




3.1 安装selenium并学习
-
安装selenium并学习。
-
使用selenium模拟登陆QQ邮箱。
-
qq邮箱直通点:https://mail.qq.com/ 。
-
参考资料:https://blog.youkuaiyun.com/weixin_42937385/article/details/88150379
3.2 学习IP相关知识
-
学习什么是IP,为什么会出现IP被封,如何应对IP被封的问题。
-
抓取西刺代理,并构建自己的代理池。
-
西刺直通点:https://www.xicidaili.com/ 。
-
参考资料:https://blog.youkuaiyun.com/weixin_43720396/article/details/88218204
什么是Selenium
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
selenium基本使用
用python写爬虫的时候,主要用的是selenium的Webdriver,我们可以通过下面的方式先看看Selenium.Webdriver支持哪些浏览器
列举一下常用的查找元素方法:
find_element_by_name
find_element_by_id
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
import os,sys,re
from bs4 import BeautifulSoup
import requests
from lxml import etree
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get("http://mail.qq.com/")
browser.switch_to.frame("login_frame")
elem_user = browser.find_element_by_name("u")
elem_user.send_keys("XXXXXX@qq.com")
elem_pwd = browser.find_element_by_name("p")
elem_pwd.send_keys("*******")
elem_but = browser.find_element_by_id("login_button")
elem_but.click()
time.sleep(5)IP地址:
互联网协议地址(Internet Protocol Address,又译为网际协议地址),缩写为IP地址(IP Address),是分配给用户上网使用的网际协议(IP)的设备的数字标签。常见的IP 地址分为IPv4与IPv6两大类,但是也有其他不常用的小分类。
IP地址由32位二进制数组成,为便于使用,常以XXX.XXX.XXX.XXX形式表现,每组XXX代表小于或等于255的10进制数。例如维基媒体的一个IP地址是208.80.152.2。地址可分为A、B、C、D、E五大类,其中E类属于特殊保留地址。
随着互联网的快速成长,IPv4的42亿个地址的分配最终于2011年2月3日用尽。相应的科研组织已研究出128位的IPv6,其IP地址数量最高可达3.402823669 × 1038个,届时每个人家居中的每件电器,每件对象,甚至地球上每一粒沙子都可以拥有自己的IP地址。
在A类、B类、C类IP地址中,如果主机号是全1,那么这个地址为直接广播地址,它是用来使路由器将一个分组以广播形式发送给特定网络上的所有主机。32位全为1的IP地址“255.255.255.255”为受限广播地址(“limited broadcast” destination address),用来将一个分组以广播方式发送给本网络中的所有主机,路由器则阻挡该分组通过,将其广播功能限制在本网内部。
IP封锁:
IP封锁是指防火墙维护一张IP黑名单,一旦发现发往黑名单中地址的请求数据包,就直接将其丢弃,这将导致源主机得不到目标主机的及时响应而引发超时,从而达到屏蔽对目标主机的访问的目的。
ip被封的原因:
a.服务器在国内被封,无法正常访问。
b.服务商更换服务器
c.当计算机或系统受到外部攻击时,管理员可以通过屏蔽攻击源IP地址来抵御攻击。通过防火墙和路由器配置,可以封锁某个IP,禁止与其连接。
应对ip封锁是方法:http://www.cnblogs.com/JohnABC/p/5275109.html
a.伪造User-Agent
在请求头中把User-Agent设置成浏览器中的User-Agent。来伪造浏览器访问。
b.伪造cookies
若从浏览器中可以正常访问一个页面,则可以将浏览器中的cookies复制过来使用。
1.查看http请求的header信息
https://dashidan.com/article/html/faq/18.html
2.报错: Can't connect to HTTPS URL because the SSL module is not available
pip install -U spacy
python -m spacy download en
import requests
from bs4 import BeautifulSoup
import xlwt
from xlrd import open_workbook
from telnetlib import Telnet # 这是用来验证IP是否可用
class XiciProxy():
def __init__(self):
self.baseUrl = 'https://www.xicidaili.com/nn/'
def getDataList(self, num=10):
print('爬取中...')
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36",
'Host': 'www.xicidaili.com',
'Referer': 'https://www.xicidaili.com/nn/'
}
totalList = []
ableList = []
unableList = []
page = 1
while len(ableList) <= num:
self.url = self.baseUrl + str(page)
req = requests.get(self.url, headers=headers)
html_doc = BeautifulSoup(req.text, 'html.parser')
lists = html_doc.select('#ip_list tr')[1:]
print('数据分析中,请稍等...')
for li in lists[1:]:
self.li = li
ip = self.getText(1) + ':' + self.getText(2)
obj = {
'ip': ip,
'address': self.getText(3),
'anonymous': self.getText(4),
'type': self.getText(5),
'date': self.getText(9)
}
totalList.append(obj)
try:
Telnet(self.getText(1), self.getText(2), timeout=1)
ableList.append(obj)
except:
unableList.append(obj)
page += 1
self.totalList = totalList
self.ableList = ableList
self.unableList = unableList
def getText(self, index):
return self.li.select('td')[index].text.strip()
def writeXls(self):
wb = xlwt.Workbook(encoding='ascii')
ws = wb.add_sheet('ip列表')
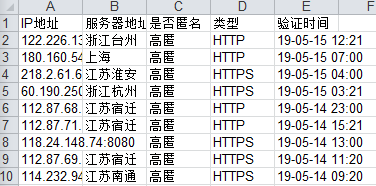
ws.write(0, 0, 'IP地址')
ws.write(0, 1, '服务器地址')
ws.write(0, 2, '是否匿名')
ws.write(0, 3, '类型')
ws.write(0, 4, '验证时间')
self.getDataList(60) # 60为可用数据的长度
print('爬取总数据{}条'.format(len(self.totalList)))
print('{}条可用'.format(len(self.ableList)))
print('{}条不可用'.format(len(self.unableList)))
for i, data in enumerate(self.ableList):
ws.write(i+1, 0, data['ip'])
ws.write(i+1, 1, data['address'])
ws.write(i+1, 2, data['anonymous'])
ws.write(i+1, 3, data['type'])
ws.write(i+1, 4, data['date'])
wb.save('西刺代理ip.xls')
print('录入西刺代理ip.xls-成功')
def readXls(self, index):
book = open_workbook('西刺代理ip.xls')
sheet = book.sheet_by_index(0)
row_con = sheet.row_values(index) # 行的操作
return row_con
if __name__ == '__main__':
xiciProxy = XiciProxy()
xiciProxy.writeXls()
1.http://www.cnblogs.com/zhaof/p/6953241.html
2.<selenium.common.exceptions.WebDriverException问题>
https://blog.youkuaiyun.com/ywj_486/article/details/80942191
https://www.cnblogs.com/wenchaoz/p/7875365.html
3.https://blog.youkuaiyun.com/weixin_42540746/article/details/88250781
4.构建代理池
https://www.cnblogs.com/captainwade/p/10808793.html
https://blog.youkuaiyun.com/qq_24504591/article/details/88124344


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









