




1.Spark on YARN (Client模式)
(1)概述:将Spark作业提交到yarn上去执行,Spark仅仅作为一个客户端。
(2)回顾yran的架构

阐述:客户端要提交一个yarn的作业,首先要通过Resource manager去申请一个container在node mananger上,用来跑application master,然后application master到resource manager拿到所需要的资源,通过application master和node manager进行交互启动container,在container里面运行task。 如果是map-reduce,task换成map task和reduce task,若果是spark换成spark作业就好,所以很多作业都能跑到yarn上面的。
(3)运行Spark官网案列

观察日志可以发现有些地方卡的时间较长例如下面这个:

(4)每次都要压缩这些包是很浪费时间的,可以将这个spark.yarn.jars包传到hdfs上去,然后再spark.default配置文件配一下。成功了就不会有这段信息。节约点时间。这就是yarn申请资源都需要花费几十秒的原因。打包需要时间,这对于离线来说是可以接受的,但对于要求高的来说是不能接受的。这个时候就需要将spark和为服务整合起来使用,将spark用Sping boot做成一个长服务让他24小时都跑着就好,然后同协议服务提交作业就好。
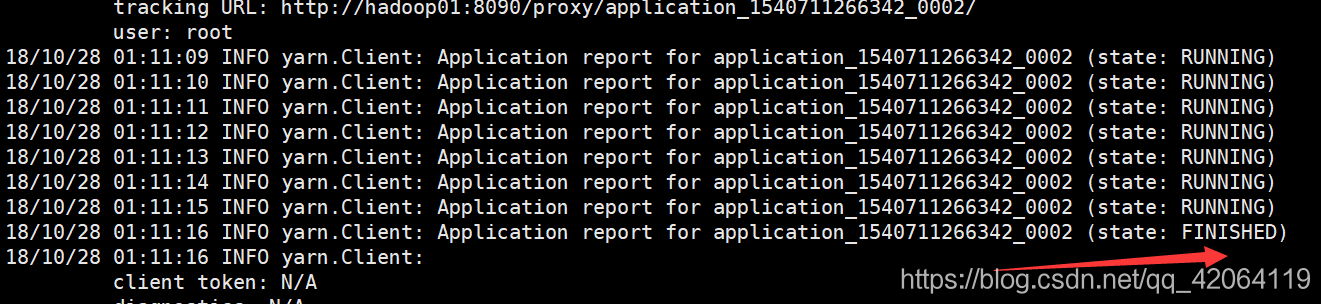
(5)面试题:YARN上的application作业有那些状态?
2.Spark on YARN (Cluster模式)
(1)Client模式和Cluster模式俩者有什么区别呢?
取决于Driver在哪里,在本机上的就是Client模式,在ApplicationMaster上就Cluster模式,如下图就是cluster模式,因为他的Driver(就是有SparkContext的那个)

然而yarn-cluster并不太适合交互式的Spark实用场景。需要用户输入,如spark-shell和PySpark,需要Spark Driver在启动应用程序的客户端进程中运行。在yarn-client模式中,master仅仅出现在向YARN申请executor container的过程中。客户端进程在containers启动之后,与它们进行通讯,调度任务。
(2)Client模式是能看到日志输出的,但是Cluster模式是看不到日志输出的,如下图
(3)所以需要配置日志监控,查看更多的信息:
在spark.env.sh添加:
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://192.168.137.251:9000/directory -Dspark.history.ui.port=7777"
//-D表示追加参数的意思,首先加入日志的存储路径,然后还还可以修改UI的端口,如果以后想修改其他的参数,要去spark 的monitor那找。
//注意点:在hadoop2的HDFS中fs.defaultFS在core-site.xml 中配置,默认端口是8020,但是由于其接收Client连接的RPC端口,所以如果在hdfs-site.xml中配置了RPC端口9000,所以fs.defaultFS端口变为9000
出现拒绝连接多半就是你的路径出了问题。
在spark-defaults.conf添加:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://192.168.137.251:9000/directory
//第一个参数表示的是默认情况下,此信息仅在应用程序期间可用。要查看web UI,请设置spark.eventLog。在启动应用程序之前启用true。这将使Spark记录对UI中显示的信息进行编码以持久化存储的Spark事件。(通俗来说就是要记录日志)
//第二个参数表示的是,日志的存储目录启动history-server:
$SPARK_HOME/sbin下:

Hadoop安全模式:hadoop dfsadmin -safemode leave/get/enter
这个时候提交的spark程序,即使跑完了,也可以在你的history-server里能看到日志信息。
(4)下面这些参数,表示定时清理这些日志文件,不然它会不断占hdfs的内存
| spark.history.fs.cleaner.enabled | false | Specifies whether the History Server should periodically clean up event logs from storage. |
| spark.history.fs.cleaner.interval | 1d | How often the filesystem job history cleaner checks for files to delete. Files are only deleted if they are older than spark.history.fs.cleaner.maxAge |
| spark.history.fs.cleaner.maxAge | 7d | Job history files older than this will be deleted when the filesystem history cleaner runs. |
3.基本API的讲解
(1)coalesce和reparation
coalesce:改变partition数量,一般用于减少partition数量(比如:当生成了200个task只需要,coalesce(1),就变成一个文件了)
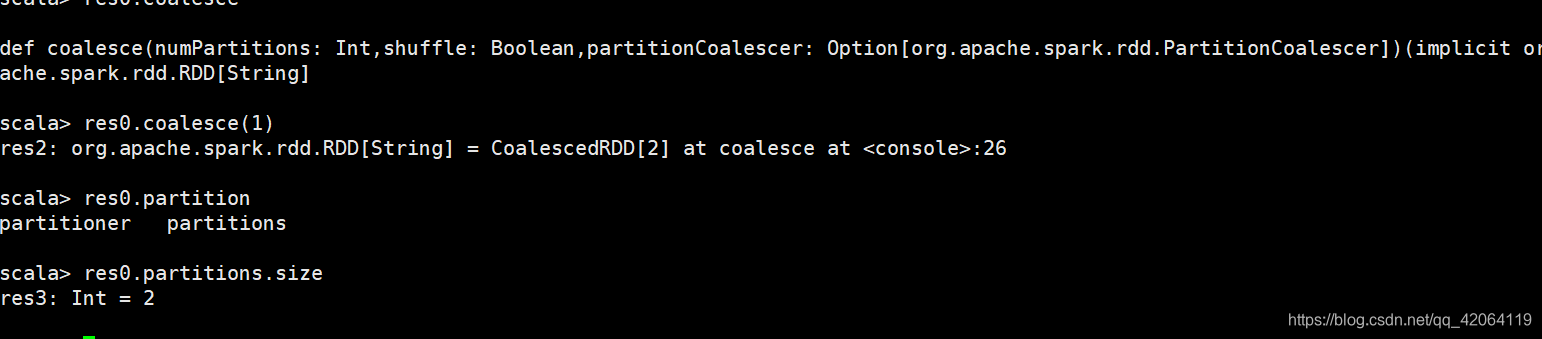
为什么这他的数量没变呢?因为RDD是不可变的啊!!!!所以需要重新创建一个。
Partition数量改大,需要加个true(一般不用,大都是多变少)

coalesce使用场景(小文件规避,会降低一定的性能):
200 200 200 200
RDD1 -MAP-> RDD2 -filter-> (coalesce) -->RDD3 ---->save ...
task在经过一系列变化之后保存出去了,但是如果filter过滤之后只剩下1条,但是前面读取的文件还是要存储的,所以这时候coalesce分区为1,就只有一个task存储出去了。在生产中你需要对你的task filter之后还剩下多少做个预估的。
reparation:他调用的就是coalesce,后面传入一个shuffle,他一般是少变多。
(2)map和mappartitions
map:作用于分区里面的每个元素,这个浪费IO
mappartitions:作用于每个partition上,这个是比较好的,节约IO。
(3)foreach和foreachpartition
在工作中,又输出的尽量选择foreachpartition,且他本身就是一个action

















 2689
2689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









